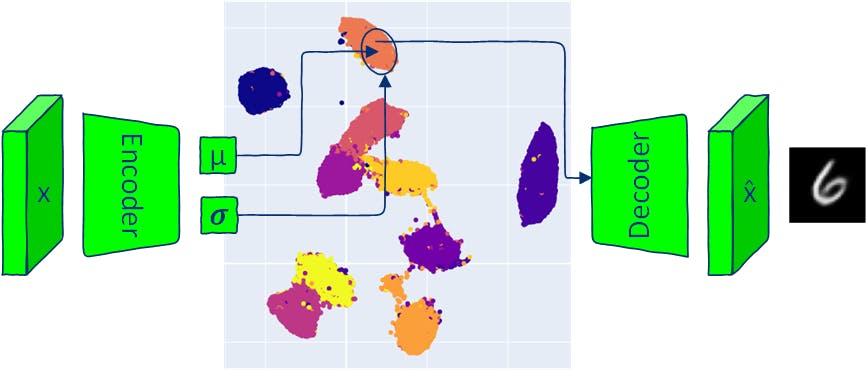
Wie herkömmliche Autoencoder besteht die VAE-Architektur aus zwei Teilen: einem Encoder und einem Decoder. Herkömmliche AE-Modelle bilden Eingaben in einen Latentraumvektor ab und rekonstruieren die Ausgabe aus diesem Vektor. VAE ordnet Eingaben einer multivariaten Normalverteilung zu (der Encoder gibt den Mittelwert und die Varianz jeder latenten Dimension aus). Da der VAE-Encoder eine Verteilung erzeugt, können die neuen Daten durch Abtasten dieser Verteilung und Übergeben des abgetasteten latenten Vektors an den Decoder generiert werden. Durch die Stichprobenerhebung aus der erzeugten Verteilung zur Generierung von Ausgabebildern ermöglicht VAE die Generierung neuartiger Daten, die den Eingabedaten ähnlich, aber mit ihnen identisch sind. Dieser Artikel untersucht Komponenten der VAE-Architektur und bietet verschiedene Möglichkeiten zum Generieren neuer Bilder (Sampling) mit VAE-Modellen. Der gesamte Code ist in verfügbar. Google Colab 1 VAE-Modellimplementierung Autoencoder und Variations-Autoencoder bestehen beide aus zwei Teilen: Encoder und Decoder. Das neuronale Encoder-Netzwerk von AE lernt, jedes Bild einem einzelnen Vektor im latenten Raum zuzuordnen, und der Decoder lernt, das Originalbild aus dem codierten latenten Vektor zu rekonstruieren. Das Encoder-Neuronale Netzwerk von VAE gibt Parameter aus, die eine Wahrscheinlichkeitsverteilung für jede Dimension des latenten Raums definieren (multivariate Verteilung). Für jede Eingabe erzeugt der Encoder einen Mittelwert und eine Varianz für jede Dimension des latenten Raums. Der Ausgabemittelwert und die Varianz werden verwendet, um eine multivariate Gaußsche Verteilung zu definieren. Das neuronale Netzwerk des Decoders ist das gleiche wie in AE-Modellen. 1.1 VAE-Verluste Das Ziel des Trainings eines VAE-Modells besteht darin, die Wahrscheinlichkeit der Generierung realer Bilder aus bereitgestellten latenten Vektoren zu maximieren. Während des Trainings minimiert das VAE-Modell zwei Verluste: – die Differenz zwischen den Eingabebildern und der Ausgabe des Decoders. Rekonstruktionsverlust (KL-Divergenz, ein statistischer Abstand zwischen zwei Wahrscheinlichkeitsverteilungen) – der Abstand zwischen der Wahrscheinlichkeitsverteilung der Ausgabe des Encoders und einer vorherigen Verteilung (einer Standardnormalverteilung), der zur Regularisierung des latenten Raums beiträgt. Kullback-Leibler-Divergenzverlust 1.2 Rekonstruktionsverlust Häufige Rekonstruktionsverluste sind binäre Kreuzentropie (BCE) und mittlerer quadratischer Fehler (MSE). In diesem Artikel werde ich den MNIST-Datensatz für die Demo verwenden. MNIST-Bilder haben nur einen Kanal und Pixel nehmen Werte zwischen 0 und 1 an. In diesem Fall kann der BCE-Verlust als Rekonstruktionsverlust verwendet werden, um Pixel von MNIST-Bildern als binäre Zufallsvariable zu behandeln, die der Bernoulli-Verteilung folgt. reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 Kullback-Leibler-Divergenz Wie oben erwähnt, bewertet die KL-Divergenz den Unterschied zwischen zwei Verteilungen. Beachten Sie, dass es keine symmetrische Eigenschaft eines Abstands hat: KL(P‖Q)!=KL(Q‖P). Die beiden Verteilungen, die verglichen werden müssen, sind: der latente Raum der Encoderausgabe bei gegebenen Eingabebildern x: q(z|x) Latentraum vor , der als Normalverteilung mit einem Mittelwert von Null und einer Standardabweichung von Eins in jeder Latentraumdimension angenommen wird. p(z) N(0, ) I Eine solche Annahme vereinfacht die KL-Divergenzberechnung und fördert, dass der latente Raum einer bekannten, beherrschbaren Verteilung folgt. from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 Encoder class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1,5 Decoder class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 VAE-Modell Um eine Rückwärtsausbreitung durch eine Zufallsstichprobe durchzuführen, müssen Sie die Parameter der Zufallsstichprobe ( und 𝝈) aus der Funktion verschieben, um die Gradientenberechnung durch die Parameter zu ermöglichen. Dieser Schritt wird auch „Reparametrisierungstrick“ genannt. μ In PyTorch können Sie eine mit der Ausgabe und 𝝈 des Encoders erstellen und daraus mit der Methode eine Probe abtasten, die den Reparametrisierungstrick implementiert: Es ist dasselbe wie Normalverteilung μ rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 Training eines VAE Laden Sie MNIST-Zug- und Testdaten. transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) Erstellen Sie eine Trainingsschleife, die den in der Abbildung oben dargestellten VAE-Trainingsschritten folgt. def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 Visualisieren Sie den latenten Raum def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 Probenahme mit VAE Die Abtastung durch einen Variational Autoencoder (VAE) ermöglicht die Generierung neuer Daten, die denen während des Trainings ähneln, und ist ein einzigartiger Aspekt, der VAE von der herkömmlichen AE-Architektur unterscheidet. Es gibt verschiedene Möglichkeiten, Proben aus einem VAE zu entnehmen: Stichprobe aus der Posterior-Verteilung bei gegebener Eingabe. Posterior-Stichprobe: Probenahme aus dem latenten Raum unter Annahme einer standardmäßigen multivariaten Normalverteilung. Dies ist aufgrund der (während des VAE-Trainings verwendeten) Annahme möglich, dass die latenten Variablen normalverteilt sind. Diese Methode erlaubt nicht die Generierung von Daten mit bestimmten Eigenschaften (z. B. die Generierung von Daten aus einer bestimmten Klasse). Vorherige Probenahme: : Die Interpolation zwischen zwei Punkten im Latentraum kann zeigen, wie Änderungen in der Latentraumvariablen Änderungen in den generierten Daten entsprechen. Interpolation : Durchquerung latenter Dimensionen des latenten VAE-Raums. Die Varianz der Daten hängt von jeder Dimension ab. Die Durchquerung erfolgt durch Fixieren aller Dimensionen des latenten Vektors mit Ausnahme einer ausgewählten Dimension und durch Variieren der Werte der ausgewählten Dimension in ihrem Bereich. Einige Dimensionen des latenten Raums können bestimmten Attributen der Daten entsprechen (VAE verfügt nicht über spezifische Mechanismen, um dieses Verhalten zu erzwingen, es kann jedoch vorkommen). Durchquerung latenter Dimensionen Beispielsweise kann eine Dimension im latenten Raum den emotionalen Ausdruck eines Gesichts oder die Ausrichtung eines Objekts steuern. Jede Stichprobenmethode bietet eine andere Möglichkeit, die vom latenten Raum der VAE erfassten Dateneigenschaften zu untersuchen und zu verstehen. 2.1 Posterior-Sampling (von einem gegebenen Eingabebild) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) Posterior Sampling ermöglicht die Generierung realistischer Datenstichproben, jedoch mit geringer Variabilität: Die Ausgabedaten ähneln den Eingabedaten. 2.2 Vorherige Abtastung (aus einem zufälligen latenten Raumvektor) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) Eine vorherige Probenahme mit N(0, ) liefert nicht immer plausible Daten, weist jedoch eine hohe Variabilität auf. I 2.3 Stichprobe aus Klassenzentren Mittlere Kodierungen jeder Klasse können aus dem gesamten Datensatz akkumuliert und später für eine kontrollierte (bedingte) Generierung verwendet werden. def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') Die Stichprobe aus einer Normalverteilung mit der gemittelten Klasse μ garantiert die Generierung neuer Daten aus derselben Klasse. 2.4 Interpolation def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 Interpolation zwischen zwei zufälligen latenten Vektoren start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 Interpolation zwischen zwei Klassenzentren for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 Latente Raumdurchquerung Jede Dimension des latenten Vektors stellt eine Normalverteilung dar; Der Wertebereich der Dimension wird durch den Mittelwert und die Varianz der Dimension gesteuert. Eine einfache Möglichkeit, den Wertebereich zu durchlaufen, wäre die Verwendung der inversen CDF (kumulativen Verteilungsfunktionen) der Normalverteilung. ICDF nimmt einen Wert zwischen 0 und 1 (der die Wahrscheinlichkeit darstellt) und gibt einen Wert aus der Verteilung zurück. Für eine gegebene Wahrscheinlichkeit gibt ICDF einen Wert aus, sodass die Wahrscheinlichkeit, dass eine Zufallsvariable <= ist, gleich der gegebenen Wahrscheinlichkeit ist?“ p p_icdf- p_icdf p Wenn Sie eine Normalverteilung haben, sollte icdf(0.5) den Mittelwert der Verteilung zurückgeben. icdf(0.95) sollte einen Wert zurückgeben, der größer als 95 % der Daten aus der Verteilung ist. 2.5.1 Eindimensionale latente Raumdurchquerung def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') Das Durchlaufen einer einzelnen Dimension kann zu einer Änderung des Ziffernstils oder der Ausrichtung der Kontrollziffern führen. 2.5.3 Zweidimensionale latente Raumdurchquerung def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') Das gleichzeitige Durchlaufen mehrerer Dimensionen bietet eine kontrollierbare Möglichkeit, Daten mit hoher Variabilität zu generieren. 2.6 Bonus – 2D-Ziffernvielfalt aus dem latenten Raum Wenn ein VAE-Modell mit ist es möglich, eine 2D-Mannigfaltigkeit von Ziffern aus seinem latenten Raum anzuzeigen. Dazu verwende ich mit und . =2 trainiert wird, z_dim die Funktion traverse_two_latent_dimensions =0 dim_1 =2 dim_2 vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')