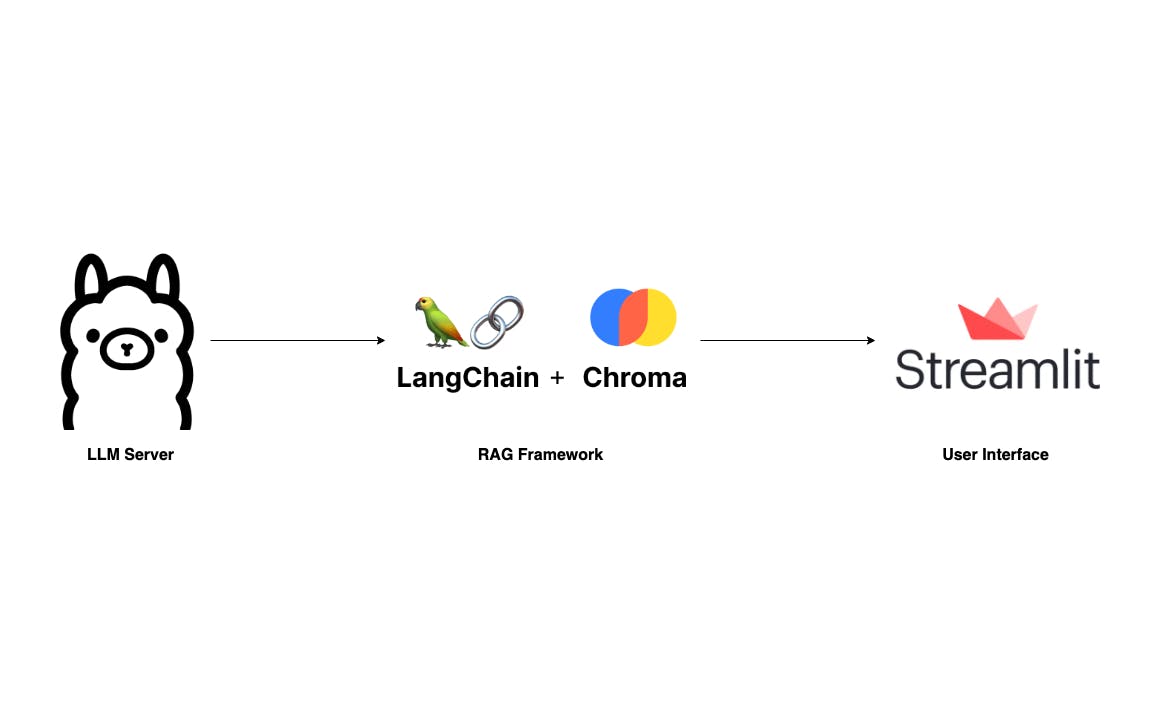
Con el auge de los modelos de lenguajes grandes y sus impresionantes capacidades, se están creando muchas aplicaciones sofisticadas sobre proveedores gigantes de LLM como OpenAI y Anthropic. El mito detrás de tales aplicaciones es el marco RAG, que se explica detalladamente en los siguientes artículos: Creación de aplicaciones LLM basadas en RAG para producción Explicación de la generación aumentada de recuperación (RAG): comprensión de los conceptos clave ¿Qué es la generación de recuperación aumentada? Para familiarizarse con RAG, recomiendo leer estos artículos. Sin embargo, esta publicación omitirá los conceptos básicos y lo guiará directamente en la creación de su propia aplicación RAG que pueda ejecutarse localmente en su computadora portátil sin preocuparse por la privacidad de los datos y el costo de los tokens. Construiremos una aplicación similar a F pero más simple. Donde los usuarios pueden cargar un documento PDF y hacer preguntas a través de una interfaz de usuario sencilla. Nuestra pila tecnológica es muy sencilla con Langchain, Ollama y Streamlit. ChatPD : el componente más crítico de esta aplicación es el servidor LLM. Gracias a , tenemos un servidor LLM robusto que se puede configurar localmente, incluso en una computadora portátil. Mientras es una opción, encuentro que Ollama, escrito en Go, es más fácil de configurar y ejecutar. Servidor LLM Ollama llama.cpp : Sin lugar a dudas, las dos bibliotecas líderes en el dominio LLM son y . Para este proyecto, usaré Langchain debido a que estoy familiarizado con él por mi experiencia profesional. Un componente esencial de cualquier marco RAG es el almacenamiento vectorial. estaremos usando aquí, ya que se integra bien con Langchain. RAG Cadena Lang LLamIndex croma : la interfaz de usuario también es un componente importante. Aunque hay muchas tecnologías disponibles, prefiero usar , una biblioteca de Python, para su tranquilidad. UI de chat iluminado Bien, comencemos a configurarlo. Configurar Ollama Como se mencionó anteriormente, configurar y ejecutar Ollama es sencillo. Primera visita y descargue la aplicación adecuada para su sistema operativo. ollama.ai A continuación, abra su terminal y ejecute el siguiente comando para obtener la última versión . Si bien hay muchos otros Elijo Mistral-7B por su tamaño compacto y calidad competitiva. Mistral-7B Modelos LLM disponibles ollama pull mistral Luego, ejecute para verificar si el modelo se extrajo correctamente. La salida del terminal debería parecerse a la siguiente: ollama list Ahora, si el servidor LLM aún no se está ejecutando, inícielo con . Si encuentra un mensaje de error como , indica que el servidor ya se está ejecutando de forma predeterminada y puede continuar con el siguiente paso. ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" Construya el oleoducto RAG El segundo paso de nuestro proceso es construir el oleoducto RAG. Dada la simplicidad de nuestra aplicación, necesitamos principalmente dos métodos: y . ingest ask El método acepta una ruta de archivo y la carga en un almacenamiento vectorial en dos pasos: primero, divide el documento en fragmentos más pequeños para acomodar el límite de token del LLM; en segundo lugar, vectoriza estos fragmentos utilizando Qdrant FastEmbeddings y los almacena en Chroma. ingest El método maneja las consultas de los usuarios. Los usuarios pueden plantear una pregunta y luego RetrievalQAChain recupera los contextos relevantes (fragmentos de documentos) utilizando técnicas de búsqueda por similitud de vectores. ask Con la pregunta del usuario y los contextos recuperados, podemos redactar un mensaje y solicitar una predicción del servidor LLM. from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None El mensaje proviene del centro Langchain: . Este mensaje se ha probado y descargado miles de veces y sirve como un recurso confiable para aprender sobre las técnicas de mensajes de LLM. Langchain RAG solicita Mistral Puede obtener más información sobre las técnicas de estimulación de LLM. . aquí Más detalles sobre la implementación: : Usamos PyPDFLoader para cargar el archivo PDF cargado por el usuario. El RecursiveCharacterSplitter, proporcionado por Langchain, luego divide este PDF en partes más pequeñas. Es importante filtrar metadatos complejos que no son compatibles con ChromaDB utilizando la función de Langchain. ingest filter_complex_metadata Para el almacenamiento de vectores, se utiliza Chroma, junto con como nuestro modelo de incrustación. Este modelo liviano luego se transforma en un perro perdiguero con un umbral de puntuación de 0,5 y k=3, lo que significa que devuelve los 3 fragmentos principales con las puntuaciones más altas por encima de 0,5. Finalmente, construimos una cadena de conversación simple usando . Qdrant FastEmbed LECL : este método simplemente pasa la pregunta del usuario a nuestra cadena predefinida y luego devuelve el resultado. ask : este método se utiliza para borrar la sesión de chat anterior y el almacenamiento cuando se carga un nuevo archivo PDF. clear Borre una interfaz de usuario simple Para una interfaz de usuario simple, usaremos , un marco de interfaz de usuario diseñado para la creación rápida de prototipos de aplicaciones de IA/ML. iluminado import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() Ejecute este código con el comando para ver cómo se ve. streamlit run app.py ¡Está bien, eso es todo! Ahora tenemos una aplicación ChatPDF que se ejecuta completamente en su computadora portátil. Dado que esta publicación se centra principalmente en brindar una descripción general de alto nivel sobre cómo crear su propia aplicación RAG, hay varios aspectos que necesitan ajustes. Puede considerar las siguientes sugerencias para mejorar su aplicación y desarrollar aún más sus habilidades: : actualmente, no recuerda el flujo de la conversación. Agregar memoria temporal ayudará a su asistente a ser consciente del contexto. Agregar memoria a la cadena de conversación : está bien conversar sobre un documento a la vez. Pero imagina si pudiéramos conversar sobre varios documentos: podrías poner toda tu estantería allí. ¡Eso sería genial! Permitir la carga de múltiples archivos : si bien Mistral es eficaz, existen muchas otras alternativas disponibles. Quizás encuentres un modelo que se adapte mejor a tus necesidades, como LlamaCode para desarrolladores. Sin embargo, recuerda que la elección del modelo depende de tu hardware, especialmente de la cantidad de RAM que tengas 💵 Utilice otros modelos LLM : hay espacio para la experimentación dentro de RAG. Es posible que desee cambiar la métrica de recuperación, el modelo de incrustación... o agregar capas como un reclasificador para mejorar los resultados. Mejorar el proceso de RAG Finalmente, gracias por leer. Si encuentra útil esta información, considere suscribirse a mi o mi personal . Planeo escribir más sobre las aplicaciones RAG y LLM, y puedes sugerir temas dejando un comentario a continuación. ¡Salud! Subpila Blog Código fuente completo: https://github.com/vndee/local-rag-example