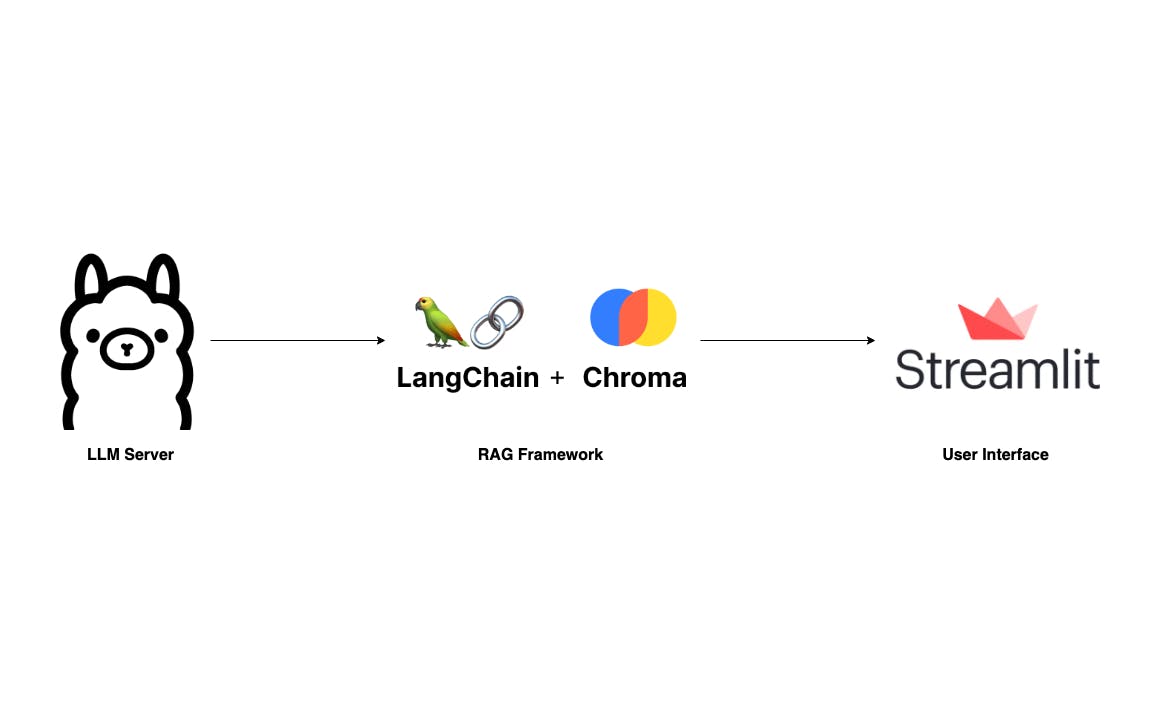
Avec l'essor des grands modèles de langage et leurs capacités impressionnantes, de nombreuses applications sophistiquées sont construites sur des fournisseurs LLM géants comme OpenAI et Anthropic. Le mythe derrière de telles applications est le framework RAG, qui a été expliqué en détail dans les articles suivants : Création d'applications LLM basées sur RAG pour la production La génération augmentée de récupération (RAG) expliquée : comprendre les concepts clés Qu'est-ce que la génération augmentée par récupération ? Pour vous familiariser avec RAG, je vous recommande de parcourir ces articles. Cependant, cet article ignorera les bases et vous guidera directement dans la création de votre propre application RAG pouvant s'exécuter localement sur votre ordinateur portable sans vous soucier de la confidentialité des données et du coût des jetons. Nous allons créer une application similaire à F mais plus simple. Où les utilisateurs peuvent télécharger un document PDF et poser des questions via une interface utilisateur simple. Notre pile technologique est très simple avec Langchain, Ollama et Streamlit. ChatPD : Le composant le plus critique de cette application est le serveur LLM. Grâce à , nous disposons d'un serveur LLM robuste qui peut être configuré localement, même sur un ordinateur portable. Alors que est une option, je trouve Ollama, écrit en Go, plus facile à configurer et à exécuter. Serveur LLM Ollama lama.cpp : Sans aucun doute, les deux bibliothèques leaders dans le domaine LLM sont et . Pour ce projet, j'utiliserai Langchain en raison de ma familiarité avec celui-ci grâce à mon expérience professionnelle. Un composant essentiel de tout framework RAG est le stockage vectoriel. Nous utiliserons ici, car il s'intègre bien à Langchain. RAG Langchain LLamIndex Chroma : L’interface utilisateur est également un composant important. Bien qu'il existe de nombreuses technologies disponibles, je préfère utiliser , une bibliothèque Python, pour votre tranquillité d'esprit. Chat UI Rationalisé D'accord, commençons à le configurer. Configurer Ollama Comme mentionné ci-dessus, la configuration et l'exécution d'Ollama sont simples. Première visite et téléchargez l'application adaptée à votre système d'exploitation. ollama.ai Ensuite, ouvrez votre terminal et exécutez la commande suivante pour extraire la dernière version . Alors qu'il en existe bien d'autres , j'ai choisi Mistral-7B pour sa taille compacte et sa qualité compétitive. Mistral-7B Modèles LLM disponibles ollama pull mistral Ensuite, exécutez pour vérifier si le modèle a été extrait correctement. La sortie du terminal doit ressembler à ce qui suit : ollama list Maintenant, si le serveur LLM n'est pas déjà en cours d'exécution, lancez-le avec . Si vous rencontrez un message d'erreur du type , cela indique que le serveur est déjà en cours d'exécution par défaut et que vous pouvez passer à l'étape suivante. ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" Construire le pipeline RAG La deuxième étape de notre processus consiste à créer le pipeline RAG. Compte tenu de la simplicité de notre application, nous avons principalement besoin de deux méthodes : et . ingest ask La méthode accepte un chemin de fichier et le charge dans le stockage vectoriel en deux étapes : premièrement, elle divise le document en morceaux plus petits pour s'adapter à la limite de jetons du LLM ; Deuxièmement, il vectorise ces morceaux à l'aide de Qdrant FastEmbeddings et les stocke dans Chroma. ingest La méthode gère les requêtes des utilisateurs. Les utilisateurs peuvent poser une question, puis RetrievalQAChain récupère les contextes pertinents (morceaux de documents) à l'aide de techniques de recherche de similarité vectorielle. ask Avec la question de l'utilisateur et les contextes récupérés, nous pouvons composer une invite et demander une prédiction au serveur LLM. from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None L'invite provient du hub Langchain : . Cette invite a été testée et téléchargée des milliers de fois, constituant une ressource fiable pour en savoir plus sur les techniques d'invite LLM. Langchain RAG Invite pour Mistral Vous pouvez en savoir plus sur les techniques d'invite LLM . ici Plus de détails sur la mise en œuvre : : Nous utilisons PyPDFLoader pour charger le fichier PDF téléchargé par l'utilisateur. Le RecursiveCharacterSplitter, fourni par Langchain, divise ensuite ce PDF en morceaux plus petits. Il est important de filtrer les métadonnées complexes non prises en charge par ChromaDB à l'aide de la fonction de Langchain. ingest filter_complex_metadata Pour le stockage vectoriel, Chroma est utilisé, associé à comme notre modèle d'intégration. Ce modèle léger est ensuite transformé en un récupérateur avec un seuil de score de 0,5 et k=3, ce qui signifie qu'il renvoie les 3 premiers morceaux avec les scores les plus élevés supérieurs à 0,5. Enfin, nous construisons une chaîne de conversation simple en utilisant . Qdrant FastEmbed LECL : Cette méthode transmet simplement la question de l'utilisateur dans notre chaîne prédéfinie puis renvoie le résultat. ask : Cette méthode est utilisée pour effacer la session de discussion et le stockage précédents lorsqu'un nouveau fichier PDF est téléchargé. clear Rédiger une interface utilisateur simple Pour une interface utilisateur simple, nous utiliserons , un framework d'interface utilisateur conçu pour le prototypage rapide d'applications IA/ML. Rationalisé import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() Exécutez ce code avec la commande pour voir à quoi il ressemble. streamlit run app.py D'accord, c'est tout ! Nous disposons désormais d'une application ChatPDF qui fonctionne entièrement sur votre ordinateur portable. Étant donné que cet article se concentre principalement sur la fourniture d’un aperçu de haut niveau de la façon de créer votre propre application RAG, plusieurs aspects doivent être peaufinés. Vous pouvez envisager les suggestions suivantes pour améliorer votre application et développer davantage vos compétences : : actuellement, il ne se souvient pas du flux de conversation. L'ajout de mémoire temporaire aidera votre assistant à prendre conscience du contexte. Ajouter de la mémoire à la chaîne de conversation : vous pouvez discuter d'un seul document à la fois. Mais imaginez si nous pouvions discuter de plusieurs documents : vous pourriez y mettre toute votre bibliothèque. Ce serait super cool ! Autoriser plusieurs téléchargements de fichiers : Bien que Mistral soit efficace, il existe de nombreuses autres alternatives disponibles. Vous trouverez peut-être un modèle mieux adapté à vos besoins, comme LlamaCode pour les développeurs. N'oubliez cependant pas que le choix du modèle dépend de votre matériel, notamment de la quantité de RAM dont vous disposez 💵 Utiliser d'autres modèles LLM : il y a de la place pour l'expérimentation au sein de RAG. Vous souhaiterez peut-être modifier la métrique de récupération, le modèle d'intégration,... ou ajouter des couches comme un reclassement pour améliorer les résultats. Améliorez le pipeline RAG Enfin, merci d'avoir lu. Si vous trouvez ces informations utiles, pensez à vous abonner à mon ou mon personnel . J'ai l'intention d'écrire davantage sur les applications RAG et LLM, et vous pouvez suggérer des sujets en laissant un commentaire ci-dessous. Acclamations! Sous-pile Blog Code source complet : https://github.com/vndee/local-rag-example