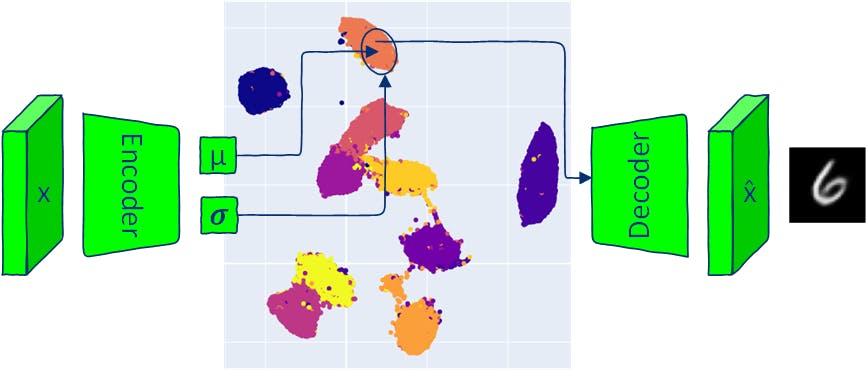
与传统的自动编码器相同,VAE 架构有两部分:编码器和解码器。传统的 AE 模型将输入映射到潜在空间向量,并根据该向量重建输出。 VAE 将输入映射到多元正态分布(编码器输出每个潜在维度的均值和方差)。 由于 VAE 编码器产生一个分布,因此可以通过从该分布采样并将采样的潜在向量传递到解码器来生成新数据。从生成的分布中采样以生成输出图像意味着 VAE 允许生成与输入数据相似但相同的新数据。 本文探讨了 VAE 架构的组件,并提供了使用 VAE 模型生成新图像(采样)的几种方法。所有代码都可以在 中找到。 Google Colab 1 VAE模型实现 自动编码器和变分自动编码器都有两部分:编码器和解码器。 AE 的编码器神经网络学习将每个图像映射到潜在空间中的单个向量,而解码器学习从编码的潜在向量重建原始图像。 VAE 的编码器神经网络输出定义潜在空间每个维度的概率分布(多元分布)的参数。对于每个输入,编码器都会为潜在空间的每个维度生成均值和方差。 输出均值和方差用于定义多元高斯分布。解码器神经网络与 AE 模型中的相同。 1.1 VAE损失 训练 VAE 模型的目标是最大化从提供的潜在向量生成真实图像的可能性。在训练过程中,VAE 模型最大限度地减少了两个损失: - 输入图像和解码器输出之间的差异。 重建损失 (KL 散度是两个概率分布之间的统计距离)——编码器输出的概率分布与先验分布(标准正态分布)之间的距离,有助于规范潜在空间。 Kullback–Leibler 散度损失 1.2 重建损失 常见的重建损失是二元交叉熵(BCE)和均方误差(MSE)。在本文中,我将使用 MNIST 数据集进行演示。 MNIST 图像只有一个通道,像素取值在 0 到 1 之间。 在这种情况下,BCE损失可以用作重建损失,将MNIST图像的像素视为遵循伯努利分布的二元随机变量。 reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 库尔贝克-莱布勒散度 如上所述 - KL 散度评估两个分布之间的差异。请注意,它不具有距离的对称属性:KL(P‖Q)!=KL(Q‖P)。 需要比较的两个分布是: 给定输入图像 x 的编码器输出的潜在空间: q(z|x) 潜在空间先验 假设为正态分布,每个潜在空间维度 均值为 0,标准差为 1。 p(z) N(0, ) I 这样的假设简化了 KL 散度计算,并鼓励潜在空间遵循已知的、可管理的分布。 from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 编码器 class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 解码器 class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 VAE模型 要通过随机样本进行反向传播,您需要将随机样本的参数( 和 𝝈)移到函数外部,以允许通过参数进行梯度计算。此步骤也称为“重新参数化技巧”。 μ 在 PyTorch 中,您可以使用编码器的输出 和 𝝈 创建 ,并使用实现重新参数化技巧的 方法从中进行采样:它与 相同 μ 正态分布 rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 训练 VAE 加载 MNIST 训练和测试数据。 transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) 创建一个遵循上图中可视化的 VAE 训练步骤的训练循环。 def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 可视化潜在空间 def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 VAE 采样 从变分自动编码器 (VAE) 进行采样可以生成与训练期间看到的数据类似的新数据,这是将 VAE 与传统 AE 架构区分开来的独特之处。 从 VAE 中采样有多种方法: 根据给定的输入从后验分布中进行采样。 后验采样: 假设标准正态多元分布,从潜在空间采样。这是可能的,因为假设(在 VAE 训练期间使用)潜在变量呈正态分布。此方法不允许生成具有特定属性的数据(例如,从特定类生成数据)。 先前采样: :潜在空间中两点之间的插值可以揭示潜在空间变量的变化如何对应于生成数据的变化。 插值 :遍历VAE潜在维度的潜在维度数据的方差取决于每个维度。遍历是通过固定潜在向量的所有维度(除了一个选定维度)并在其范围内改变选定维度的值来完成的。潜在空间的某些维度可能对应于数据的特定属性(VAE 没有特定机制来强制该行为,但它可能会发生)。 潜在维度的遍历 例如,潜在空间中的一维可以控制面部的情绪表达或物体的方向。 每种采样方法都提供了一种不同的方式来探索和理解 VAE 潜在空间捕获的数据属性。 2.1 后采样(来自给定的输入图像) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) 后采样允许生成真实的数据样本,但可变性较低:输出数据与输入数据相似。 2.2 先验采样(来自随机潜在空间向量) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) 使用 N(0, ) 进行预先采样并不总是生成可信的数据,但具有很高的可变性。 I 2.3 从班级中心抽样 每个类的平均编码可以从整个数据集中累积,然后用于受控(条件生成)。 def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') 从具有平均类 μ 的正态分布中采样可以保证从同一类生成新数据。 2.4 插值 def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 两个随机潜在向量之间的插值 start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 两个类中心之间的插值 for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 潜在空间遍历 潜在向量的每个维度代表正态分布;维度值的范围由维度的均值和方差控制。遍历值范围的一种简单方法是使用正态分布的逆 CDF(累积分布函数)。 ICDF 取 0 到 1 之间的值(表示概率)并返回分布的值。对于给定的概率 ,ICDF 输出一个 值,使得随机变量 <= 的概率等于给定的概率 ?” p p_icdf p_icdf p 如果您有正态分布,icdf(0.5) 应返回分布的平均值。 icdf(0.95) 应返回大于分布数据 95% 的值。 2.5.1 单维潜在空间遍历 def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') 遍历单个维度可能会导致数字样式或控制数字方向的更改。 2.5.3 二维潜在空间遍历 def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') 一次遍历多个维度提供了一种生成具有高可变性的数据的可控方式。 2.6 奖励 - 来自潜在空间的 2D 数字流形 如果使用 则可以从其潜在空间显示 2D 数字流形。为此,我将使用 函数,其中 和 。 =2 训练 VAE 模型, z_dim traverse_two_latent_dimensions =0 dim_1 =2 dim_2 vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')