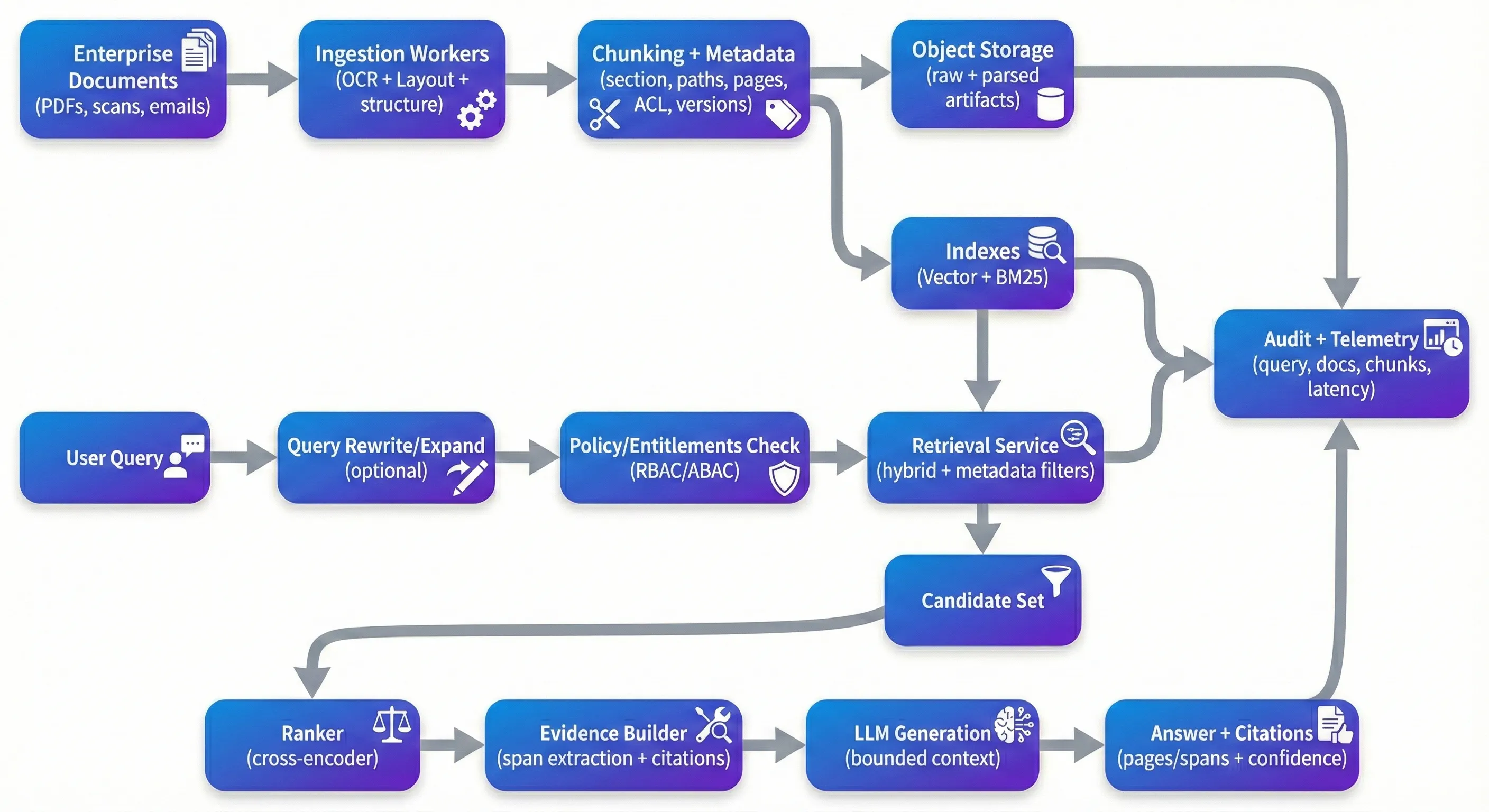
RAG je všade – a to nie je prekvapujúce. Je to jeden z najpraktickejších spôsobov, ako urobiť veľké zbierky dokumentov vyhľadateľnými bez budovania krehkých, doménovo špecifických analyzátorov pre každý typ otázky. Chytrosťou je, že to, čo funguje v kontrolovanej demo, sa často rýchlo degraduje, keď ho umiestnite pred skutočné podnikové PDF: naskenované zmluvy, súladové záznamy, lekárske záznamy, politiky a dlhý chvost problémov s rozložením a kvalitou, ktoré s nimi prichádzajú. Vo výrobe je „problém RAG“ menej o šikovnom výzve a viac o opakovateľnosti: vysledovateľnosť, bezpečnosť, kontroly kvality a schopnosť vysvetliť, prečo je odpoveď správna (alebo Je to preto, že systém nemôže dôsledne založiť odpovede na správne dôkazy, nemôže spoľahlivo presadzovať práva alebo nemôže byť hodnotené a vylepšené bez toho, aby ste veci porušili.Ak nemôžete povedať zainteresovanej strane, ktorá verzia dokumentu podporovala tvrdenie – alebo dokázať, že používateľ bol oprávnený ho vidieť – ešte nemáte produkt. The Demo Trap Demo pasca Väčšina prototypov nasleduje rovnakú cestu: vložiť dokumenty do vektorového obchodu, získať top-k kúsky a požiadať LLM o syntézu. Na čistý, dobre štruktúrovaný text, ktorý môže vyzerať skvele. Problémom je to, čo sa stane ďalej. Skenované PDF sú otočené alebo skreslené. Poradie čítania viacerých stĺpcov je skreslené. Tabuľky strácajú štruktúru počas extrakcie. Chunking rozdeľuje stredný argument. Retrieval vráti „dostatočne blízko“ kontext, ktorý číta pravdepodobne, ale v skutočnosti nepodporuje tvrdenie. A model, ktorý robí to, čo je optimalizované na to, reaguje plynulo. Vo výrobe optimalizujete pre iné vlastnosti ako demo.Chcete, aby bol systém spoľahlivý nad neporiadnymi vstupmi, reprodukovateľný cez zmeny potrubia a obhajiteľný pod dohľadom.To znamená, že môžete sledovať odpoveď späť na konkrétne dôkazy a mať silné predvolené nastavenia, keď sú dôkazy slabé: objasňovanie otázok, správanie odmietnutia alebo prezentovanie „najlepších dostupných dôkazov“ s explicitnou neistotou. Ingestion: Where Quality Is Won or Lost Príjem: kde je kvalita získaná alebo stratená Ak ste vybudovali niekoľko z týchto systémov, rýchlo sa dozviete, že požitie určuje kvalitu vyhľadávania viac ako väčšina následných trikov. Predbežné spracovanie dokumentov AI nie je očarujúce, ale je to miesto, kde buď zachováte štruktúru – alebo ju stratíte natrvalo. Pre podnikové dokumenty samotné OCR nestačí; zvyčajne potrebujete OCR s detekciou rozloženia, rekonštrukciou v poradí čítania a extrakciou štruktúry, ktorá udržiava hlavičky, sekcie a tabuľky zmysluplné. Správované nástroje ako Google Document AI, Azure Document Intelligence a Amazon Textract môžu pokryť veľa zeme. Chunking je miesto, kde tímy často podceňujú zložitosť. Jednoduché rozdelenie znakov alebo tokenov je rýchle, ale má tendenciu prekročiť sémantické hranice – presne hranice, o ktoré sa užívatelia starajú v zmluvách a politikách. Adaptívne chunking, ktorý nasleduje nadpisy, hranice sekcií a hranice tabuliek, zvyčajne zlepšuje vyhľadávanie aj uzemňovanie v dolnej časti. Taktiež robí provenance prirodzeným pre koncového používateľa: namiesto toho, aby sa na povrchu objavil nepriehľadný vnútorný identifikátor, ako je chunk_4892, môžete poukázať na niečo, čo môže recenzent okamžite overiť – „MSA v3.2 → Sekcia 9 (Ukončenie) → 9.2 (Ukončenie Metadáta sú ďalšou oblasťou, ktorá má tendenciu vyzerať voliteľne, kým ju nepotrebujete. V praxi sú metaúdaje tým, čo umožňuje filtrovanie, vysledovateľnosť a reprodukovateľnosť. Užitočné metadáta na úrovni kusov zvyčajne zahŕňajú identifikátory dokumentov, cesty sekcií, čísla stránok, časové pečiatky (účinný dátum, naposledy upravené, požité), signály dôveryhodnosti extrakcie a identifikátory verzií (hash dokumentu, verzia chunkingu, verzia modelu vloženého). V podnikových kontextoch musia byť atribúty kontroly prístupu (nájomca, oddelenie, dôvernosť, značky úloh) prvotriedne, pretože priamo obmedzujú vyhľadávanie a audity. The Retrieval Stack That Actually Works Retrieval Stack, ktorý skutočne funguje Hľadanie vektorovej podobnosti je dobrým východiskovým bodom, ale len zriedka je dostatočné pre podnikové dokumenty.V praxi hybridné vyhľadávanie - tenké vkladanie a vzácne lexikálne vyhľadávanie, ako je BM25 - má tendenciu byť robustnejšie, najmä keď používatelia vyhľadávajú s číslami doložiek, identifikátormi, skratkami alebo presnými frázami. Opätovné zaradenie je často miesto, kde systémy robia najväčší skok v vnímanej kvalite, nie preto, že je to magické, ale preto, že opravuje bežný režim zlyhania: počiatočná súprava na vyhľadávanie obsahuje "kinda relevantné" kúsky a musíte presunúť skutočne relevantné kúsky na vrchol. Opätovné zaradenie cez kódovanie (otvorené modely ako bge-reranker alebo spravované API ako Cohere ranker) rescore kandidátske kúsky pomocou hlbšej interakcie dotazov a priechodov. Tímy zvyčajne vidia výrazný nárast v presnosti kontextu, keď sa prehodnotenie meria správne (napríklad na zlatom súbore s očakávanými zdrojmi). Ak tu ponecháte kvantitatívne Prepísanie a rozšírenie dotazu je ďalšou pákou, ktorú je ľahké preskočiť skôr a potom znovu objaviť neskôr. Používatelia prirodzene nevyjadrujú otázky spôsobom, akým sú dokumenty napísané. Krok prepisovania môže rozšíriť skratky, normalizovať entity a rozdeliť viacdielne otázky na podpožiadavky, ktoré sú vhodné na vyhľadávanie. Nemusí to byť fantastické - ale potrebuje pozorovateľnosť, pretože nekontrolované prepisovanie sa môže odkloniť od zámeru používateľa. Security: The Layer Everyone Forgets Bezpečnosť: vrstva, ktorú všetci zabúdajú Väčšina RAG demo ignoruje kontrolu prístupu, pretože spomaľuje prototyp. Vo výrobe je to primárne obmedzenie. Ak váš systém indexuje dokumenty HR, právne zmluvy a inžinierske špecifikácie dohromady, potrebujete deterministickú cestu oprávnenia od používateľa → povolené kúsky a vyhľadávanie musí byť obmedzené touto cestou predtým, než akýkoľvek obsah dosiahne LLM. Vzor, ktorý má tendenciu škálovať, je predfiltrované vyhľadávanie: výpočtové práva (RBAC/ABAC), vyhľadávanie iba z kúskov s kompatibilnými atribútmi ACL, prepracovanie v rámci autorizovaného súboru kandidátov a zaznamenávanie dôkazov, ktoré boli prístupné.Toto je tiež miesto, kde sa v praxi objaví bod „metadáta nie sú voliteľné“ – bez štítkovania na úrovni kusov, skončíte s únikovými hranicami alebo drahými, krehkými post-filtrami. Okrem ACL podnikové nasadenia zvyčajne potrebujú nejakú kombináciu detekcie / maskovania PII, šifrovania v pokoji, krátkodobých tokenov pre zdrojový prístup a audítorské logovanie, ktoré zachytáva dotazy, získané ID, citácie a verzie dokumentov. Ďalšou modernou obavou, ktorú stojí za to brať vážne, je okamžitá injekcia obsahu vo vnútri dokumentov. Nemusíte zaobchádzať s každým dokumentom ako s nepriateľským, ale potrebujete základné zástrčky, takže pokyny vložené do zdrojového textu nemôžu nahradiť pravidlá vášho systému - najmä okolo prístupu, kontroly a spôsobu, akým sa model môže správať. Monitoring: Closing the Loop Príspevok v téme: Zatvorenie kruhu Ak používate jeden z týchto systémov dlhšie ako niekoľko týždňov, uvidíte drift. Dokumenty sa menia, distribúcia dotazu sa mení, potrubie požitia sa mení a komponenty modelu sa aktualizujú. Bez monitorovania a hodnotenia sa kvalita ticho zhoršuje, až kým používatelia prestanú dôverovať nástroju. V podstate chcete sledovať zdravie vyhľadávania (recall@k oproti zlatému súboru, presnosť kontextu, ranger lift), zdravie generácie (presnosť citácie, kontroly uzemnenia / vernosti, miery odmietnutia) a prevádzkové zdravie (p50/p95 latencia, náklady na dotaz, oneskorenie požitia z aktualizácie dokumentu na vyhľadateľný index). Najefektívnejšie tímy, ktoré som videl, udržiavajú zlatú databázu hodnotenia – vyhodnotené otázky s očakávanými zdrojovými dokumentmi – a spustiť ju podľa plánu a na zmeny (nové vkladanie, nová chunking logika, nové balíky dokumentov). Nástroje ako Phoenix, TruLens alebo komerčné platformy môžu pomôcť, ale väčší diferenciátor je Jednou z oblastí, ktorá je často podhodnotená, je verzia a reprodukovateľnosť.Keď zmeníte modely OCR, chunking logiku, vložíte modely, re-rankery alebo generovanie výzvy, budete potrebovať spôsob, ako sledovať, ktoré verzie vyrábajú, ktoré odpovede. Choosing Your Stack Vyberte si svoj Stack Hromadné rozhodnutia sú dôležité, ale možnosti sú dôležitejšie. Pre mnoho tímov je atraktívna spravovaná inštalácia: požitie prostredníctvom spravovaného nástroja Document AI alebo potrubia založeného na Unstructured, hostiteľská vektorová databáza, vrstva orchestrácie, ako je LlamaIndex alebo LangChain, a re-ranker (otvorený alebo spravovaný). Iní uprednostňujú nasadenie s otvoreným zdrojom pomocou Qdrant/Weaviate/OpenSearch, Haystack alebo podobnej orchestrácie a vlastné modely pre kontrolu a predvídateľnosť nákladov. Oba prístupy môžu fungovať, ak podporujú základy: požitie dokumentov, hybridné vyhľadávanie, presadzovanie práv, citácie priateľské k pôvodu, hodnotiace Na strane architektúry, systémy majú tendenciu byť jednoduchšie fungovať, keď sú rozdelené čisté: požitie pracovníkov, ktorí bežia asynchrónne a môžu byť opätovne bezpečne; bezštátne vyhľadávacie služby, ktoré presadzujú politiky a vráti dôkazy; a generácia služba, ktorá pracuje s obmedzeným kontextu a jasného pôvodu. Typické referenčné nasadenie zahŕňa API bránu, pracovný rad (Kafka / RabbitMQ), ukladanie objektov pre surové dokumenty a rozobraté artefakty, indexovú vrstvu ( +dense sparse), plus centralizované logging / metriky a audit trail.