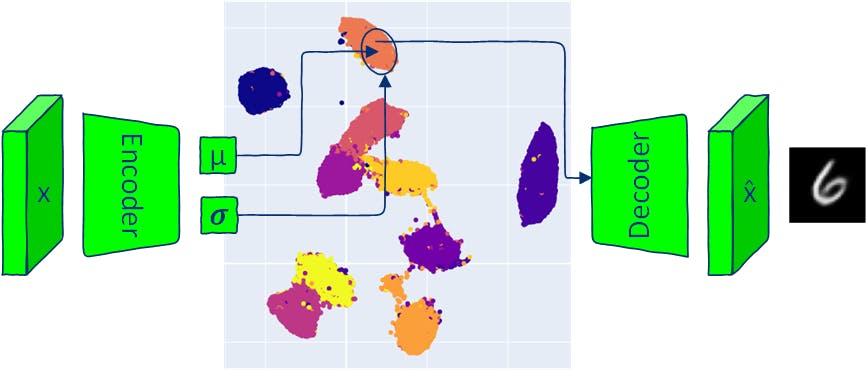
Как и традиционные автоэнкодеры, архитектура VAE состоит из двух частей: кодировщика и декодера. Традиционные модели AE отображают входные данные в вектор скрытого пространства и восстанавливают выходные данные из этого вектора. VAE отображает входные данные в многомерное нормальное распределение (кодер выводит среднее значение и дисперсию каждого скрытого измерения). Поскольку кодер VAE создает распределение, новые данные могут быть сгенерированы путем выборки из этого распределения и передачи отобранного скрытого вектора в декодер. Выборка из полученного распределения для создания выходных изображений означает, что VAE позволяет генерировать новые данные, похожие, но идентичные входным данным. В этой статье рассматриваются компоненты архитектуры VAE и представлены несколько способов создания новых изображений (выборки) с помощью моделей VAE. Весь код доступен в . Google Colab 1 Реализация модели VAE И автоэнкодеры, и вариационные автоэнкодеры состоят из двух частей: кодера и декодера. Нейронная сеть кодера AE учится отображать каждое изображение в один вектор в скрытом пространстве, а декодер учится восстанавливать исходное изображение из закодированного скрытого вектора. Нейронная сеть кодировщика VAE выводит параметры, которые определяют распределение вероятностей для каждого измерения скрытого пространства (многомерное распределение). Для каждого входного сигнала кодер выдает среднее значение и дисперсию для каждого измерения скрытого пространства. Выходное среднее значение и дисперсия используются для определения многомерного распределения Гаусса. Нейронная сеть декодера такая же, как и в моделях AE. 1.1 Потери VAE Цель обучения модели VAE — максимизировать вероятность создания реальных изображений из предоставленных скрытых векторов. Во время обучения модель VAE минимизирует две потери: — разница между входными изображениями и выходными данными декодера. потери реконструкции (KL Divergence - статистическое расстояние между двумя распределениями вероятностей) - расстояние между распределением вероятностей выходных данных кодера и априорным распределением (стандартное нормальное распределение), помогающее регуляризовать скрытое пространство. Потери на дивергенцию Кульбака – Лейблера 1.2 Потери на реконструкцию Обычными потерями при реконструкции являются двоичная перекрестная энтропия (BCE) и среднеквадратическая ошибка (MSE). В этой статье я буду использовать набор данных MNIST для демонстрации. Изображения MNIST имеют только один канал, а пиксели принимают значения от 0 до 1. В этом случае потери BCE можно использовать в качестве потерь при реконструкции, чтобы рассматривать пиксели изображений MNIST как двоичную случайную величину, соответствующую распределению Бернулли. reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 Расхождение Кульбака – Лейблера Как упоминалось выше, дивергенция KL оценивает разницу между двумя распределениями. Обратите внимание, что оно не обладает симметричным свойством расстояния: KL(P‖Q)!=KL(Q‖P). Необходимо сравнить два распределения: скрытое пространство вывода кодера с учетом входных изображений x: q(z|x) априорное скрытое пространство , которое считается нормальным распределением со средним значением, равным нулю, и стандартным отклонением, равным единице, в каждом измерении скрытого пространства . p(z) N(0, ) I Такое предположение упрощает вычисление дивергенции KL и побуждает скрытое пространство следовать известному управляемому распределению. from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 Кодер class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 Декодер class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 Модель VAE Для обратного распространения по случайной выборке вам необходимо переместить параметры случайной выборки ( и 𝝈) за пределы функции, чтобы обеспечить вычисление градиента через параметры. Этот шаг также называют «трюком с перепараметризацией». μ В PyTorch вы можете создать распределение с выходными данными кодировщика и 𝝈 и выполнить выборку из него с помощью метода , который реализует трюк с перепараметризацией: это то же самое, что нормальное μ rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 Обучение VAE Загрузите данные поезда и испытаний MNIST. transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) Создайте цикл обучения, который будет следовать шагам обучения VAE, показанным на рисунке выше. def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 Визуализируйте скрытое пространство def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 Отбор проб с помощью VAE Выборка из вариационного автоэнкодера (VAE) позволяет генерировать новые данные, аналогичные тем, которые наблюдаются во время обучения, и это уникальный аспект, который отличает VAE от традиционной архитектуры AE. Существует несколько способов отбора проб из VAE: выборка из апостериорного распределения с учетом предоставленных входных данных. апостериорная выборка: выборка из скрытого пространства при условии стандартного нормального многомерного распределения. Это возможно благодаря предположению (используемому при обучении VAE), что скрытые переменные имеют нормальное распределение. Этот метод не позволяет генерировать данные с определенными свойствами (например, генерировать данные из определенного класса). предварительная выборка: : интерполяция между двумя точками в скрытом пространстве может показать, как изменения в переменной скрытого пространства соответствуют изменениям в сгенерированных данных. интерполяция : прохождение скрытых измерений VAE, дисперсия скрытого пространства данных зависит от каждого измерения. Обход осуществляется путем фиксации всех измерений скрытого вектора, кроме одного выбранного измерения, и изменения значений выбранного измерения в его диапазоне. Некоторые измерения скрытого пространства могут соответствовать определенным атрибутам данных (у VAE нет конкретных механизмов, обеспечивающих такое поведение, но это может произойти). обход скрытых измерений Например, одно измерение скрытого пространства может контролировать эмоциональное выражение лица или ориентацию объекта. Каждый метод выборки предоставляет свой способ изучения и понимания свойств данных, зафиксированных скрытым пространством VAE. 2.1 Апостериорная выборка (из заданного входного изображения) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) Апостериорная выборка позволяет генерировать реалистичные выборки данных, но с низкой изменчивостью: выходные данные аналогичны входным данным. 2.2. Предварительная выборка (из случайного вектора скрытого пространства) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) Предварительная выборка с помощью N(0, ) не всегда дает правдоподобные данные, но имеет высокую вариабельность. I 2.3 Выборка из центров классов Средние кодировки каждого класса могут накапливаться из всего набора данных и впоследствии использоваться для контролируемой (условной генерации). def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') Выборка из нормального распределения с усредненным классом μ гарантирует генерацию новых данных из того же класса. 2.4 Интерполяция def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 Интерполяция между двумя случайными скрытыми векторами start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 Интерполяция между двумя центрами классов for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 Скрытое перемещение в пространстве Каждое измерение скрытого вектора представляет собой нормальное распределение; диапазон значений измерения контролируется средним значением и дисперсией измерения. Простой способ пересечь диапазон значений — использовать обратную CDF (кумулятивную функцию распределения) нормального распределения. ICDF принимает значение от 0 до 1 (представляющее вероятность) и возвращает значение из распределения. Для заданной вероятности ICDF выводит значение такое, что вероятность того, что случайная величина будет <= равна заданной вероятности ?» p p_icdf p_icdf, p Если у вас нормальное распределение, icdf(0.5) должен вернуть среднее значение распределения. icdf(0.95) должен возвращать значение, превышающее 95% данных из распределения. 2.5.1 Обход скрытого пространства в одном измерении def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') Перемещение одного измерения может привести к изменению стиля или ориентации контрольных цифр. 2.5.3. Обход скрытого пространства в двух измерениях def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') Обход нескольких измерений одновременно обеспечивает контролируемый способ создания данных с высокой изменчивостью. 2.6 Бонус — 2D-множество цифр из скрытого пространства Если модель VAE обучена с можно отобразить двумерное многообразие цифр из его скрытого пространства. Для этого я буду использовать функцию с и . = 2, z_dim traverse_two_latent_dimensions =0 dim_1 =2 dim_2 vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')