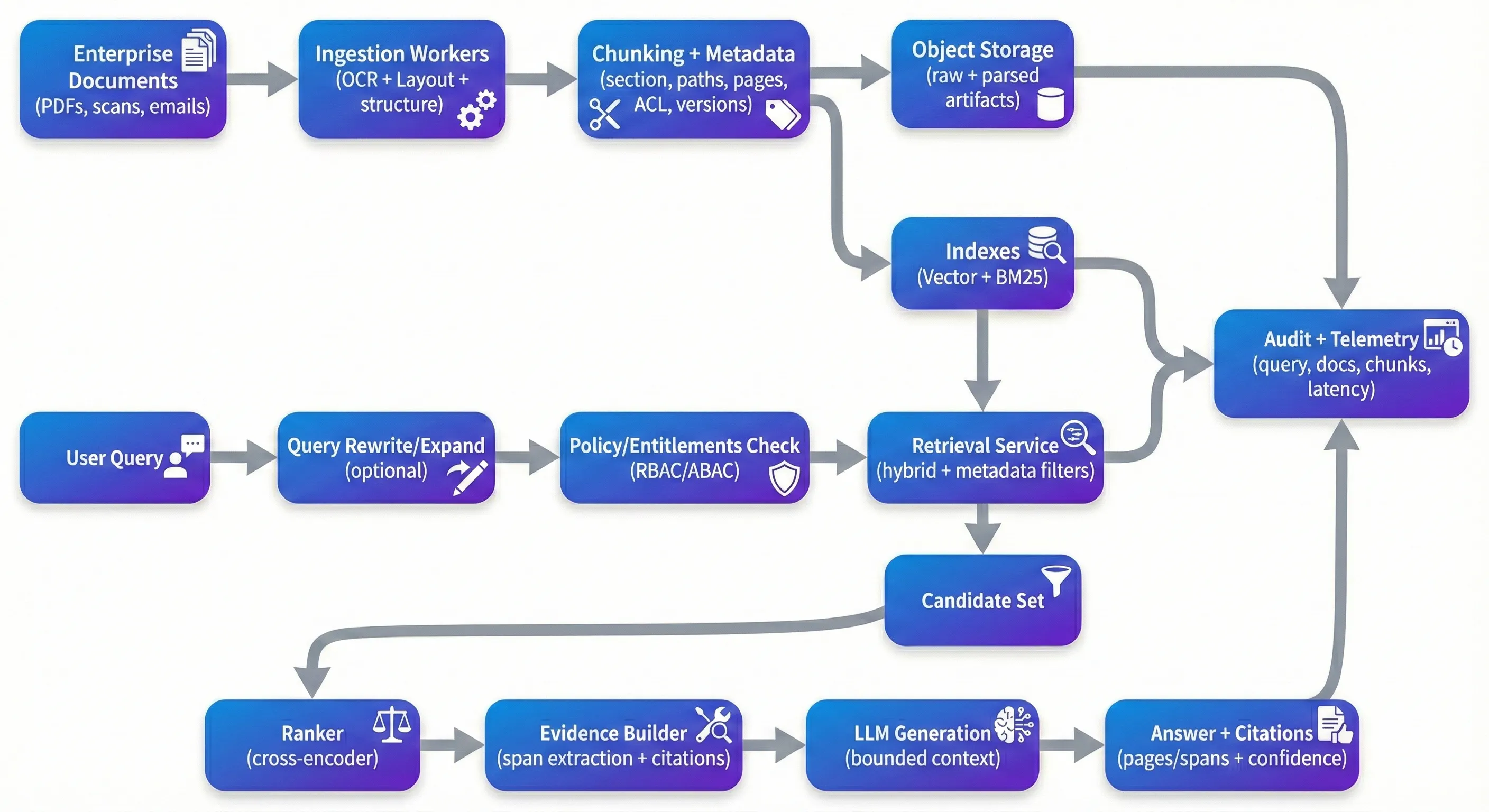
RAG ist überall – und das ist nicht verwunderlich. Es ist eine der praktischsten Möglichkeiten, um große Dokumentensammlungen nachzuforschen, ohne brüchige, domänenspezifische Parsern für jede Frage zu bauen. Der Eindruck ist, dass das, was in einer kontrollierten Demo funktioniert, oft schnell abbaut, wenn man es vor echten Enterprise-PDFs stellt: gescannte Verträge, Compliance-Dateien, medizinische Aufzeichnungen, Richtlinien und die lange Schlange von Layout- und Qualitätsproblemen, die mit ihnen einhergehen. Wenn Teams feststecken, liegt es selten daran, dass die Vektorsuche „nicht funktioniert“. Es liegt daran, dass das System nicht konsequent Antworten auf die richtigen Beweise begründen kann, Rechte nicht zuverlässig durchsetzen kann oder nicht ausgewertet und verbessert werden kann, ohne Dinge zu brechen. The Demo Trap Die Demo-Falle Die meisten Prototypen folgen dem gleichen Weg: Dokumenten in einen Vektorladen werfen, Top-K-Stücke abrufen und einen LLM bitten, sie zu synthetisieren. Auf sauberen, gut strukturierten Texten kann dies hervorragend aussehen. Das Problem ist, was als nächstes passiert. Scannte PDFs kommen in Rotation oder Verzerrung. Die Reihenfolge des Lesens in mehreren Spalten wird gestört. Tabellen verlieren während der Extraktion Struktur. Chunking spaltet das Argument in der Mitte. Retrieval gibt den Kontext "zu nah" zurück, der plausibel liest, aber den Anspruch nicht wirklich unterstützt. Und das Modell, das zu tun, was es optimiert ist, antwortet fließend. In der Produktion optimieren Sie für andere Eigenschaften als eine Demo. Sie möchten, dass das System über unkomplizierte Eingänge zuverlässig ist, über Pipeline-Änderungen reproduzierbar und unter Kontrolle verteidbar ist. Das bedeutet, dass Sie eine Antwort auf spezifische Beweise zurückverfolgen können und starke Standards haben, wenn Beweise schwach sind: Fragen klären, Ablehnungsverhalten oder "beste verfügbare Beweise" mit expliziter Unsicherheit präsentieren. Ingestion: Where Quality Is Won or Lost Einnahme: Wo Qualität gewonnen oder verloren geht Wenn Sie ein paar dieser Systeme gebaut haben, lernen Sie schnell, dass die Einnahme die Wiederherstellungsqualität mehr als die meisten nachgelagerten Tricks bestimmt. Die Dokument-AI-Vorverarbeitung ist nicht glamourös, aber es ist, wo Sie entweder die Struktur bewahren – oder sie dauerhaft verlieren. Für Unternehmensdokumente reicht OCR allein nicht aus; Sie benötigen normalerweise OCR mit Layout-Erkennung, Lesebestimmungsrekonstruktion und Struktur-Extraktion, die Überschriften, Abschnitte und Tabellen sinnvoll hält. Verwaltete Tools wie Google Document AI, Azure Document Intelligence und Amazon Textract können viel Boden bedecken. Chunking ist, wo Teams oft die Komplexität unterschätzen. Ein einfacher Charakter oder Token-Split ist schnell, aber es neigt dazu, semantische Grenzen zu schneiden – genau die Grenzen, die Benutzer in Verträgen und Richtlinien interessieren. Adaptives Chunking, das Überschriften, Abschnittsgrenzen und Tabellengrenzen folgt, verbessert in der Regel sowohl das Abrufen als auch die nach unten liegende Grundlegung. Es macht auch die Herkunft für den Endnutzer natürlich: Anstatt eine opache interne ID wie chunk_4892 aufzuzeigen, können Sie auf etwas hinweisen, das ein Reviewer sofort überprüfen kann – „MSA v3.2 → Abschnitt 9 (Abschluss) → 9.2 (Abschluss für Ursache), Seite 12, Zeilen 14– Metadaten sind ein weiterer Bereich, der dazu neigt, optional auszusehen, bis Sie es benötigen. In der Praxis sind Metadaten das, was Filterung, Rückverfolgbarkeit und Reproduzierbarkeit ermöglicht. Nützliche Metadaten auf Teilebene umfassen in der Regel Dokument-IDs, Abschnittswege, Seitenzahlen, Zeitstempel (wirksames Datum, zuletzt modifiziert, aufgenommen), Extraktionssicherheitssignale und Versionsidentifikatoren (Dokument-Hash, Chunking-Version, Embedding-Modell-Version). In Unternehmenskontexten müssen Access-Control-Attribute (Vermieter, Abteilung, Vertraulichkeit, Rollen-Tags) erstklassig sein, da sie die Abrufe und Audits direkt einschränken. The Retrieval Stack That Actually Works Der Retrieval Stack, der wirklich funktioniert Die Suche nach Vektorähnlichkeit ist eine gute Ausgangslinie, aber es ist selten ausreichend für Unternehmensdokumente.In der Praxis ist Hybrid-Recovery - dichte Embeddings plus sparse lexische Recovery wie BM25 - neigt dazu, robuster zu sein, insbesondere wenn Benutzer mit Klauselnummern, Identifikatoren, Akronymen oder exaktem Ausdruck abfragen.Dense-Recovery behandelt die semantische Absicht gut; sparse-Recovery-Anker ermöglicht es Ihnen, exakte Begriffe und seltene Token zu verwenden, die Embeddings oft glatt überwinden. Re-Ranking ist oft der Ort, an dem Systeme den größten Sprung in der wahrgenommenen Qualität machen, nicht weil es magisch ist, sondern weil es einen gemeinsamen Fehlermodus behebt: Das erste Recovery-Set enthält "Kinda-relevante" Stücke, und Sie müssen die wirklich relevanten Stücke an die Spitze bringen. Cross-encoder-Re-Rankers (offene Modelle wie bge-reranker oder verwaltete APIs wie Cohere ranker) rescore Kandidatenstücke mit tieferer Abfrage-Passage-Interaktion. Teams sehen normalerweise einen spürbaren Aufstieg in der Kontextgenauigkeit, wenn die Re-Ranking richtig gemessen wird (z. B. auf einem goldenen Set mit erwarteten Quellen). Wenn Sie hier eine quantitative Behauptung Umschreibung und Erweiterung von Abfragen ist ein weiterer Hebel, der leicht zu früh überspringen und später wiederentdecken ist. Benutzer formulieren Fragen nicht auf natürliche Weise, wie Dokumente geschrieben werden. Ein Umschreibungsschritt kann Akronymen erweitern, Entitäten normalisieren und mehrteilige Fragen in abruffreundliche Unterabfragen aufteilen. Es muss nicht fancy sein - aber es braucht Beobachtbarkeit, da unkontrolliertes Umschreiben von der Absicht des Benutzers abweichen kann. Security: The Layer Everyone Forgets Sicherheit: Die Schicht, die jeder vergisst Die meisten RAG-Demos ignorieren die Zugriffskontrolle, weil sie den Prototyp verlangsamt.In der Produktion ist es eine primäre Einschränkung.Wenn Ihr System HR-Dokumente, rechtliche Verträge und technische Spezifikationen zusammen indexiert, benötigen Sie einen deterministischen Berechtigungsweg von Benutzern → erlaubte Stücke, und das Abrufen muss durch diesen Weg eingeschränkt werden, bevor jeglicher Inhalt ein LLM erreicht. Das Muster, das dazu neigt, zu skalieren, ist vorfiltertes Abrufen: Berechnungsberechtigungen (RBAC/ABAC), nur von Stücken mit kompatiblen ACL-Attributen abrufen, innerhalb des autorisierten Kandidaten-Sets neu verankern und protokollieren, auf welche Beweise zugegriffen wurde. Abgesehen von ACL benötigen Unternehmensimplementierungen in der Regel eine Kombination aus PII-Erkennung/Masken, Verschlüsselung bei Ruhe, kurzlebigen Token für den Quellzugriff und Audit-Logging, das Abfragen, abgerufene Teil-IDs, Zitate und Dokumentversionen erfasst.Eine weitere moderne Sorge, die ernst zu nehmen lohnt, ist die sofortige Injektion von Inhalten innerhalb von Dokumenten.Sie müssen nicht jedes Dokument als feindselig behandeln, aber Sie benötigen grundlegende Warteschlangen, so dass Anweisungen, die in Quelltext eingebettet sind, die Regeln Ihres Systems nicht ersetzen können - vor allem rund um Zugriff, Offenlegung und wie sich das Modell verhalten darf. Monitoring: Closing the Loop Überwachung: Schließen der Schleife Wenn Sie eines dieser Systeme länger als ein paar Wochen betreiben, sehen Sie einen Drift.Dokumente ändern sich, die Abfrageverteilung ändert sich, die Einnahmeleitung ändert sich und die Modellkomponenten werden aktualisiert. Praktisch möchten Sie die Gesundheitszufriedenheit verfolgen (Recall@k gegenüber einem goldenen Set, Kontextpräzision, Ranger Lift), die Gesundheitszufriedenheit der Generation (Zitierungspräzision, Gründungs-/Glaubwürdigkeitsprüfungen, Ablehnungsraten) und die Betriebsgesundheit (p50/p95 Latenz, Kosten pro Abfrage, Verzögerung bei der Aktualisierung von Dokumenten bis zum Suchbaren Index). Die effektivsten Teams, die ich gesehen habe, pflegen einen goldenen Bewertungsdatensatz – ausgewertete Fragen mit erwarteten Quelldokumenten – und führen sie nach einem Zeitplan und bei Änderungsereignissen (neue Einbettungen, neue Chunking-Logik, neue Dokumentenbatches). Ein Bereich, der oft unterschätzt wird, ist Versionierung und Reproduzierbarkeit.Wenn Sie OCR-Modelle ändern, Logik schneiden, Modelle einbauen, Rerankern oder Generationsanweisungen verwenden, benötigen Sie eine Möglichkeit, zu verfolgen, welche Versionen produziert haben, welche Antworten. Choosing Your Stack Wählen Sie Ihren Stack Stapelentscheidungen sind wichtig, aber Fähigkeiten sind wichtiger. Für viele Teams ist eine verwaltete Einstellung attraktiv: Einnahme über ein verwaltetes Document AI-Tool oder eine unstrukturierte Pipeline, eine gehostete Vektordatenbank, eine Orchestrierungsschicht wie LlamaIndex oder LangChain und ein Re-Ranker (öffnet oder verwaltet). Andere bevorzugen Open-Source-Einführungen mit Qdrant/Weaviate/OpenSearch, Haystack oder ähnlicher Orchestrierung und selbst gehostete Modelle für Kontrolle und Kostenvorhersehbarkeit. Beide Ansätze können funktionieren, wenn sie die Grundlagen unterstützen: Dokumentbewusste Einnahme, hybride Wiederherstellung, Rechtsdurchsetzung, herkunftfreundliche Zitate, Bewertung Auf der Architekturseite neigen Systeme dazu, leichter zu funktionieren, wenn sie sauber aufgeteilt sind: Einnahmearbeiter, die asynchron laufen und sicher wiederhergestellt werden können; ein statloser Abrufdienst, der Richtlinien durchsetzt und Beweise zurückgibt; und ein Generationsservice, der mit begrenztem Kontext und klarer Herkunft arbeitet.Eine typische Referenzimplementierung umfasst ein API-Gateway, eine Job-Quelle (Kafka/RabbitMQ), Objektspeicherung für Rohdokumente und geprüfte Artefakte, die Indexschicht ( +dense sparse), sowie zentralisierte Logging/Metrics und eine Auditspur.