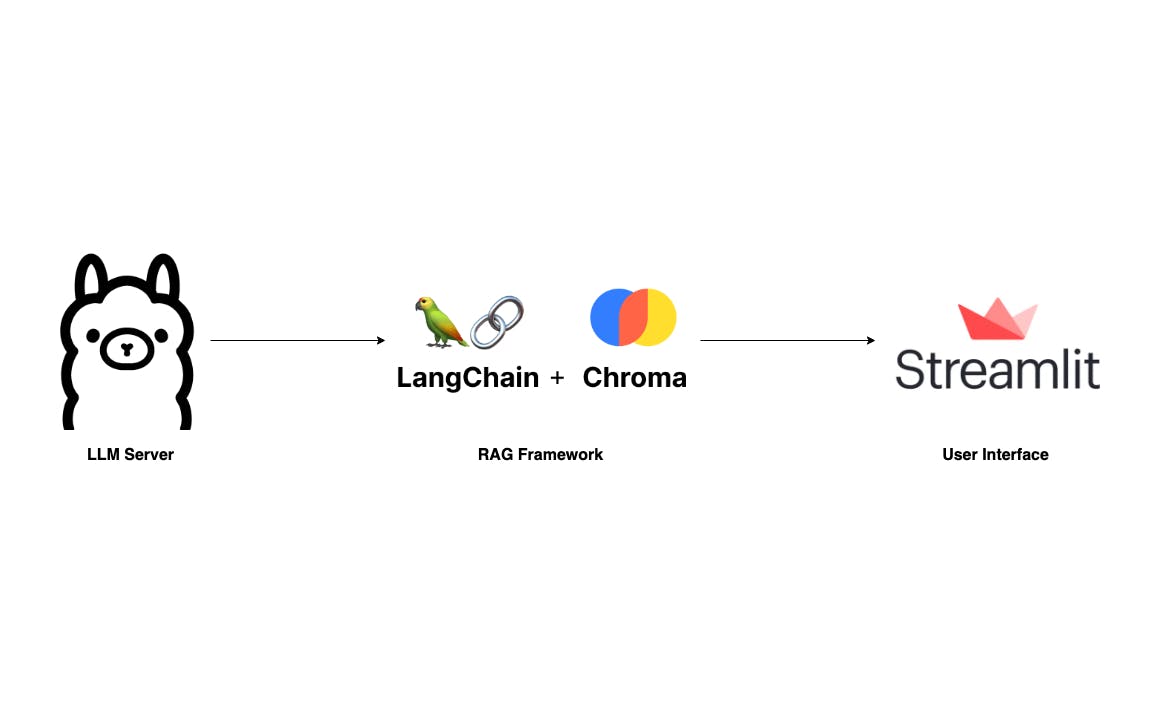
대규모 언어 모델과 그 인상적인 기능의 등장으로 OpenAI 및 Anthropic과 같은 거대 LLM 제공업체를 기반으로 많은 고급 애플리케이션이 구축되고 있습니다. 이러한 애플리케이션 뒤에 숨어 있는 신화는 RAG 프레임워크입니다. 이는 다음 문서에서 자세히 설명되어 있습니다. 프로덕션을 위한 RAG 기반 LLM 애플리케이션 구축 검색 증강 생성(RAG) 설명: 주요 개념 이해 검색증강세대란 무엇인가요? RAG에 익숙해지려면 다음 기사를 살펴보는 것이 좋습니다. 하지만 이 게시물에서는 기본 사항을 건너뛰고 데이터 개인 정보 보호 및 토큰 비용에 대한 걱정 없이 노트북에서 로컬로 실행할 수 있는 자체 RAG 애플리케이션을 구축하는 방법을 직접 안내합니다. F와 유사하지만 더 간단한 애플리케이션을 구축하겠습니다. 사용자가 PDF 문서를 업로드하고 간단한 UI를 통해 질문할 수 있는 곳입니다. 우리의 기술 스택은 Langchain, Ollama 및 Streamlit을 사용하여 매우 쉽습니다. ChatPD : 이 앱의 가장 중요한 구성 요소는 LLM 서버입니다. 덕분에 , 우리는 노트북에서도 로컬로 설정할 수 있는 강력한 LLM 서버를 보유하고 있습니다. 하는 동안 Go로 작성된 Ollama가 설정 및 실행이 더 쉽다는 것을 알았습니다. LLM 서버 올라마 라마.cpp : 의심할 여지 없이 LLM 도메인의 두 가지 주요 라이브러리는 다음과 같습니다. 그리고 . 이 프로젝트에서는 전문적인 경험을 통해 Langchain에 익숙하기 때문에 Langchain을 사용하겠습니다. RAG 프레임워크의 필수 구성 요소는 벡터 저장입니다. 우리는 사용할 것입니다 여기서는 Langchain과 잘 통합됩니다. RAG 랭체인 LLam인덱스 크로마 : 사용자 인터페이스도 중요한 구성 요소입니다. 사용할 수 있는 기술이 많지만 나는 다음을 선호합니다. , 마음의 평화를 위한 Python 라이브러리입니다. 채팅 UI 스트림라이트 좋아요, 설정을 시작해 보겠습니다. 올라마 설정 위에서 언급했듯이 Ollama를 설정하고 실행하는 것은 간단합니다. 먼저 방문하세요 그리고 운영체제에 맞는 앱을 다운로드하세요. ollama.ai 그런 다음 터미널을 열고 다음 명령을 실행하여 최신 파일을 가져옵니다. . 다른 많은 것들이 있는 반면 , 저는 컴팩트한 크기와 경쟁력 있는 품질 때문에 Mistral-7B를 선택했습니다. 미스트랄-7B LLM 모델 사용 가능 ollama pull mistral 그런 다음 실행하여 모델이 올바르게 당겨졌는지 확인합니다. 터미널 출력은 다음과 유사해야 합니다. ollama list 이제 LLM 서버가 아직 실행되고 있지 않으면 사용하여 시작하세요. 같은 오류 메시지가 표시되면 이는 기본적으로 서버가 이미 실행 중임을 나타내며 다음 단계로 진행할 수 있습니다. ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" RAG 파이프라인 구축 프로세스의 두 번째 단계는 RAG 파이프라인을 구축하는 것입니다. 애플리케이션의 단순성을 고려하면 주로 및 이라는 두 가지 방법이 필요합니다. ingest ask 방법은 파일 경로를 승인하고 이를 두 단계로 벡터 저장소에 로드합니다. 첫째, LLM의 토큰 제한을 수용하기 위해 문서를 더 작은 청크로 분할합니다. 둘째, Qdrant FastEmbeddings를 사용하여 이러한 청크를 벡터화하고 Chroma에 저장합니다. ingest 메소드는 사용자 쿼리를 처리합니다. 사용자가 질문을 하면 RetrievalQAChain은 벡터 유사성 검색 기술을 사용하여 관련 컨텍스트(문서 청크)를 검색합니다. ask 사용자의 질문과 검색된 컨텍스트를 사용하여 프롬프트를 구성하고 LLM 서버에 예측을 요청할 수 있습니다. from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None 프롬프트는 Langchain 허브에서 제공됩니다. . 이 프롬프트는 수천 번 테스트되고 다운로드되었으며 LLM 프롬프트 기술을 학습하기 위한 신뢰할 수 있는 리소스 역할을 합니다. Mistral에 대한 Langchain RAG 프롬프트 LLM 프롬프트 기술에 대해 자세히 알아볼 수 있습니다. . 여기 구현에 대한 자세한 내용은 다음과 같습니다. : PyPDFLoader를 사용하여 사용자가 업로드한 PDF 파일을 로드합니다. Langchain에서 제공하는 RecursiveCharacterSplitter는 이 PDF를 더 작은 덩어리로 분할합니다. Langchain의 함수를 사용하여 ChromaDB에서 지원하지 않는 복잡한 메타데이터를 필터링하는 것이 중요합니다. ingest filter_complex_metadata 벡터 저장을 위해 Chroma가 사용됩니다. 임베딩 모델로 사용합니다. 그런 다음 이 경량 모델은 점수 임계값이 0.5이고 k=3인 검색기로 변환됩니다. 즉, 가장 높은 점수가 0.5를 넘는 상위 3개 청크를 반환합니다. 마지막으로 다음을 사용하여 간단한 대화 체인을 구성합니다. . Qdrant FastEmbed LECL : 이 메서드는 단순히 사용자의 질문을 미리 정의된 체인에 전달한 다음 결과를 반환합니다. ask : 새 PDF 파일을 업로드할 때 이전 채팅 세션과 저장 공간을 지우는 데 사용되는 방법입니다. clear 간단한 UI 초안 작성 간단한 사용자 인터페이스를 위해 다음을 사용합니다. , AI/ML 애플리케이션의 빠른 프로토타이핑을 위해 설계된 UI 프레임워크입니다. 스트림라이트 import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() 명령으로 이 코드를 실행하여 어떻게 보이는지 확인하세요. streamlit run app.py 알았어, 그게 다야! 이제 귀하의 노트북에서 완전히 실행되는 ChatPDF 응용 프로그램이 생겼습니다. 이 게시물은 주로 자신만의 RAG 애플리케이션을 구축하는 방법에 대한 높은 수준의 개요를 제공하는 데 중점을 두기 때문에 미세 조정이 필요한 몇 가지 측면이 있습니다. 앱을 향상하고 기술을 더욱 발전시키기 위해 다음 제안 사항을 고려할 수 있습니다. : 현재는 대화 흐름을 기억하지 않습니다. 임시 메모리를 추가하면 어시스턴트가 상황을 인식하는 데 도움이 됩니다. 대화 체인에 메모리 추가 : 한 번에 하나의 문서에 대해 채팅해도 괜찮습니다. 하지만 우리가 여러 문서에 대해 이야기할 수 있다면 책장 전체를 거기에 넣을 수 있다고 상상해 보세요. 정말 멋지겠네요! 여러 파일 업로드 허용 : Mistral이 효과적이지만 다른 대안도 많이 있습니다. 개발자를 위한 LlamaCode와 같이 귀하의 요구 사항에 더 잘 맞는 모델을 찾을 수도 있습니다. 그러나 모델 선택은 하드웨어, 특히 RAM 용량에 따라 다르다는 점을 기억하세요 💵 다른 LLM 모델 사용 : RAG 내에서 실험할 여지가 있습니다. 검색 지표, 임베딩 모델을 변경하거나 순위 재지정과 같은 레이어를 추가하여 결과를 개선할 수 있습니다. RAG 파이프라인 강화 마지막으로 읽어주셔서 감사합니다. 이 정보가 유용하다고 생각되면 내 구독을 고려해 보세요. 아니면 내 개인적인 . 저는 RAG 및 LLM 지원에 관해 더 많은 글을 쓸 계획이며, 아래에 댓글을 남겨 주제를 제안해 주시면 감사하겠습니다. 건배! 서브스택 블로그 전체 소스 코드: https://github.com/vndee/local-rag-example