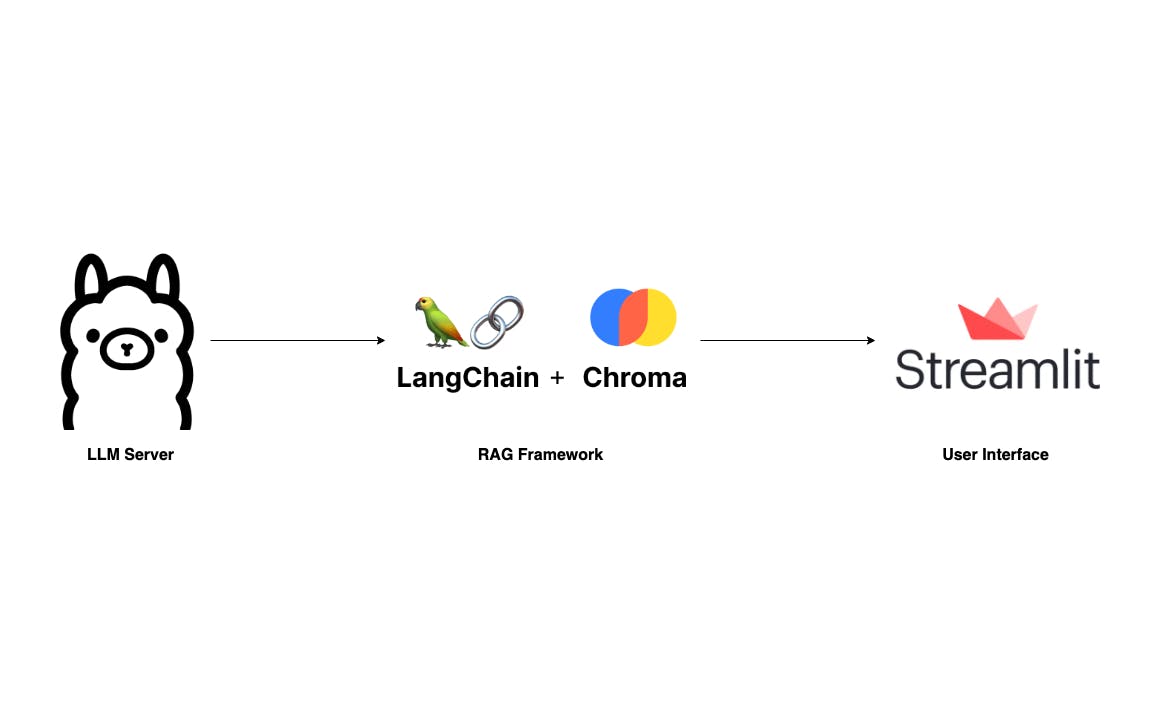
大規模言語モデルとその優れた機能の台頭により、多くの高度なアプリケーションが OpenAI や Anthropic などの巨大な LLM プロバイダー上に構築されています。このようなアプリケーションの背後にある神話は RAG フレームワークです。これについては、次の記事で詳しく説明しています。 実稼働用の RAG ベースの LLM アプリケーションの構築 検索拡張生成 (RAG) の説明: 重要な概念を理解する 検索拡張生成とは何ですか? RAG に慣れるために、これらの記事に目を通すことをお勧めします。ただし、この投稿では基本的な部分は省略し、データ プライバシーやトークン コストを心配することなくラップトップ上でローカルに実行できる独自の RAG アプリケーションを構築する方法を直接説明します。 F に似ていますが、より単純なアプリケーションを構築します。ユーザーは PDF ドキュメントをアップロードし、わかりやすい UI を通じて質問できます。私たちの技術スタックは、Langchain、Ollama、Streamlit を使用することで非常に簡単になります。 ChatPD : このアプリの最も重要なコンポーネントは LLM サーバーです。おかげで 、ラップトップ上でもローカルにセットアップできる堅牢な LLM サーバーがあります。その間 はオプションですが、Go で書かれた Ollama の方がセットアップと実行が簡単だと思います。 LLM サーバー オラマ ラマ.cpp : 間違いなく、LLM ドメインの 2 つの主要なライブラリは次のとおりです。 そして 。このプロジェクトでは、職業上の経験から Langchain に精通しているため、Langchain を使用します。 RAG フレームワークの重要なコンポーネントは、ベクター ストレージです。使用します Langchain とうまく統合されているため、ここで説明します。 RAG ラングチェーン LlamIndex 彩度 : ユーザー インターフェイスも重要なコンポーネントです。利用可能なテクノロジーはたくさんありますが、私は使用することを好みます Python ライブラリなので安心です。 チャット UI ストリームライト さて、設定を始めましょう。 オラマのセットアップ 上で述べたように、Ollama のセットアップと実行は簡単です。まずは訪問 オペレーティング システムに適したアプリをダウンロードします。 オラマ・アイ 次に、ターミナルを開き、次のコマンドを実行して最新のファイルを取得します。 。他にもたくさんある中、 , 私はコンパクトなサイズと競争力のある品質のためにMistral-7Bを選びました。 ミストラル-7B LLM モデルが利用可能 ollama pull mistral その後、 を実行して、モデルが正しくプルされたかどうかを確認します。端末出力は次のようになります。 ollama list ここで、LLM サーバーがまだ実行されていない場合は、 して開始します。 のようなエラー メッセージが表示された場合は、サーバーがデフォルトですでに実行されていることを示しており、次の手順に進むことができます。 ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" RAG パイプラインを構築する プロセスの 2 番目のステップは、RAG パイプラインを構築することです。アプリケーションが単純であることを考えると、主に 2 つのメソッドが必要です: と です。 ingest ask メソッドはファイル パスを受け取り、それを 2 つのステップでベクトル ストレージにロードします。まず、LLM のトークン制限に対応するためにドキュメントを小さなチャンクに分割します。次に、Qdrant FastEmbeddings を使用してこれらのチャンクをベクトル化し、Chroma に保存します。 ingest メソッドはユーザーのクエリを処理します。ユーザーが質問をすると、RetrievalQAChain はベクトル類似性検索手法を使用して関連するコンテキスト (ドキュメント チャンク) を取得します。 ask ユーザーの質問と取得したコンテキストを使用して、プロンプトを作成し、LLM サーバーに予測を要求できます。 from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None プロンプトは、Langchain ハブから取得されます。 。このプロンプトは何千回もテストおよびダウンロードされており、LLM プロンプト手法を学習するための信頼できるリソースとして機能します。 ミストラルの Langchain RAG プロンプト LLM プロンプト手法について詳しく学ぶことができます 。 ここ 実装の詳細: : PyPDFLoader を使用して、ユーザーがアップロードした PDF ファイルを読み込みます。 Langchain によって提供される RecursiveCharacterSplitter は、この PDF をより小さなチャンクに分割します。 Langchain の 関数を使用して、ChromaDB でサポートされていない複雑なメタデータを除外することが重要です。 ingest filter_complex_metadata ベクトルの保存には、Chroma が使用されます。 埋め込みモデルとして。この軽量モデルは、スコアしきい値が 0.5 で k=3 のリトリーバーに変換されます。これは、0.5 を超える最高スコアを持つ上位 3 つのチャンクを返すことを意味します。最後に、次を使用して単純な会話チェーンを構築します。 。 Qdrant FastEmbed レケル : このメソッドは単にユーザーの質問を事前定義されたチェーンに渡し、結果を返します。 ask : このメソッドは、新しい PDF ファイルがアップロードされたときに、以前のチャット セッションとストレージをクリアするために使用されます。 clear シンプルな UI を作成する 単純なユーザー インターフェイスの場合は、次を使用します。 、AI/ML アプリケーションの高速プロトタイピングのために設計された UI フレームワーク。 ストリームライト import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() コマンド を使用してこのコードを実行し、どのようになるかを確認します。 streamlit run app.py はい、以上です!これで、ラップトップ上で完全に実行できる ChatPDF アプリケーションが完成しました。この投稿は主に、独自の RAG アプリケーションを構築する方法の概要を提供することに重点を置いているため、微調整が必要な側面がいくつかあります。アプリを強化し、スキルをさらに伸ばすために、次の提案を検討してください。 : 現在、会話の流れを記憶していません。一時メモリを追加すると、アシスタントがコンテキストを認識しやすくなります。 会話チェーンにメモリを追加する : 一度に 1 つのドキュメントについてチャットすることは問題ありません。しかし、複数のドキュメントについてチャットできるとしたら、本棚全体をそこに置くことができると想像してください。それはとてもクールですね! 複数のファイルのアップロードを許可する : Mistral は効果的ですが、他にも多くの代替手段が利用可能です。開発者向けの LlamaCode など、ニーズにより適したモデルが見つかるかもしれません。ただし、モデルの選択はハードウェア、特に搭載している RAM の量に依存することに注意してください 💵 他の LLM モデルを使用する : RAG 内には実験の余地があります。結果を改善するには、取得メトリクス、埋め込みモデルなどを変更したり、再ランカーなどのレイヤーを追加したりすることが必要になる場合があります。 RAG パイプラインの強化 最後に、読んでいただきありがとうございます。この情報が役立つと思われる場合は、購読を検討してください。 または私の個人的な 。 RAG および LLM アプリケーションについてさらに詳しく書く予定です。以下にコメントを残してトピックを提案していただければ幸いです。乾杯! サブスタック ブログ 完全なソースコード: https://github.com/vndee/local-rag-example