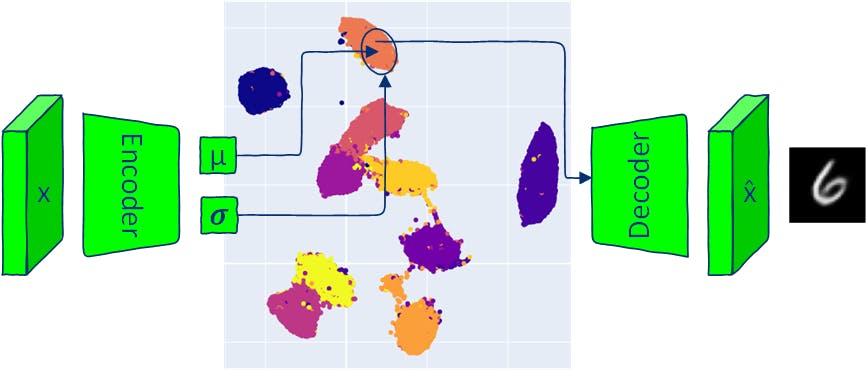
従来のオートエンコーダと同様に、VAE アーキテクチャにはエンコーダとデコーダの 2 つの部分があります。従来の AE モデルは、入力を潜在空間ベクトルにマッピングし、このベクトルから出力を再構築します。 VAE は入力を多変量正規分布にマッピングします (エンコーダーは各潜在次元の平均と分散を出力します)。 VAE エンコーダは分布を生成するため、この分布からサンプリングし、サンプリングされた潜在ベクトルをデコーダに渡すことによって新しいデータを生成できます。出力画像を生成するために生成された分布からサンプリングすることは、VAE が入力データと類似しているが同一の新しいデータを生成できることを意味します。 この記事では、VAE アーキテクチャのコンポーネントを検討し、VAE モデルを使用して新しいイメージ (サンプリング) を生成するいくつかの方法を説明します。すべてのコードは で入手できます。 Google Colab 1 VAE モデルの実装 オートエンコーダーと変分オートエンコーダーはどちらも、エンコーダーとデコーダーの 2 つの部分があります。 AE のエンコーダ ニューラル ネットワークは、各画像を潜在空間内の単一ベクトルにマッピングすることを学習し、デコーダは、エンコードされた潜在ベクトルから元の画像を再構成することを学習します。 VAE のエンコーダー ニューラル ネットワークは、潜在空間の各次元の確率分布 (多変量分布) を定義するパラメーターを出力します。エンコーダーは入力ごとに、潜在空間の各次元の平均と分散を生成します。 出力の平均と分散は、多変量ガウス分布を定義するために使用されます。デコーダのニューラル ネットワークは AE モデルと同じです。 1.1 VAE 損失 VAE モデルをトレーニングする目的は、提供された潜在ベクトルから実際の画像を生成する可能性を最大化することです。トレーニング中に、VAE モデルは 2 つの損失を最小限に抑えます。 - 入力画像とデコーダの出力の差。 再構成損失 (KL 発散、2 つの確率分布間の統計的距離) - エンコーダーの出力の確率分布と事前分布 (標準正規分布) の間の距離。潜在空間の正規化に役立ちます。 カルバック・ライブラー発散損失 1.2 復興損失 一般的な再構成損失は、バイナリ クロス エントロピー (BCE) と平均二乗誤差 (MSE) です。この記事では、デモに MNIST データセットを使用します。 MNIST 画像にはチャネルが 1 つだけあり、ピクセルは 0 から 1 までの値を取ります。 この場合、BCE 損失を再構成損失として使用して、MNIST 画像のピクセルをベルヌーイ分布に従うバイナリ確率変数として扱うことができます。 reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 カルバックとライブラーの発散 上で述べたように、KL ダイバージェンスは 2 つの分布間の差異を評価します。距離の対称特性がないことに注意してください: KL(P‖Q)!=KL(Q‖P)。 比較する必要がある 2 つの分布は次のとおりです。 入力画像 x が与えられた場合のエンコーダー出力の潜在空間: q(z|x) 各潜在空間次元 で平均が 0、標準偏差が 1 の正規分布であると仮定される の事前潜在空間。 N(0, ) I p(z) このような仮定により、KL 発散の計算が簡素化され、潜在空間が既知の管理可能な分布に従うことが促進されます。 from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 エンコーダ class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 デコーダ class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 VAEモデル ランダム サンプルを逆伝播するには、ランダム サンプルのパラメーター ( と 𝝈) を関数の外に移動して、パラメーターによる勾配の計算を可能にする必要があります。このステップは「再パラメータ化トリック」とも呼ばれます。 μ PyTorch では、エンコーダーの出力 と 𝝈 を使用して 分布を作成し、再パラメータ化トリックを実装する メソッドでそこからサンプリングできます。これは μ 正規 rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 VAE のトレーニング MNIST のトレーニング データとテスト データをロードします。 transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) 上の図に示されている VAE トレーニング ステップに従うトレーニング ループを作成します。 def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 潜在空間の視覚化 def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 VAEによるサンプリング 変分オートエンコーダー (VAE) からのサンプリングにより、トレーニング中に見られるものと同様の新しいデータを生成できます。これは、VAE を従来の AE アーキテクチャから分離する独自の側面です。 VAE からサンプリングするにはいくつかの方法があります。 指定された入力を与えられた事後分布からのサンプリング。 事後サンプリング: 標準正規多変量分布を仮定した潜在空間からのサンプリング。これは、潜在変数が正規分布するという仮定 (VAE トレーニング中に使用される) によって可能になります。このメソッドでは、特定のプロパティを持つデータの生成 (たとえば、特定のクラスからのデータの生成) は許可されません。 事前サンプリング: : 潜在空間内の 2 点間の補間により、潜在空間変数の変化が生成されたデータの変化にどのように対応するかを明らかにできます。 interpolation : VAE の潜在次元の走査 データの潜在空間分散は各次元に依存します。トラバーサルは、選択した 1 つの次元を除く潜在ベクトルのすべての次元を固定し、その範囲内で選択した次元の値を変更することによって行われます。潜在空間の一部の次元は、データの特定の属性に対応する場合があります (VAE にはその動作を強制する特定のメカニズムがありませんが、発生する可能性はあります)。 潜在次元の走査 たとえば、潜在空間の一次元は、顔の感情表現やオブジェクトの向きを制御する可能性があります。 各サンプリング方法は、VAE の潜在空間によってキャプチャされたデータ プロパティを調査および理解するための異なる方法を提供します。 2.1 事後サンプリング (特定の入力画像から) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) 事後サンプリングでは、現実的なデータ サンプルを生成できますが、変動性は低く、出力データは入力データと似ています。 2.2 事前サンプリング (ランダムな潜在空間ベクトルから) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) N(0, ) を使用した事前サンプリングでは、常に妥当なデータが生成されるわけではありませんが、ばらつきが大きくなります。 I 2.3 クラスセンターからのサンプリング 各クラスの平均エンコーディングはデータセット全体から蓄積でき、後で制御 (条件付き生成) に使用できます。 def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') 平均クラスμの正規分布からのサンプリングにより、同じクラスからの新しいデータの生成が保証されます。 2.4 補間 def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 2 つのランダムな潜在ベクトル間の補間 start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 2 つのクラス センター間の補間 for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 潜在空間横断 潜在ベクトルの各次元は正規分布を表します。次元の値の範囲は、次元の平均と分散によって制御されます。値の範囲を調べる簡単な方法は、正規分布の逆 CDF (累積分布関数) を使用することです。 ICDF は 0 から 1 までの値 (確率を表す) を受け取り、分布から値を返します。与えられた確率 に対して、ICDF は、確率変数の確率が 以下である確率が与えられた確率 と等しくなるような 値を出力します。 p p_icdf p p_icdf 正規分布がある場合、icdf(0.5) は分布の平均を返すはずです。 icdf(0.95) は、分布からのデータの 95% より大きい値を返す必要があります。 2.5.1 単一次元の潜在空間横断 def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') 単一の寸法を移動すると、桁のスタイルや制御桁の方向が変更される場合があります。 2.5.3 二次元潜在空間横断 def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') 複数のディメンションを一度に走査することで、変動性の高いデータを生成する制御可能な方法が提供されます。 2.6 ボーナス - 潜在空間からの数字の 2D 多様体 VAE モデルが その潜在空間から数字の 2D 多様体を表示することが可能です。これを行うには、 および を指定して 関数を使用します。 =2 でトレーニングされた場合、 z_dim =0 dim_1 =2 dim_2 traverse_two_latent_dimensions vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')