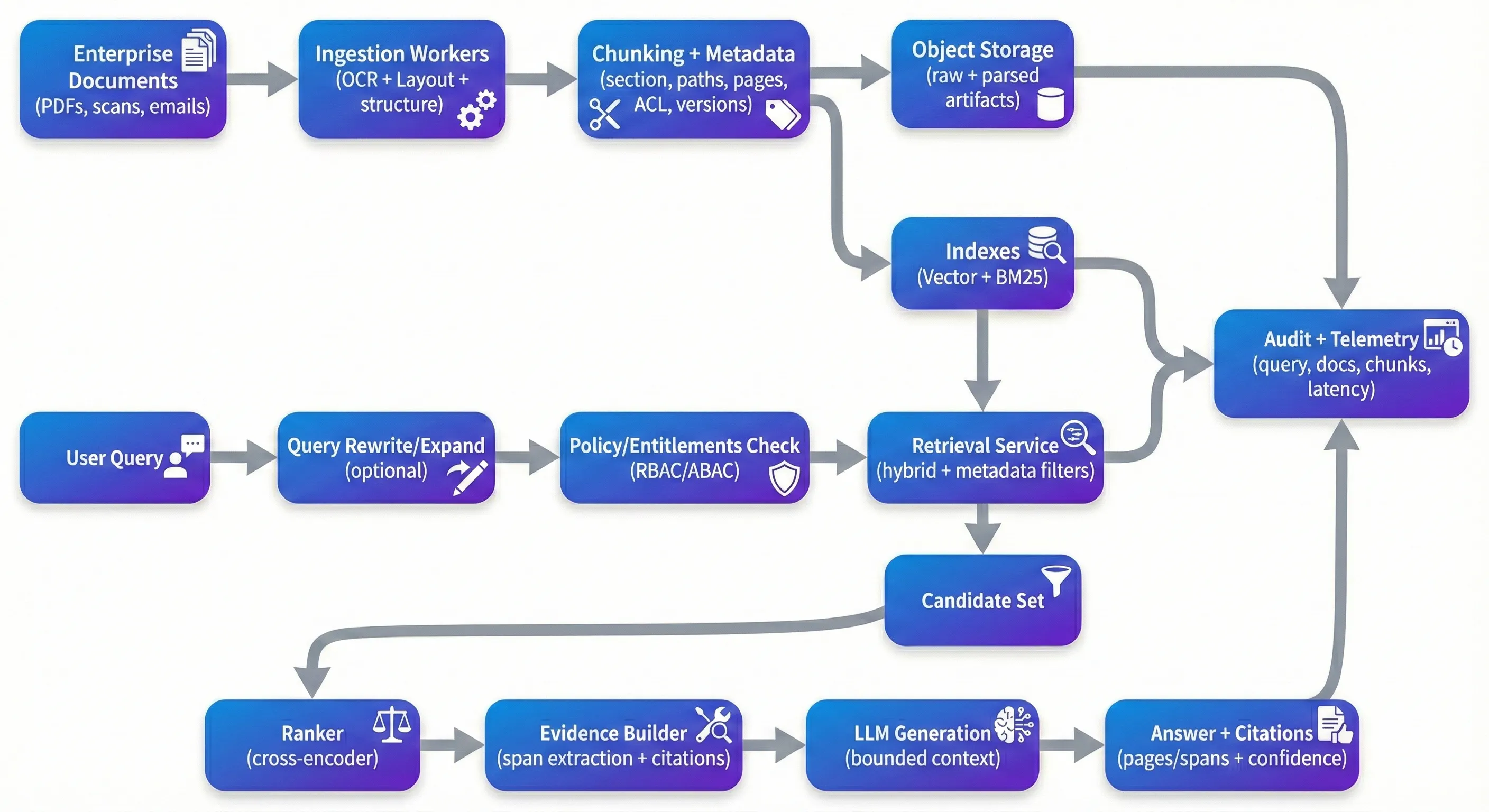
RAG está en todas partes, y eso no es sorprendente. Es una de las maneras más prácticas de hacer que las grandes colecciones de documentos sean consultables sin construir parsers frágiles y específicos de dominio para cada tipo de pregunta. La impresión es que lo que funciona en una demostración controlada a menudo se degrada rápidamente cuando se coloca delante de los PDF corporativos reales: contratos escaneados, archivos de cumplimiento, registros médicos, políticas y la larga cola de problemas de diseño y calidad que vienen con ellos. En la producción, el “problema RAG” es menos acerca de la solicitud inteligente y más acerca de la repetibilidad: trazabilidad, seguridad, controles de calidad y la capacidad de explicar por qué una respuesta es correcta (o por qué el sistema se negó). Cuando los equipos se atrapan, rara vez es porque la búsqueda vectorial "no funciona".Es porque el sistema no puede fundamentar constantemente las respuestas a la evidencia correcta, no puede hacer cumplir los derechos de manera fiable, o no puede ser evaluado y mejorado sin romper las cosas.Si no puede decirle a una parte interesada qué versión de qué documento respaldó una reclamación -o probar que el usuario estaba autorizado a verla- aún no tiene un producto. The Demo Trap La trampa de la demo La mayoría de los prototipos siguen el mismo camino: descargar documentos en una tienda vectorial, recuperar fragmentos de top-k y pedir a un LLM que sintetice. En un texto limpio y bien estructurado, esto puede parecer excelente. El problema es lo que sucede a continuación. Los PDF escaneados vienen en roto o desviados. El orden de lectura de varias columnas se vuelve confuso. Las tablas pierden estructura durante la extracción. El chunking divide el argumento medio. El retrieval devuelve el contexto “lo suficientemente cercano” que lee plausiblemente pero no apoya realmente la afirmación. Y el modelo, haciendo lo que está optimizado para hacer, responde fluidamente de todos modos. En la producción, estás optimizando para diferentes propiedades que una demostración.Quieres que el sistema sea confiable sobre entradas desordenadas, reproducible a través de cambios de tubería y defensible bajo control.Esto significa poder rastrear una respuesta de nuevo a evidencias específicas, y tener fuertes defectos cuando la evidencia es débil: aclarar preguntas, comportamiento de rechazo, o presentar "la mejor evidencia disponible" con incertidumbre explícita.También significa tratar el control de acceso como parte de la recuperación -no como un pensamiento posterior estratificado en la IU. Ingestion: Where Quality Is Won or Lost Ingestión: donde la calidad se gana o se pierde Si ha construido algunos de estos sistemas, aprende rápidamente que la ingestión determina la calidad de la recuperación más que la mayoría de los trucos subterráneos. El preprocesamiento de IA de documentos no es glamuroso, pero es donde se conserva la estructura o se pierde permanentemente. Para documentos empresariales, el OCR solo no es suficiente; generalmente se necesita OCR con detección de diseño, reconstrucción de orden de lectura y extracción de estructura que mantenga los encabezados, secciones y tablas significativos. Herramientas gestionadas como Google Document AI, Azure Document Intelligence y Amazon Textract pueden cubrir mucho terreno. Chunking es donde los equipos a menudo subestiman la complejidad. Una simple división de caracteres o token es rápida, pero tiende a cortar los límites semánticos – exactamente los límites que los usuarios se preocupan en los contratos y las políticas. El chunking adaptativo que sigue los encabezados, los límites de la sección y los límites de la tabla suele mejorar tanto la búsqueda como el aterrizaje a continuación. También hace que la procedencia se sienta natural para el usuario final: en lugar de mostrar un identificador interno opaco como chunk_4892, puede apuntar a algo que un revisor puede verificar inmediatamente: “MSA v3.2 → Sección 9 (Termination) → 9.2 (Termination for Cause), página 12, líneas 14-22.” Los metadatos son otra área que tiende a parecer opcional hasta que lo necesites. En la práctica, los metadatos son lo que hace posible la filtración, la trazabilidad y la reproductibilidad. Los metadatos útiles a nivel de piezas a menudo incluyen ID de documento, caminos de sección, números de página, timestamps (data efectiva, última modificación, ingesta), señales de confianza de extracción e identificadores de versión (hash de documento, versión de chunking, versión de modelo de embedding). En contextos empresariales, los atributos de control de acceso (arrendatario, departamento, confidencialidad, etiquetas de roles) deben ser de primera clase, porque restringen directamente la recuperación y las auditorías. The Retrieval Stack That Actually Works La pila de recuperación que realmente funciona La búsqueda de semejanza vectorial es una buena línea de partida, pero rara vez es suficiente por sí sola para los documentos de la empresa. En la práctica, la recuperación híbrida —incorporaciones densas y recuperación léxica escasa como BM25— tiende a ser más robusta, especialmente cuando los usuarios consultan con números de cláusulas, identificadores, acrónimos o frases exactas. La recuperación densa maneja bien la intención semántica; la recuperación escasa le permite anclar términos exactos y tokens raros que las incorporaciones a menudo suavizan. El reencuentro es a menudo donde los sistemas hacen el mayor salto en la calidad percibida, no porque sea mágico, sino porque fija un modo de fallo común: el conjunto inicial de recuperación contiene fragmentos "kinda relevantes" y necesita promover a los realmente relevantes a la parte superior. Los reencuentros de codificadores cruzados (modelos abiertos como bge-reranker o APIs gestionadas como Cohere ranker) rescatan fragmentos de candidatos usando una interacción interrogación-paso más profunda. Los equipos suelen ver un notable aumento en la precisión del contexto cuando se mide correctamente el reencuentro (por ejemplo, en un conjunto de oro con fuentes esperadas). Si mantiene una afirmación cuantitativa aquí, es mejor vincularla a una métrica ("precisión de contexto" o " La reescritura y la expansión de consultas es otra herramienta que es fácil de saltar temprano y luego redescubrir más tarde. Los usuarios no expresan naturalmente las preguntas de la manera en que se escriben los documentos. Un paso de reescritura puede expandir los acrónimos, normalizar entidades y dividir las preguntas multipartes en subcuerdas amigables para la búsqueda. No necesita ser fantástico, pero necesita observabilidad, ya que la reescritura no controlada puede desplazarse de la intención del usuario. Security: The Layer Everyone Forgets Seguridad: la capa que todo el mundo olvida La mayoría de las demostraciones de RAG ignoran el control de acceso porque ralentiza el prototipo.En la producción, es una restricción primaria.Si su sistema indexa documentos de recursos humanos, contratos legales y especificaciones de ingeniería juntos, necesita un camino determinista de derechos del usuario → fragmentos permitidos, y la recuperación debe ser restringida por ese camino antes de que cualquier contenido llegue a un LLM. El patrón que tiende a escalar es la búsqueda pre-filtrada: los derechos de computación (RBAC/ABAC), la búsqueda sólo de fragmentos con atributos ACL compatibles, el reencuentro dentro del conjunto de candidatos autorizados y el registro de qué evidencia se accedió. Más allá de ACL, las implementaciones empresariales normalmente necesitan una combinación de detección/mascarado de PII, cifrado en reposo, tokens de corta vida para el acceso a la fuente y logging de auditoría que captura consultas, identificadores de pedazos recuperados, citas y versiones de documentos. Una preocupación más moderna que vale la pena tomar en serio es el contenido de inyección rápida dentro de los documentos. No necesita tratar cada documento como hostil, pero necesita guarderías básicas para que las instrucciones incorporadas en el texto de fuente no puedan reemplazar las reglas de su sistema, especialmente en torno al acceso, el control y la forma en que se permite que el modelo se comporte. Monitoring: Closing the Loop Título: Cierra el ciclo Si opera uno de estos sistemas durante más de unas pocas semanas, verá la deriva. los documentos cambian, la distribución de la consulta cambia, el tubo de ingestión cambia y los componentes del modelo se actualizan. Prácticamente, desea rastrear la salud de la recuperación (recall@k contra un conjunto de oro, precisión del contexto, elevador de ranking), la salud de la generación (precisión de la citación, comprobaciones de base/fidelidad, tasas de rechazo) y la salud operativa (latencia p50/p95, coste por consulta, atraso de ingestión de la actualización del documento al índice de búsqueda).Los equipos más eficaces que he visto mantienen un conjunto de datos de evaluación de oro - preguntas curadas con documentos de origen esperados - y lo ejecutan en un horario y en eventos de cambio (nuevas incorporaciones, nueva lógica de chunking, nuevos lotes de documentos). herramientas como Phoenix, TruLens o plataformas comerciales pueden ayudar, pero el mayor diferenciador es la Una área que a menudo es subestimada es la versión y la reproductibilidad.Cuando cambia los modelos de OCR, la lógica de chunking, la incorporación de modelos, los rerankers o las advertencias de generación, necesita una manera de rastrear qué versiones produjeron cuáles son las respuestas. Choosing Your Stack Elegir tu Stack Para muchos equipos, una configuración de inclinación gestionada es atractiva: ingestión a través de una herramienta de IA de Documento gestionada o un tubo basado en Unstructured, una base de datos vectorial alojada, una capa de orquestación como LlamaIndex o LangChain, y un re-ranker (abierto o gestionado). Otros prefieren implementaciones de código abierto utilizando Qdrant/Weaviate/OpenSearch, Haystack o orquestación similar, y modelos auto-hostados para el control y la predictibilidad de costes. En el lado de la arquitectura, los sistemas tienden a ser más fáciles de operar cuando se dividen de forma limpia: los trabajadores de ingestión que se ejecutan de forma asíncrona y se pueden retratar de forma segura; un servicio de recuperación sin estatus que aplica las políticas y devuelve evidencias; y un servicio de generación que opera con un contexto limitado y una procedencia clara.