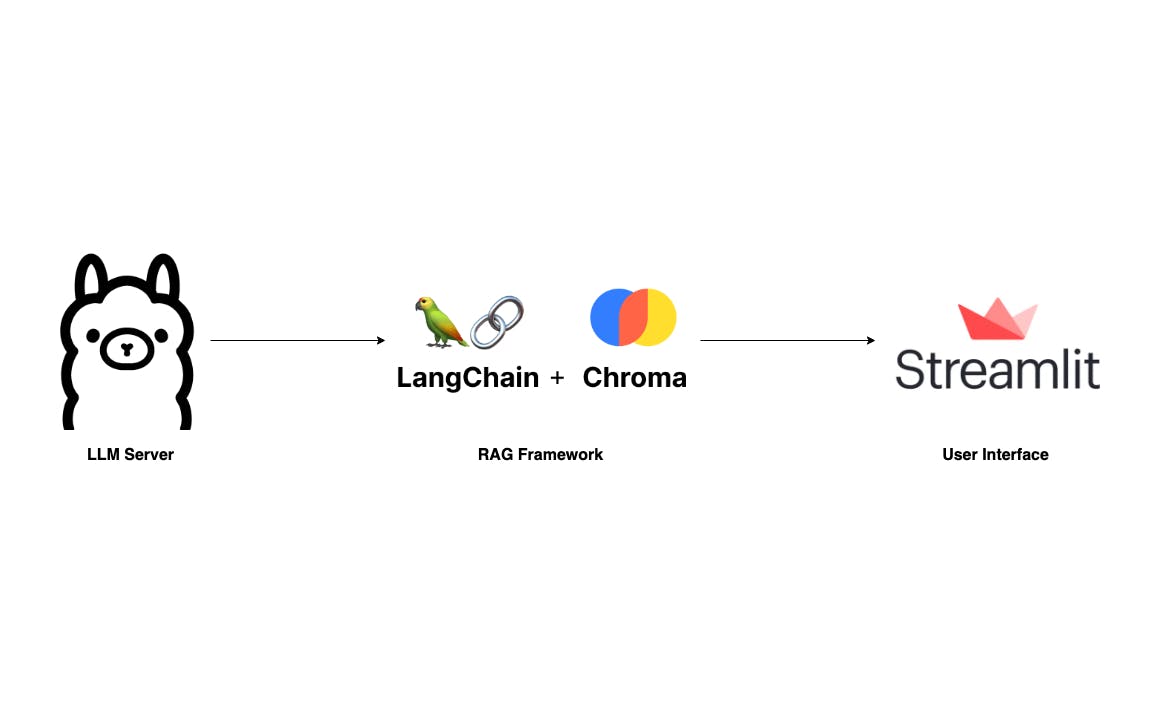
Büyük Dil Modellerinin yükselişi ve etkileyici yetenekleriyle birlikte, OpenAI ve Anthropic gibi dev LLM sağlayıcılarının üzerine birçok süslü uygulama inşa ediliyor. Bu tür uygulamaların arkasındaki efsane, aşağıdaki makalelerde ayrıntılı olarak açıklanan RAG çerçevesidir: Üretim için RAG tabanlı Yüksek Lisans Uygulamaları Oluşturma Erişim Artırılmış Nesil (RAG) Açıklaması: Temel Kavramları Anlamak Geri almayla artırılmış nesil nedir? RAG'a aşina olmak için bu makalelere göz atmanızı öneririm. Ancak bu yazı, temel bilgileri atlayacak ve veri gizliliği ve belirteç maliyeti konusunda herhangi bir endişe duymadan dizüstü bilgisayarınızda yerel olarak çalışabilen kendi RAG uygulamanızı oluşturma konusunda size doğrudan rehberlik edecektir. F'ye benzer fakat daha basit bir uygulama geliştireceğiz. Kullanıcıların basit bir kullanıcı arayüzü aracılığıyla bir PDF belgesi yükleyebileceği ve soru sorabileceği yer. Langchain, Ollama ve Streamlit ile teknoloji yığınımız son derece kolaydır. ChatPD : Bu uygulamanın en kritik bileşeni LLM sunucusudur. Sayesinde , bir dizüstü bilgisayarda bile yerel olarak kurulabilen sağlam bir LLM Sunucumuz var. Sırasında Bu bir seçenek, Go'da yazılan Ollama'nın kurulumunun ve çalıştırılmasının daha kolay olduğunu düşünüyorum. LLM Sunucusu Ollama lama.cpp : Şüphesiz LLM alanında önde gelen iki kütüphane Ve . Bu proje için, mesleki tecrübelerimden dolayı Langchain'e aşina olduğum için kullanacağım. Herhangi bir RAG çerçevesinin önemli bir bileşeni vektör depolamadır. Kullanıyor olacağız Langchain ile iyi entegre olduğu için burada. RAG Uzun zincir LLamIndex Renk : Kullanıcı arayüzü de önemli bir bileşendir. Birçok teknoloji olmasına rağmen kullanmayı tercih ediyorum İçiniz rahat olsun diye bir Python kütüphanesi. Sohbet Arayüzü Kolaylaştırılmış Tamam, ayarlamaya başlayalım. Ollama'yı kur Yukarıda belirtildiği gibi Ollama'yı kurmak ve çalıştırmak basittir. İlk ziyaret ve işletim sisteminize uygun uygulamayı indirin. ollama.ai Daha sonra terminalinizi açın ve en son sürümü almak için aşağıdaki komutu uygulayın. . Daha birçokları varken Kompakt boyutu ve rekabetçi kalitesi nedeniyle Mistral-7B'yi seçiyorum. Mistral-7B LLM modelleri mevcut ollama pull mistral Daha sonra modelin doğru şekilde çekilip çekilmediğini doğrulamak için çalıştırın. Terminal çıkışı aşağıdakine benzemelidir: ollama list Şimdi, eğer LLM sunucusu halihazırda çalışmıyorsa, onu ile başlatın. gibi bir hata mesajıyla karşılaşırsanız bu, sunucunun zaten varsayılan olarak çalıştığını gösterir ve bir sonraki adıma geçebilirsiniz. ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" RAG Boru Hattını İnşa Edin Sürecimizdeki ikinci adım RAG boru hattını inşa etmektir. Uygulamamızın basitliği göz önüne alındığında öncelikle iki yönteme ihtiyacımız var: ve . ingest ask yöntemi bir dosya yolunu kabul eder ve bunu iki adımda vektör depolama alanına yükler: ilk olarak, LLM'nin belirteç sınırına uyum sağlamak için belgeyi daha küçük parçalara böler; ikincisi, Qdrant FastEmbeddings'i kullanarak bu parçaları vektörleştirir ve Chroma'da saklar. ingest yöntemi kullanıcı sorgularını yönetir. Kullanıcılar bir soru sorabilir ve ardından RetrievalQAChain, vektör benzerliği arama tekniklerini kullanarak ilgili bağlamları (belge parçaları) alır. ask Kullanıcının sorusu ve alınan bağlamlarla bir istem oluşturabilir ve LLM sunucusundan bir tahmin talep edebiliriz. from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None Bilgi istemi Langchain merkezinden alınmıştır: . Bu bilgi istemi binlerce kez test edilmiş ve indirilmiştir; LLM yönlendirme teknikleri hakkında bilgi edinmek için güvenilir bir kaynak olarak hizmet vermektedir. Mistral için Langchain RAG İstemi Yüksek Lisans yönlendirme teknikleri hakkında daha fazla bilgi edinebilirsiniz . Burada Uygulamaya ilişkin daha fazla ayrıntı: : Kullanıcı tarafından yüklenen PDF dosyasını yüklemek için PyPDFLoader kullanıyoruz. Langchain tarafından sağlanan RecursiveCharacterSplitter daha sonra bu PDF'yi daha küçük parçalara böler. Langchain'in işlevini kullanarak ChromaDB tarafından desteklenmeyen karmaşık meta verileri filtrelemek önemlidir. ingest filter_complex_metadata Vektör depolama için Chroma ile birlikte kullanılır yerleştirme modelimiz olarak. Bu hafif model daha sonra 0,5 ve k=3 puan eşiğine sahip bir av köpeğine dönüştürülür, yani 0,5'in üzerinde en yüksek puanlara sahip ilk 3 parçayı döndürür. Son olarak, kullanarak basit bir konuşma zinciri oluşturuyoruz. . Qdrant FastEmbed LECL : Bu yöntem kullanıcının sorusunu önceden tanımlanmış zincirimize iletir ve ardından sonucu döndürür. ask : Bu yöntem, yeni bir PDF dosyası yüklendiğinde önceki sohbet oturumunu ve depolama alanını temizlemek için kullanılır. clear Basit Bir Kullanıcı Arayüzü Taslağı Basit bir kullanıcı arayüzü için kullanacağız AI/ML uygulamalarının hızlı prototiplenmesi için tasarlanmış bir kullanıcı arayüzü çerçevesi. Kolaylaştırılmış import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() Nasıl göründüğünü görmek için bu kodu komutuyla çalıştırın. streamlit run app.py Tamam, işte bu! Artık tamamen dizüstü bilgisayarınızda çalışan bir ChatPDF uygulamamız var. Bu yazı esas olarak kendi RAG uygulamanızı nasıl oluşturacağınıza dair üst düzey bir genel bakış sağlamaya odaklandığından, ince ayar yapılması gereken çeşitli yönler vardır. Uygulamanızı geliştirmek ve becerilerinizi daha da geliştirmek için aşağıdaki önerileri dikkate alabilirsiniz: : Şu anda konuşma akışını hatırlamıyor. Geçici hafıza eklemek asistanınızın bağlamdan haberdar olmasına yardımcı olacaktır. Konuşma Zincirine Bellek Ekleme : Aynı anda tek bir belge hakkında sohbet etmek sorun değildir. Ancak birden fazla belge hakkında sohbet edebildiğimizi hayal edin; tüm kitaplığınızı oraya koyabilirsiniz. Bu çok havalı olurdu! Birden fazla dosya yüklemeye izin ver : Mistral etkili olsa da, başka birçok alternatif de mevcuttur. Geliştiriciler için LlamaCode gibi ihtiyaçlarınıza daha iyi uyan bir model bulabilirsiniz. Ancak model seçiminin donanımınıza, özellikle de sahip olduğunuz RAM miktarına bağlı olduğunu unutmayın 💵 Diğer LLM Modellerini Kullanın : RAG içinde denemeler için yer var. Sonuçları iyileştirmek için alma metriğini, yerleştirme modelini değiştirmek veya yeniden sıralama gibi katmanlar eklemek isteyebilirsiniz. RAG Pipeline'ı geliştirin Son olarak okuduğunuz için teşekkür ederim. Bu bilgiyi yararlı bulursanız, lütfen abone olmayı düşünün. veya benim kişisel . RAG ve LLM uygulamaları hakkında daha fazla yazmayı planlıyorum ve aşağıya yorum bırakarak konu önerilerinde bulunabilirsiniz. Şerefe! Alt yığın Blog Tam kaynak kodu: https://github.com/vndee/local-rag-example