
Programming



Listen to the Podcast on
Top Programming Writers
#1

Damian Griggs
@damianwgriggsAdaptive Systems Architect. Author. Legally Blind. Building Quantum Oracles & AI Memory Systems. 35+...
7 recent stories
#2

Maxi C
@mcseeI’m a sr software engineer specialized in Clean Co...
6 recent stories
#3

Richard Ebo
@lordsolidAndroid dev by craft, community builder by choice. Leading The Android...
6 recent stories
#4

Omotayo
@omotayojudeEnjoys fixing messy problems with clean code, good questions and the o...
5 recent stories
#5

Nikita Kothari
@damianwgriggsI am a Senior Member of Technical Staff at Salesforce, where I build A...
3 recent stories





Popular Programming Topics
#programming#software-development#javascript#web-development#coding#software-engineering#python#react#open-source#nodejs#tutorial#mobile-app-development#api#java#docker#software-architecture#kubernetes#development#github#serverless#front-end-development#android#testing#web-design#typescript#reactjs#learning-to-code#css#linux#software-testing#software#golang#debugging#ios#user-experience#html#frontend#backend#react-native#webdev#algorithms#app-development#javascript-development#engineering#learn-to-code#git#mobile-apps#android-app-development#functional-programming#php#code-quality#developer#sql#angular#developer-tools#apps#clean-code#ios-app-development#programming-languages#dotnet#mobile#ruby#containers#ruby-on-rails#performance#rest-api#swift#coding-skills#go#python-tutorials#solidity#monitoring#graphql#website-development#ui
Programming Stories






![Go [Technical Documentation]](https://hackernoon.imgix.net/images/img-kk837rt.png?auto=format&fit=max&w=96)














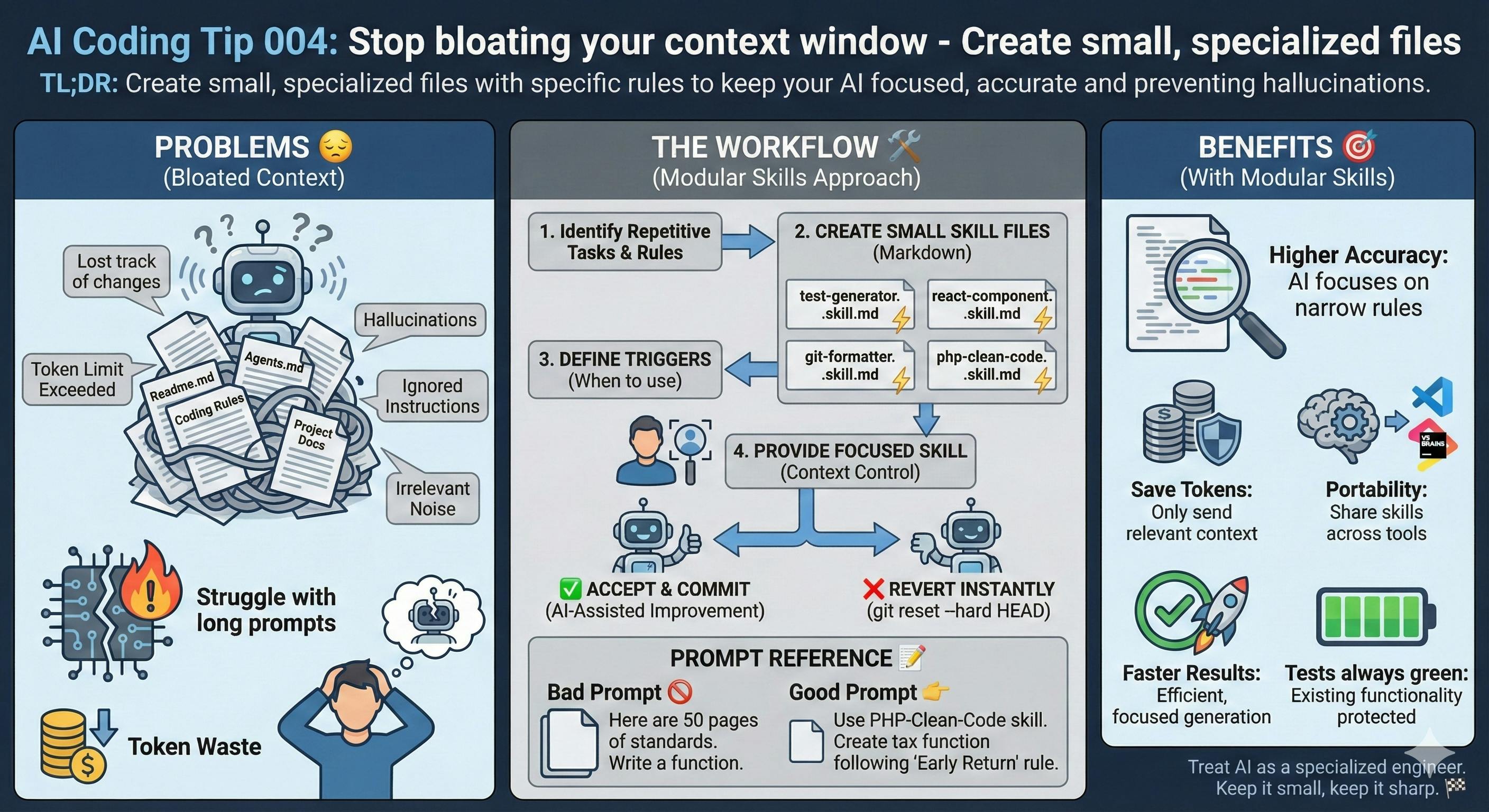











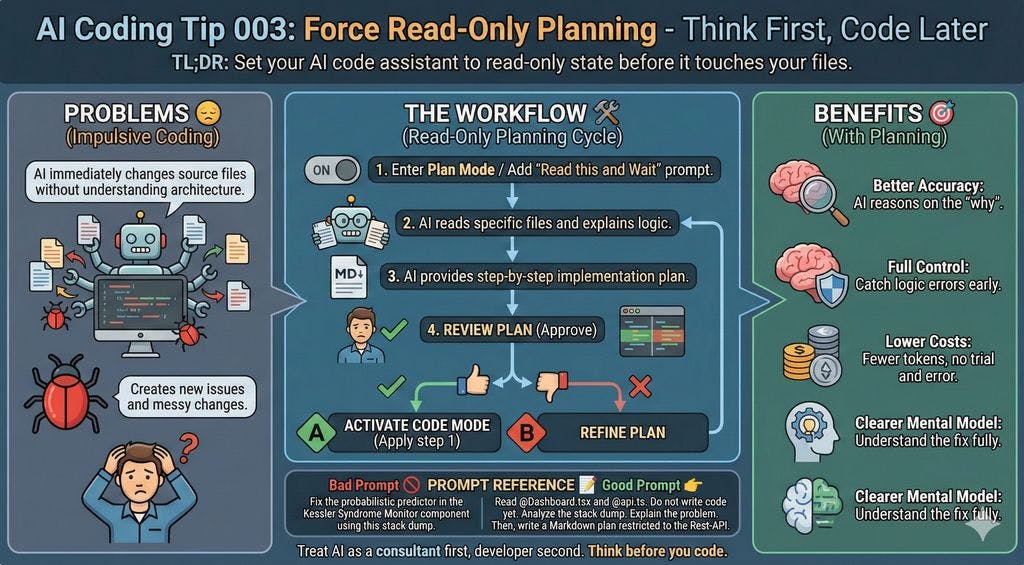
































What the Heck is GizmoSQL?

Dec 30, 2025















































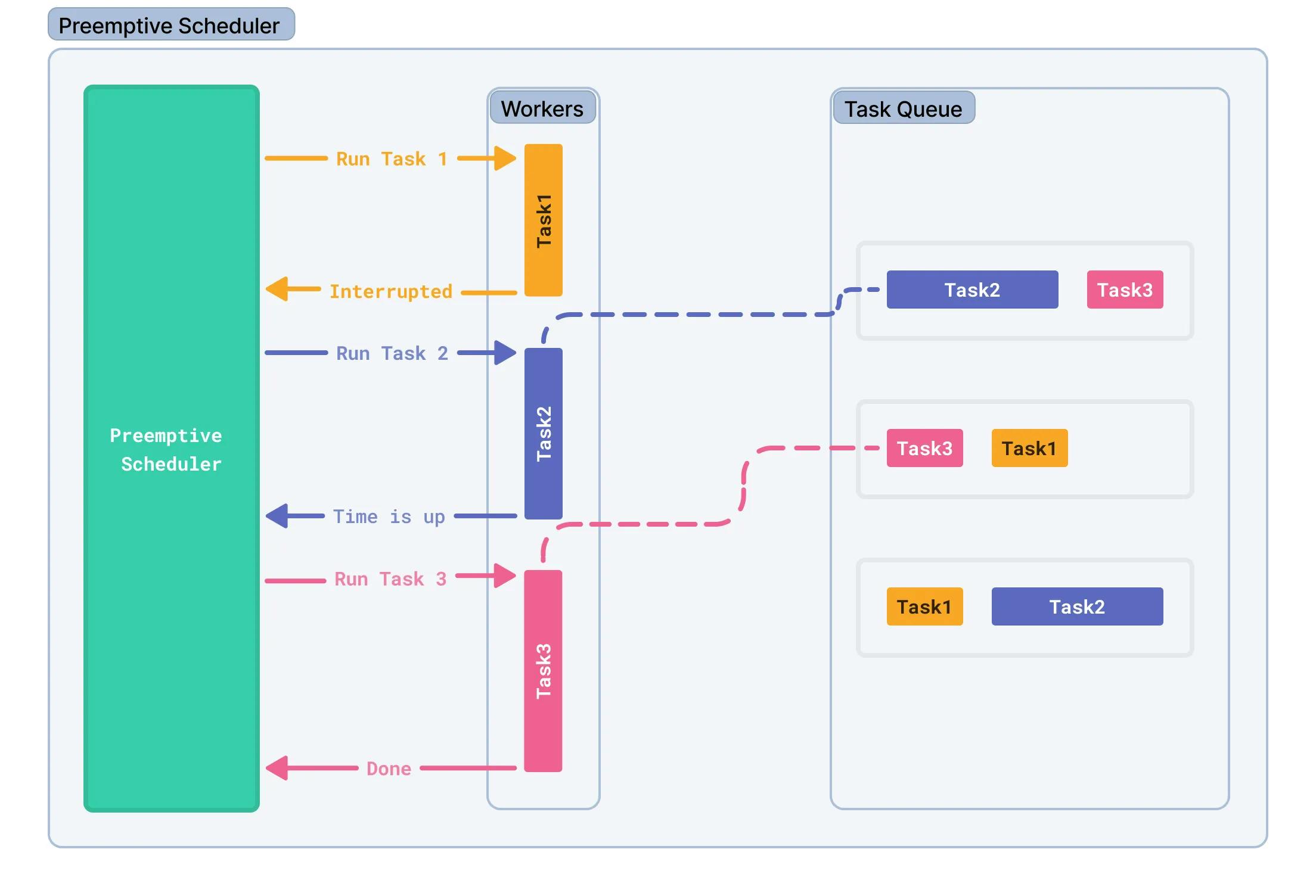



![Clean Code: Interfaces in Go - Why Small Is Beautiful [Part 3]](https://hackernoon.imgix.net/images/ZTiVtl9TF6Mqdq0GSgDuxuALFDX2-d10233z.png?auto=format&fit=max&w=3840)
























The Moral Cost of the Growth Hack

@hacker4949449
Oct 24, 2025

System Design in a Nutshell
Oct 23, 2025
