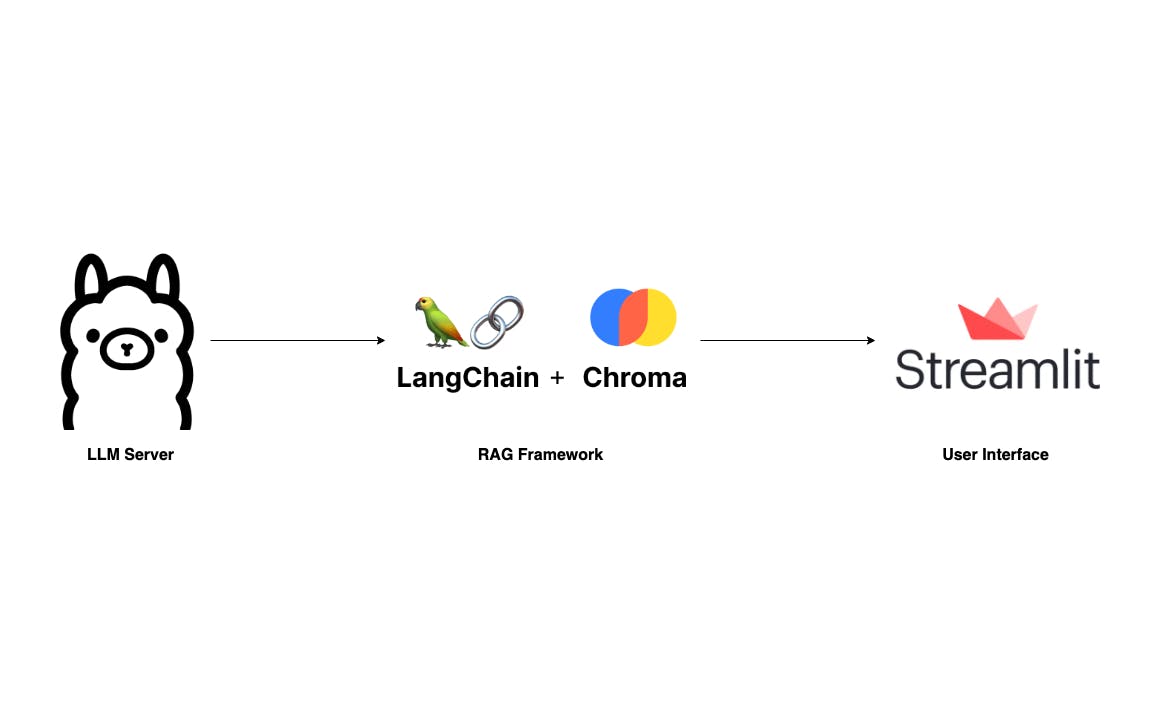
Com o surgimento dos grandes modelos de linguagem e seus recursos impressionantes, muitos aplicativos sofisticados estão sendo construídos com base em provedores gigantes de LLM, como OpenAI e Anthropic. O mito por trás de tais aplicações é a estrutura RAG, que foi explicada detalhadamente nos seguintes artigos: Construindo aplicativos LLM baseados em RAG para produção Geração Aumentada de Recuperação (RAG) Explicada: Compreendendo os Conceitos Chave O que é geração aumentada por recuperação? Para se familiarizar com o RAG, recomendo ler estes artigos. Esta postagem, no entanto, irá ignorar o básico e guiá-lo diretamente na construção de seu próprio aplicativo RAG que pode ser executado localmente em seu laptop sem qualquer preocupação com privacidade de dados e custo de token. Construiremos um aplicativo semelhante ao F, mas mais simples. Onde os usuários podem fazer upload de um documento PDF e fazer perguntas por meio de uma interface de usuário simples. Nossa pilha de tecnologia é super fácil com Langchain, Ollama e Streamlit. ChatPD : O componente mais crítico deste aplicativo é o servidor LLM. Graças a , temos um servidor LLM robusto que pode ser configurado localmente, até mesmo em um laptop. Enquanto é uma opção, acho o Ollama, escrito em Go, mais fácil de configurar e executar. Servidor LLM Ollama lhama.cpp : Sem dúvida, as duas principais bibliotecas no domínio LLM são e . Para este projeto utilizarei Langchain devido à minha familiaridade com ele por experiência profissional. Um componente essencial de qualquer estrutura RAG é o armazenamento de vetores. Estaremos usando aqui, pois se integra bem com Langchain. RAG Langchain LlamIndex Croma : a interface do usuário também é um componente importante. Embora existam muitas tecnologias disponíveis, prefiro usar , uma biblioteca Python, para sua tranquilidade. UI de bate-papo Streamlit Ok, vamos começar a configurá-lo. Configurar Ollama Conforme mencionado acima, configurar e executar o Ollama é simples. Primeira visita e baixe o aplicativo apropriado para o seu sistema operacional. ollama.ai Em seguida, abra seu terminal e execute o seguinte comando para obter o último . Embora existam muitos outros , escolho o Mistral-7B por seu tamanho compacto e qualidade competitiva. Mistral-7B Modelos LLM disponíveis ollama pull mistral Depois, execute para verificar se o modelo foi extraído corretamente. A saída do terminal deve ser semelhante à seguinte: ollama list Agora, se o servidor LLM ainda não estiver em execução, inicie-o com . Se você encontrar uma mensagem de erro como , isso indica que o servidor já está em execução por padrão e você pode prosseguir para a próxima etapa. ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" Construa o pipeline RAG A segunda etapa do nosso processo é construir o pipeline RAG. Dada a simplicidade da nossa aplicação, precisamos principalmente de dois métodos: e . ingest ask O método aceita um caminho de arquivo e o carrega no armazenamento vetorial em duas etapas: primeiro, ele divide o documento em partes menores para acomodar o limite de token do LLM; segundo, ele vetoriza esses pedaços usando Qdrant FastEmbeddings e os armazena no Chroma. ingest O método lida com as consultas do usuário. Os usuários podem fazer uma pergunta e, em seguida, o RetrievalQAChain recupera os contextos relevantes (pedaços de documentos) usando técnicas de pesquisa de similaridade vetorial. ask Com a pergunta do usuário e os contextos recuperados, podemos redigir um prompt e solicitar uma previsão ao servidor LLM. from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None O prompt vem do hub Langchain: . Este prompt foi testado e baixado milhares de vezes, servindo como um recurso confiável para aprender sobre técnicas de prompt do LLM. Prompt Langchain RAG para Mistral Você pode aprender mais sobre técnicas de solicitação de LLM . aqui Mais detalhes sobre a implementação: : usamos PyPDFLoader para carregar o arquivo PDF carregado pelo usuário. O RecursiveCharacterSplitter, fornecido pela Langchain, divide este PDF em pedaços menores. É importante filtrar metadados complexos não suportados pelo ChromaDB usando a função do Langchain. ingest filter_complex_metadata Para armazenamento de vetores, o Chroma é usado, juntamente com como nosso modelo de incorporação. Este modelo leve é então transformado em um recuperador com um limite de pontuação de 0,5 ek = 3, o que significa que ele retorna os 3 principais pedaços com as pontuações mais altas acima de 0,5. Finalmente, construímos uma cadeia de conversação simples usando . Qdrant FastEmbed LECL : Este método simplesmente passa a pergunta do usuário para nossa cadeia predefinida e então retorna o resultado. ask : Este método é usado para limpar a sessão de bate-papo anterior e o armazenamento quando um novo arquivo PDF é carregado. clear Rascunho de uma IU simples Para uma interface de usuário simples, usaremos , uma estrutura de UI projetada para a prototipagem rápida de aplicativos de IA/ML. Streamlit import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() Execute este código com o comando para ver como fica. streamlit run app.py Ok, é isso! Agora temos um aplicativo ChatPDF que roda inteiramente no seu laptop. Como esta postagem se concentra principalmente em fornecer uma visão geral de alto nível de como construir seu próprio aplicativo RAG, há vários aspectos que precisam de ajustes. Você pode considerar as seguintes sugestões para aprimorar seu aplicativo e desenvolver ainda mais suas habilidades: : atualmente, ele não lembra o fluxo da conversa. Adicionar memória temporária ajudará seu assistente a estar ciente do contexto. Adicionar memória à cadeia de conversas : não há problema em conversar sobre um documento por vez. Mas imagine se pudéssemos conversar sobre vários documentos – você poderia colocar toda a sua estante lá. Isso seria muito legal! Permitir uploads de vários arquivos : Embora o Mistral seja eficaz, existem muitas outras alternativas disponíveis. Você pode encontrar um modelo que melhor atenda às suas necessidades, como LlamaCode para desenvolvedores. Porém, lembre-se que a escolha do modelo depende do seu hardware, principalmente da quantidade de RAM que você possui 💵 Use outros modelos LLM : há espaço para experimentação no RAG. Você pode querer alterar a métrica de recuperação, o modelo de incorporação, ou adicionar camadas como um reclassificador para melhorar os resultados. Aprimore o pipeline do RAG Finalmente, obrigado por ler. Se você achar esta informação útil, considere assinar meu ou meu pessoal . Pretendo escrever mais sobre aplicações RAG e LLM, e você pode sugerir tópicos deixando um comentário abaixo. Saúde! Subpilha blog Código fonte completo: https://github.com/vndee/local-rag-example