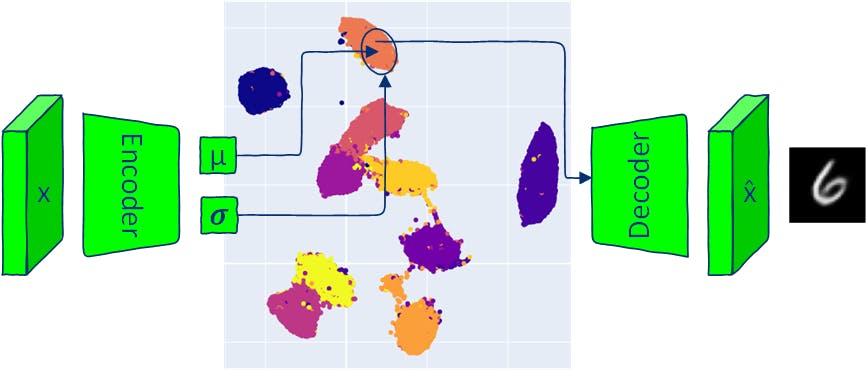
Assim como os autoencoders tradicionais, a arquitetura VAE tem duas partes: um codificador e um decodificador. Os modelos tradicionais de EA mapeiam as entradas em um vetor de espaço latente e reconstroem a saída desse vetor. VAE mapeia as entradas em uma distribuição normal multivariada (o codificador gera a média e a variância de cada dimensão latente). Como o codificador VAE produz uma distribuição, os novos dados podem ser gerados por amostragem dessa distribuição e passagem do vetor latente amostrado para o decodificador. A amostragem da distribuição produzida para gerar imagens de saída significa que o VAE permite a geração de novos dados semelhantes, mas idênticos aos dados de entrada. Este artigo explora componentes da arquitetura VAE e fornece diversas maneiras de gerar novas imagens (amostragem) com modelos VAE. Todo o código está disponível no . Google Colab 1 Implementação do Modelo VAE Autoencoders e Autoencoders Variacionais têm duas partes: codificador e decodificador. A rede neural do codificador de AE aprende a mapear cada imagem em um único vetor no espaço latente e o decodificador aprende a reconstruir a imagem original a partir do vetor latente codificado. A rede neural codificadora do VAE gera parâmetros que definem uma distribuição de probabilidade para cada dimensão do espaço latente (distribuição multivariada). Para cada entrada, o codificador produz uma média e uma variância para cada dimensão do espaço latente. A média e a variância de saída são usadas para definir uma distribuição gaussiana multivariada. A rede neural do decodificador é a mesma dos modelos AE. 1.1 Perdas VAE O objetivo de treinar um modelo VAE é maximizar a probabilidade de geração de imagens reais a partir de vetores latentes fornecidos. Durante o treinamento, o modelo VAE minimiza duas perdas: - a diferença entre as imagens de entrada e a saída do decodificador. perda de reconstrução (KL Divergência, uma distância estatística entre duas distribuições de probabilidade) - a distância entre a distribuição de probabilidade da saída do codificador e uma distribuição anterior (uma distribuição normal padrão), ajudando a regularizar o espaço latente. Perda de divergência de Kullback – Leibler 1.2 Perda de Reconstrução Perdas de reconstrução comuns são entropia cruzada binária (BCE) e erro quadrático médio (MSE). Neste artigo, usarei o conjunto de dados MNIST para a demonstração. As imagens MNIST possuem apenas um canal e os pixels assumem valores entre 0 e 1. Neste caso, a perda BCE pode ser usada como perda de reconstrução para tratar pixels de imagens MNIST como uma variável aleatória binária que segue a distribuição de Bernoulli. reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 Divergência Kullback-Leibler Conforme mencionado acima - a divergência KL avalia a diferença entre duas distribuições. Observe que não possui uma propriedade simétrica de distância: KL(P‖Q)!=KL(Q‖P). As duas distribuições que precisam ser comparadas são: o espaço latente da saída do codificador, dadas as imagens de entrada x: q(z|x) espaço latente anterior que é assumido como uma distribuição normal com média zero e desvio padrão de um em cada dimensão do espaço latente . p(z) N(0, ) I Tal suposição simplifica o cálculo da divergência KL e incentiva o espaço latente a seguir uma distribuição conhecida e gerenciável. from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 Codificador class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 Decodificador class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 Modelo VAE Para retropropagar através de uma amostra aleatória, você precisa mover os parâmetros da amostra aleatória ( e 𝝈) para fora da função para permitir o cálculo do gradiente através dos parâmetros. Esta etapa também é chamada de “truque de reparametrização”. μ No PyTorch, você pode criar uma distribuição com a saída e 𝝈 do codificador e fazer uma amostra dela com o método que implementa o truque de reparametrização: é o mesmo que Normal μ rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 Treinando um VAE Carregue o trem MNIST e os dados de teste. transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) Crie um ciclo de treinamento que siga as etapas de treinamento VAE visualizadas na figura acima. def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 Visualize o Espaço Latente def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 Amostragem com VAE A amostragem de um Autoencoder Variacional (VAE) permite a geração de novos dados semelhantes aos vistos durante o treinamento e é um aspecto único que separa o VAE da arquitetura AE tradicional. Existem várias maneiras de amostragem de um VAE: amostragem da distribuição posterior dada uma entrada fornecida. amostragem posterior: amostragem do espaço latente assumindo uma distribuição multivariada normal padrão. Isto é possível devido à suposição (usada durante o treinamento VAE) de que as variáveis latentes são normalmente distribuídas. Este método não permite a geração de dados com propriedades específicas (por exemplo, gerar dados de uma classe específica). amostragem anterior: : a interpolação entre dois pontos no espaço latente pode revelar como as mudanças na variável do espaço latente correspondem às mudanças nos dados gerados. interpolação : travessia de dimensões latentes da variância do espaço latente VAE dos dados depende de cada dimensão. O percurso é feito fixando todas as dimensões do vetor latente, exceto uma dimensão escolhida e variando os valores da dimensão escolhida em seu intervalo. Algumas dimensões do espaço latente podem corresponder a atributos específicos dos dados (o VAE não possui mecanismos específicos para forçar esse comportamento, mas pode acontecer). travessia de dimensões latentes Por exemplo, uma dimensão no espaço latente pode controlar a expressão emocional de um rosto ou a orientação de um objeto. Cada método de amostragem fornece uma maneira diferente de explorar e compreender as propriedades dos dados capturados pelo espaço latente do VAE. 2.1 Amostragem posterior (a partir de uma determinada imagem de entrada) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) A amostragem posterior permite a geração de amostras de dados realistas, mas com baixa variabilidade: os dados de saída são semelhantes aos dados de entrada. 2.2 Amostragem Prévia (de um Vetor Espacial Latente Aleatório) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) A amostragem prévia com N(0, ) nem sempre gera dados plausíveis, mas apresenta alta variabilidade. I 2.3 Amostragem de Centros de Classe As codificações médias de cada classe podem ser acumuladas a partir de todo o conjunto de dados e posteriormente usadas para uma geração controlada (geração condicional). def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') A amostragem de uma distribuição normal com classe média μ garante a geração de novos dados da mesma classe. 2.4 Interpolação def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 Interpolação entre dois vetores latentes aleatórios start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 Interpolação entre dois centros de aula for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 Travessia Latente do Espaço Cada dimensão do vetor latente representa uma distribuição normal; o intervalo de valores da dimensão é controlado pela média e variância da dimensão. Uma maneira simples de percorrer o intervalo de valores seria usar CDF inverso (funções de distribuição cumulativa) da distribuição normal. O ICDF assume um valor entre 0 e 1 (representando probabilidade) e retorna um valor da distribuição. Para uma determinada probabilidade o ICDF gera um valor tal que a probabilidade de uma variável aleatória ser <= é igual à probabilidade dada ? p, p_icdf p_icdf p Se você tiver uma distribuição normal, icdf(0.5) deverá retornar a média da distribuição. icdf(0.95) deve retornar um valor maior que 95% dos dados da distribuição. 2.5.1 Travessia de Espaço Latente de Dimensão Única def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') Atravessar uma única dimensão pode resultar em uma mudança no estilo do dígito ou na orientação do dígito de controle. 2.5.3 Travessia Espacial Latente em Duas Dimensões def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') Atravessar múltiplas dimensões ao mesmo tempo fornece uma maneira controlável de gerar dados com alta variabilidade. 2.6 Bônus - Coletor 2D de dígitos do espaço latente Se um modelo VAE for treinado com é possível exibir uma variedade 2D de dígitos de seu espaço latente. Para fazer isso, usarei com e . =2, z_dim a função traverse_two_latent_dimensions =0 dim_1 =2 dim_2 vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')