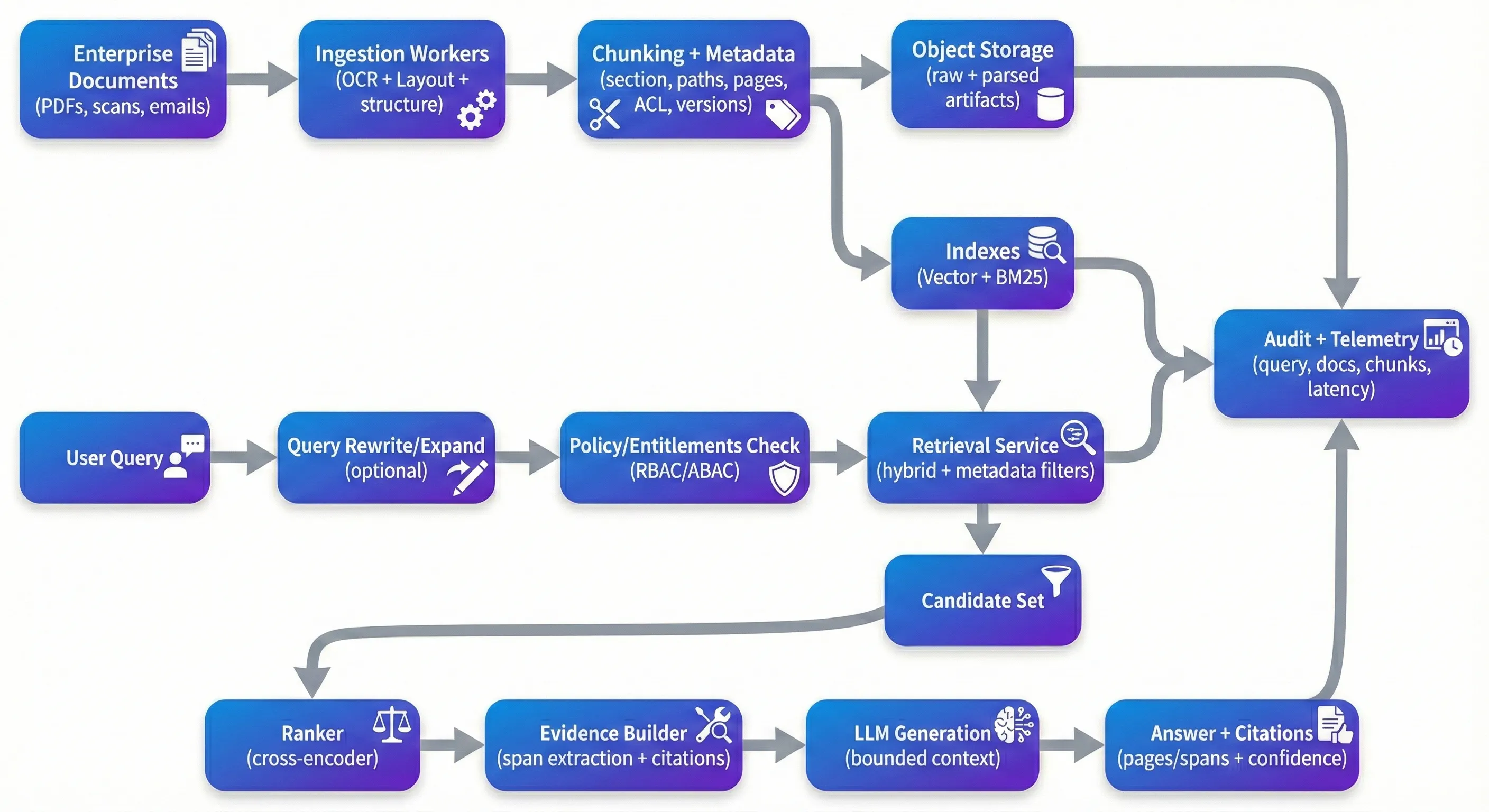
RAG je svugdje – i to nije iznenađujuće. To je jedan od najpraktičnijih načina da se velike zbirke dokumenata mogu pretraživati bez izgradnje krhkih, domenskih analizatora za svaku vrstu pitanja. Dobitak je da se ono što radi u kontroliranom demo-u često brzo degradira kada ga stavite ispred pravih korporativnih PDF-ova: skenirani ugovori, podnesci o sukladnosti, medicinske zapise, politike i dugačak rep pitanja postavljanja i kvalitete koji dolaze s njima. U proizvodnji, „RAG problem“ je manje o pametnom pozivanju, a više o ponovljivosti: sljedivosti, sigurnosti, kontrole kvalitete i sposobnosti objašnjenja zašto je odgovor točan (ili zašto je sustav odbio). To je zato što sustav ne može dosljedno temeljiti odgovore na prave dokaze, ne može pouzdano izvršiti prava, ili se ne može ocijeniti i poboljšati bez prekida stvari. The Demo Trap Demo zamka Većina prototipova slijedi isti put: ispuštanje dokumenata u vektorsku trgovinu, preuzimanje top-k komada i traženje LLM-a za sintezu. Na čistom, dobro strukturiranom tekstu, to može izgledati izvrsno. Problem je u tome što se događa sljedeće. Skenirani PDF-i dolaze u rotirajućem ili iskrivljenom obliku. Redoslijed čitanja u višestrukim stoljećima postaje zbunjen. Tabele gube strukturu tijekom ekstrakcije. Čunkanje dijeli sredinu argumenta. Pronalaženje vraća kontekst "dovoljno blizu" koji čita vjerodostojno, ali zapravo ne podržava tvrdnju. A model, čineći ono što je optimizirano za to, odgovori tekuće u svakom slučaju. U proizvodnji, optimizirate za različita svojstva od demo-a. Želite da sustav bude pouzdan nad neredovitim ulazima, reproduciran kroz promjene cijevi i branljiv pod kontrolom.To znači biti u stanju pratiti odgovor natrag na određene dokaze i imati snažne podrazumijevanja kada su dokazi slabi: razjašnjavajući pitanja, ponašanje odbijanja ili predstavljanje "najboljih dostupnih dokaza" s eksplicitnom neizvjesnošću. Ingestion: Where Quality Is Won or Lost Uzimanje: gdje je kvaliteta osvojena ili izgubljena Ako ste izgradili nekoliko ovih sustava, brzo ćete naučiti da gutanje određuje kvalitetu preuzimanja više od većine daljnjih trikova. Preprocesiranje dokumenta AI nije glamurozno, ali to je mjesto gdje ili sačuvate strukturu – ili je trajno izgubite. Za poduzetničke dokumente, OCR sam po sebi nije dovoljan; obično vam je potreban OCR s otkrivanjem rasporeda, rekonstrukcijom čitanja i ekstrakcijom strukture koja održava glave, odjeljke i tablice značajne. Upravljani alati kao što su Google Document AI, Azure Document Intelligence i Amazon Textract mogu pokriti puno terena. Jednostavna podjela znakova ili žetona je brza, ali ima tendenciju da prekorači semantičke granice – to su točno granice o kojima se korisnici brinu u ugovorima i pravilima. Adaptivno podcjenjivanje koje slijedi naslove, granice odjeljka i granice tablica obično poboljšava i preuzimanje i uzdizanje u daljnjem tijeku. Također čini da se izvor osjeća prirodno za krajnjeg korisnika: umjesto da se pojavi neprozirni unutarnji ID kao što je chunk_4892, možete ukazati na nešto što recenzent može odmah provjeriti – „MSA v3.2 → Odjeljak 9 (Kraj) → 9.2 (Kraj za uzrok), stranica 12, linije 14-22.” Metapodaci su još jedno područje koje izgleda opcionalno sve dok vam ne budu potrebni. U praksi, metapodaci su ono što omogućuje filtriranje, sljedivost i reproduktivnost. Korisni metapodaci na razini dijelova obično uključuju ID-ove dokumenata, putove odjeljka, brojeve stranica, vremenske žigove (korisni datum, posljednja izmijenjena, unijeta na), signale pouzdanosti ekstrakcije i identifikatore verzije (hash dokumenata, verzija čunkiranja, verzija ugrađenog modela). U poslovnim kontekstima, atributi kontrole pristupa (najamnik, odjeljak, povjerljivost, oznake uloga) moraju biti prvoklasni, jer izravno ograničavaju preuzimanje i revizije. The Retrieval Stack That Actually Works Prethodni Članak Retrieval Stack koji stvarno radi U praksi, hibridno pronalaženje - gusto ugrađivanje plus rijetko leksikalno pronalaženje kao što je BM25 - ima tendenciju da bude robusnije, pogotovo kada korisnici upituju brojevima klauzula, identifikatorima, akronimima ili točnim frazama. Ponovno rangiranje je često mjesto gdje sustavi napravljaju najveći skok u percipiranoj kvaliteti, ne zato što je to čarobno, već zato što popravlja uobičajeni način neuspjeha: početni skup prikupljanja sadrži "kinda relevantne" komadiće, a vi trebate promicati istinski relevantne komadiće na vrh. Preko-kodiranje ponovno rangira (otvoreni modeli kao što su bge-reranker ili upravljani API-ji kao što je Cohere ranker) ponovno rangira komadiće kandidata koristeći dublju interakciju upita i prolaza. Timovi obično vide primjetan porast u kontekstualnoj preciznosti kada se rerangiranje mjeri ispravno (na primjer, na zlatnom skupu s očekivanim izvorima). Ako ovdje držite kvantitativ Prepisivanje upita i proširenje je još jedan faktor koji je lako preskočiti ranije, a zatim ponovno otkriti kasnije. Korisnici prirodno ne izražavaju pitanja na način na koji su dokumenti napisani. Korak prepisivanja može proširiti akronime, normalizirati entitete i podijeliti pitanja u više dijelova u potraživanje-prijateljska podizvoda. To ne mora biti fancy – ali to zahtijeva promatranost, jer nekontrolirano prepisivanje može odstupiti od namjere korisnika. Security: The Layer Everyone Forgets Sigurnost: sloj koji svi zaboravljaju Većina RAG demonstracija ignorira kontrolu pristupa jer usporava prototip.U proizvodnji, to je primarno ograničenje.Ako vaš sustav indeksira HR dokumente, pravne ugovore i inženjerske specifikacije zajedno, trebate deterministski put prava od korisnika → dopuštenih komada, a preuzimanje mora biti ograničeno tim putem prije nego što bilo koji sadržaj dosegne LLM. Uzorak koji je skalan je pre-filtrirano preuzimanje: izračunavanje prava (RBAC/ABAC), preuzimanje samo iz komada s kompatibilnim ACL atributima, preraspodjela u autoriziranom skupu kandidata i evidencija o tome koji su dokazi pristupili.To je također mjesto gdje se u praksi pojavljuje tačka "metapodatci nisu neobvezni" - bez oznake na razini komada, završite s curljivim granicama ili skupim, krhkim post-filtrima. Pored ACL-a, implementacije poduzeća obično zahtijevaju neku kombinaciju detekcije / maskiranja PII-a, šifriranja u mirovanju, kratkotrajnih žetona za pristup izvoru i evidentiranja audita koji hvata upite, preuzete ID-ove dijelova, citate i verzije dokumenata. Još jedna moderna zabrinutost vrijedna ozbiljnog uzimanja je brzo ubrizgavanje sadržaja unutar dokumenata. Ne morate tretirati svaki dokument kao neprijateljski, ali trebate osnovne stražare, tako da upute ugrađene u izvorni tekst ne mogu zamijeniti pravila vašeg sustava - osobito oko pristupa, kontrole i načina na koji se model smije ponašati. Monitoring: Closing the Loop Sljedeći članak: Zatvaranje kruga Ako koristite jedan od tih sustava više od nekoliko tjedana, vidjet ćete drift. Dokumenti se mijenjaju, raspodjela upita se mijenja, putanje unosa se mijenja, a komponente modela se ažuriraju. Praktično, želite pratiti zdravlje pretraživanja (recall@k u odnosu na zlatni set, preciznost konteksta, podizanje rangera), zdravlje generacije (preciznost citiranja, provjere utemeljenosti / vjernosti, stope odbijanja) i operativno zdravlje (p50/p95 latentnost, trošak po upitu, zakašnjenje unosa od ažuriranja dokumenata do indeksiranja koji se može pretraživati). Najučinkovitiji timovi koje sam vidio održavaju zlatni skup podataka o evaluaciji - ispravljena pitanja s očekivanim izvornim dokumentima - i pokreću ga na rasporedu i na događajima promjene (nove ugrađivanja, nova krčenje logike, nove serije dokumenata). alat kao što su Phoenix, TruLens ili komercijalne platforme mogu pomoći Jedno područje koje se često podcijenjuje je verzija i reproducabilnost.Kada promijenite modele OCR-a, čunčate logiku, ugrađujete modele, ponovno rangirate ili generirate upute, trebate način da pratite koje su verzije proizvedene koje odgovaraju. Choosing Your Stack Odaberite svoj Stack Odluke o skupinama su važne, ali mogućnosti su važnije. Za mnoge timove, upravljana postavka je privlačna: upijanje putem upravljanog alata za dokument AI ili nestrukturiranog vodovoda, pohranjena vektorska baza podataka, sloj orkestracije kao što su LlamaIndex ili LangChain, i reranker (otvoren ili upravljan). Drugi preferiraju ugradnje otvorenog izvora koristeći Qdrant/Weaviate/OpenSearch, Haystack ili sličnu orkestraciju, te samohostirane modele za kontrolu i predvidljivost troškova. Oba pristupa mogu raditi ako podržavaju osnove: upijanje dokumenata, hibridno preuzimanje, izvršenje prava, citiranje prilagođeno porijeklu, procjene vodovoda i verziju. S arhitekture strane, sustavi imaju tendenciju da postanu lakše raditi kada su čisti podijeljeni: radnici za gutanje koji rade asinkronno i mogu se sigurno ponoviti; usluga pretraživanja bez statusa koja provodi politike i vraća dokaze; i usluga generacije koja radi s ograničenim kontekstom i jasnim izvorom.