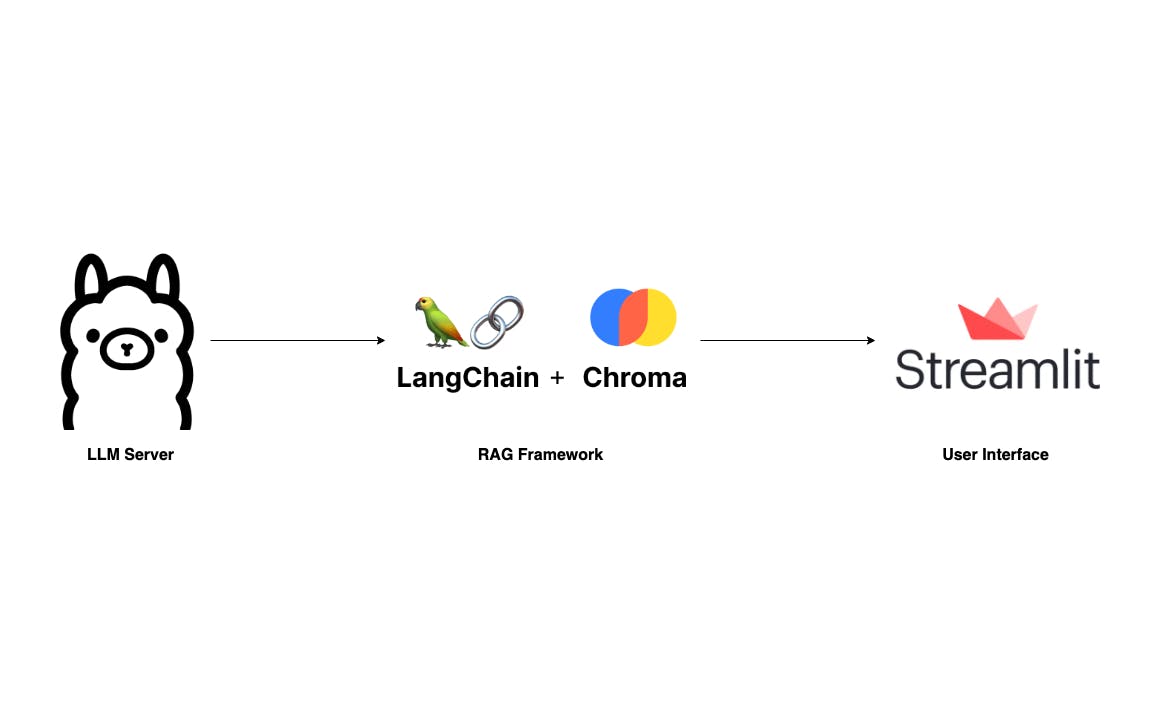
随着大型语言模型的兴起及其令人印象深刻的功能,许多精美的应用程序正在 OpenAI 和 Anthropic 等大型 LLM 提供商的基础上构建。此类应用程序背后的神话是 RAG 框架,以下文章对此进行了彻底解释: 构建基于 RAG 的 LLM 生产应用程序 检索增强生成 (RAG) 解释:理解关键概念 什么是检索增强生成? 要熟悉 RAG,我建议阅读这些文章。然而,这篇文章将跳过基础知识,直接指导您构建自己的 RAG 应用程序,该应用程序可以在您的笔记本电脑上本地运行,而无需担心数据隐私和令牌成本。 我们将构建一个与 F 类似但更简单的应用程序。用户可以上传 PDF 文档并通过简单的 UI 提问。使用 Langchain、Ollama 和 Streamlit,我们的技术堆栈非常简单。 ChatPD :这个应用程序最关键的组件是LLM服务器。谢谢 ,我们有一个强大的 LLM 服务器,可以在本地设置,甚至可以在笔记本电脑上设置。尽管 是一个选项,我发现 Ollama 用 Go 编写,更容易设置和运行。 LLM服务器 奥拉玛 骆驼.cpp :毫无疑问,LLM 领域的两个领先图书馆是 和 。对于这个项目,我将使用 Langchain,因为我的专业经验对它很熟悉。任何 RAG 框架的一个重要组成部分是矢量存储。我们将使用 在这里,因为它与 Langchain 集成得很好。 RAG 朗查恩 法学硕士索引 色度 :用户界面也是一个重要的组成部分。虽然有很多可用的技术,但我更喜欢使用 ,一个 Python 库,让您高枕无忧。 聊天UI 流线型 好的,让我们开始设置吧。 设置奥拉玛 如上所述,设置和运行 Ollama 非常简单。首先,访问 并下载适合您操作系统的应用程序。 奥拉马.ai 接下来,打开终端,然后执行以下命令来提取最新的 。虽然还有很多其他 ,我选择 Mistral-7B 是因为它紧凑的尺寸和有竞争力的质量。 米斯特拉尔-7B 提供法学硕士模型 ollama pull mistral 然后,运行 来验证模型是否已正确拉取。终端输出应类似于以下内容: ollama list 现在,如果 LLM 服务器尚未运行,请使用 启动它。如果遇到类似 错误信息,则说明服务器已经默认运行,可以继续下一步。 ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" 构建 RAG 管道 我们流程的第二步是构建 RAG 管道。考虑到我们的应用程序的简单性,我们主要需要两种方法: 和 。 ingest ask 方法接受文件路径并分两步将其加载到向量存储中:首先,它将文档分割成更小的块以适应LLM的令牌限制;其次,它使用 Qdrant FastEmbeddings 对这些块进行矢量化并将其存储到 Chroma 中。 ingest 方法处理用户查询。用户可以提出问题,然后 RetrievalQAChain 使用向量相似性搜索技术检索相关上下文(文档块)。 ask 根据用户的问题和检索到的上下文,我们可以编写提示并向 LLM 服务器请求预测。 from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None 该提示来自Langchain hub: 。该提示已经过数千次测试和下载,是学习 LLM 提示技术的可靠资源。 Langchain RAG 提示米斯特拉尔 您可以了解更多关于LLM提示技巧 。 这里 有关实施的更多详细信息: :我们使用 PyPDFLoader 加载用户上传的 PDF 文件。 Langchain 提供的 RecursiveCharacterSplitter 然后将此 PDF 分割成更小的块。使用 Langchain 的 函数过滤掉 ChromaDB 不支持的复杂元数据非常重要。 ingest filter_complex_metadata 对于向量存储,使用 Chroma 并结合 作为我们的嵌入模型。然后,这个轻量级模型被转换为一个分数阈值为 0.5 且 k=3 的检索器,这意味着它返回最高分数高于 0.5 的前 3 个块。最后,我们使用以下方法构建一个简单的对话链 。 Qdrant FastEmbed LECL :该方法只是将用户的问题传递到我们预定义的链中,然后返回结果。 ask :此方法用于在上传新的 PDF 文件时清除之前的聊天会话和存储。 clear 起草一个简单的 UI 对于简单的用户界面,我们将使用 ,一个专为 AI/ML 应用程序的快速原型设计而设计的 UI 框架。 流线型 import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() 使用命令 运行此代码以查看其外观。 streamlit run app.py 好吧,就是这样!我们现在拥有一个完全在您的笔记本电脑上运行的 ChatPDF 应用程序。由于本文主要侧重于提供如何构建自己的 RAG 应用程序的高级概述,因此有几个方面需要微调。您可以考虑以下建议来增强您的应用程序并进一步发展您的技能: :目前,它不记得对话流程。添加临时记忆将帮助您的助手了解上下文。 将记忆添加到对话链 :可以一次讨论一个文档。但想象一下,如果我们可以讨论多个文档——你可以把整个书架放在那里。那真是太酷了! 允许多个文件上传 :虽然 Mistral 很有效,但还有许多其他替代方案可用。您可能会找到更适合您需求的模型,例如面向开发人员的 LlamaCode。但是,请记住,型号的选择取决于您的硬件,尤其是您拥有的 RAM 量 💵 使用其他 LLM 模型 :RAG 内有实验空间。您可能想要更改检索指标、嵌入模型……或添加重新排序器等层以改进结果。 增强 RAG 管道 最后,感谢您的阅读。如果您觉得此信息有用,请考虑订阅我的 或我个人的 。我计划写更多关于 RAG 和 LLM 申请的文章,欢迎您在下面留下评论来建议主题。干杯! 子栈 博客 完整源代码: https://github.com/vndee/local-rag-example