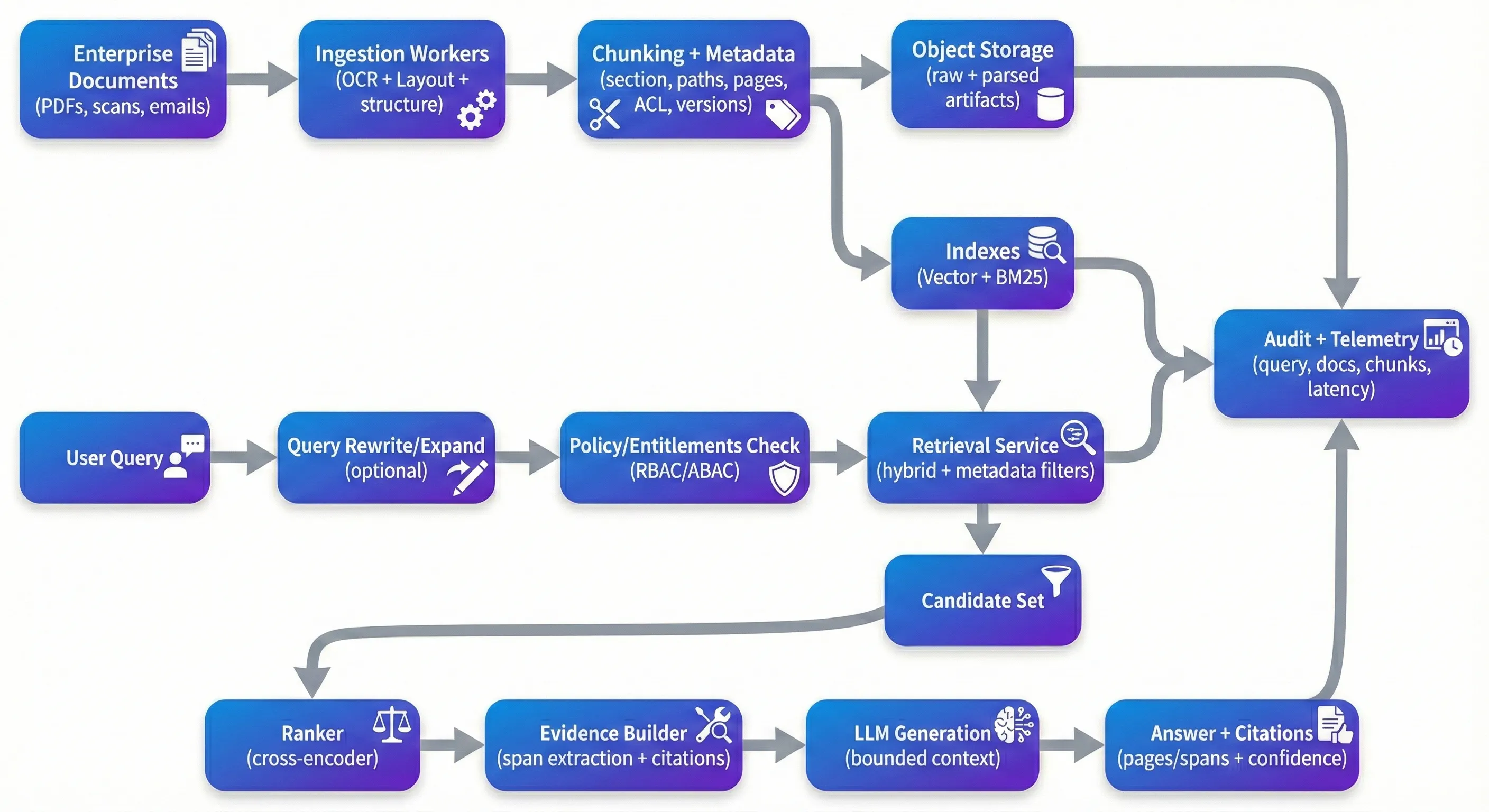
RAGはあらゆる種類の質問に対して脆弱でドメイン特有のパッサーを構築することなく、大規模なドキュメントコレクションを検索可能にする最も実用的な方法の1つです。 コントロールされたデモで機能するものは、実際のエンタープライズPDFの前に置いたときに、スキャンされた契約、コンプライアンスファイル、医療記録、ポリシー、およびそれらに伴う長いレイアウトと品質の問題の尾を、しばしば急速に劣化するという点です。 生産では、「RAGの問題」は、スマートなプロンプトについてではなく、追跡性、セキュリティ、品質管理、および答えが正しい理由(またはシステムが拒否した理由)を説明する能力についてです。 それは、システムが正しい証拠に一貫して答えを土台にすることができず、権利を信頼できるように実行することができず、または物事を破ることなく評価され、改善することができないためです。 The Demo Trap 「Demo Trap」 ほとんどのプロトタイプは同じパスに従う: ベクトルストアにドキュメントを落とし、トップKのブロックを取得し、LLMに合成を依頼します。クリーンで構造化されたテキストで、それは素晴らしいように見えます。問題は次に何が起こるかです。スキャンされたPDFは回転または歪んでいます。 複数の列の読み取り順序がスルーブルされます。 抽出中にテーブルは構造を失います。 Chunkingは中間の論点を分割します。 Retrievalは「十分に近い」コンテキストを返しますが、実際には主張をサポートしません。そしてモデルは、それを行うために最適化されたことを行うことで、とにかく流暢に回答します。 生産では、デモよりも異なるプロパティのための最適化を行っています。あなたは、システムが混乱した入力に対して信頼性があり、パイプラインの変更を通じて再現可能で、検査の下で防御可能であることを望んでいます。それは、特定の証拠に返答を追跡することができ、証拠が弱いときに強力なデフォルトを持っていることを意味します:質問を明確にする、拒否行動、または明示的な不確実性を伴う「最良の証拠」を提示します。 Ingestion: Where Quality Is Won or Lost 摂取:品質が獲得または失われる場所 これらのシステムのいくつかを構築した場合、摂取がほとんどの下流トリックよりも検出の品質を決定することをすぐに学ぶことができます。Document AI Preprocessing は魅力的なものではありませんが、構造を保存するか、永久に失うところです。エンタープライズドキュメントのためのOCRだけでは、OCRだけでは不十分です。あなたは通常、レイアウト検出、読み取り順序再構築、および構造抽出を必要とし、ヘッダー、セクション、およびテーブルを有意義に保ちます。Google Document AI、Azure Document Intelligence、およびAmazon Textractなどのマネージドツールは多くの土地をカバーすることができます。非構造化およびGROBIDのようなオープンソースパイプラインは、透明 シンプルなキャラクターまたはトークン分割は速いが、シンプルなキャラクターやトークン分割はシンプルなキャラクターやトークン分割はシンプルなキャラクターやトークン分割はシンプルなキャラクターやトークン分割はシンプルなキャラクターやトークン分割はシンプルなキャラクターやトークン分割はシンプルなキャラクターやトークン分割はシンプルなキャラクターでシンプルなキャラクターでシンプルなキャラクターのキャラクターのキャラクターのキャラクターのキャラクターのキャラクターのキャラクターのキャラクターのキャラクターのキャラクターのキャ 実際には、メタデータは、フィルタリング、追跡性、および再生可能性を可能にするものです。役に立つ部分レベルのメタデータには、ドキュメントID、セクションパス、ページ番号、タイムスタンプ(有効な日付、最後に変更された、注入された)、抽出信頼信号、バージョン識別子(ドキュメントハッシュ、チャンキングバージョン、埋め込みモデルバージョン)が含まれます。 The Retrieval Stack That Actually Works The Retrieval Stack That Actually Works ベクターの類似性の検索は良いベースラインですが、企業文書のための単独で十分なことはほとんどありません。実践では、ハイブリッドリリース - 薄い埋め込みとBM25のような希少なレクシカルリリース - は、特にユーザーがセクション番号、識別子、略称、または正確な表現でクエリするとき、より強力である傾向があります。 再ランキングはしばしば、システムが感知された品質で最大の飛躍を遂げる場所であり、それは魔法だからではなく、それは一般的な失敗モードを修正するためです:初期のリサーチセットには「Kinda Relevant」ブランドが含まれており、あなたは真に関連するブランドをトップに推進する必要があります。クロスエンコーダーの再ランキング(bge-rerankerやCohere rankerのような管理されたAPIのようなオープンモデル)は、より深いクエリとパスイヤーの相互作用を使用して候補ブランドを再ランキングします。チームは通常、リランキングが適切に測定されたとき(例えば、予想されるソースのゴールデンセットで)。 クエリの書き換えと拡張は、早期に飛び出し、後で再発見するのが簡単なもう一つのハードウェアです。ユーザーは文書が書かれている方法で質問を自然に表現することはありません。再書き換えのステップは、略称を拡張し、エンティティを正常化し、複数の部分の質問をリクエリフレンドリーなサブクエリに分割することができます。 Security: The Layer Everyone Forgets セキュリティ:Layer Everyone Forgets ほとんどのRAGデモは、プロトタイプを遅らせるためアクセス制御を無視します。生産では、これは主な制約です。あなたのシステムがHR文書、法的契約、およびエンジニアリング仕様を一緒にインデックスする場合、あなたはユーザーから決定的な権利パス→許可されたブロックを必要とし、すべてのコンテンツがLLMに到達する前に、そのパスによって回収が制限されなければなりません。 スケールする傾向があるパターンは、事前フィルタリングの検索:計算権限(RBAC/ABAC)、互換性のあるACL属性を持つブロックのみを取得し、許可された候補者セット内で再ランキングし、アクセスされた証拠をログします。これも、「メタデータはオプションではない」ポイントが実践的に現れる場所です - ブロックレベルのタグ付けなしで、漏れのある境界線や高価で脆弱なポストフィルターで終わります。 ACL を超えて、エンタープライズの展開には通常、PII 検出/マスキング、休憩時の暗号化、ソースアクセスのための短期間のトークン、およびクエリ、リクエストされたチンク ID、引用、およびドキュメントのバージョンをキャプチャする監査ログリングの組み合わせが必要です。もう一つの現代的な懸念は、ドキュメント内の迅速な注入コンテンツです。 Monitoring: Closing the Loop オリジナルタイトル: Closing the loop これらのシステムのいずれかを数週間以上実行している場合、ドライブが表示されます。ドキュメントが変更され、クエリの配布が変更され、摂取パイプラインが変更され、モデルコンポーネントが更新されます。 実質的には、リクエストの健康(ゴールデンセットに対するrecall@k、コンテキスト精度、リランカーアップ)、生成の健康(引用精度、地盤/忠実性チェック、拒否率)、および運用の健康(p50/p95遅延、クエリあたりのコスト、ドキュメント更新から検索可能なインデックスへの摂取遅延)を追跡したいです。私が見た最も効果的なチームは、ゴールデン評価データセットを維持し、予想されたソースドキュメントでクエリされた質問をスケジュールおよび変更イベント(新しい埋め込み、新しいクンキングロジック、新しいドキュメントパッケージ)で実行します。 しばしば過小評価される領域の1つは、バージョニングと再生可能性です。OCRモデルを変更し、論理を切り替え、モデルを埋め込み、リランカー、または生成プロンプトを生成するとき、どのバージョンがどの回答を生成したかを追跡する方法が必要です。 Choosing Your Stack あなたのスタックを選ぶ ステック決定は重要ですが、機能はより重要です。多くのチームにとって、マネージドベースのセットアップは魅力的です:管理されたDocument AIツールまたは非構造型パイプライン、ホストベクターデータベース、LlamaIndexやLangChainなどのオーケストラレイヤーレイヤー、リランカー(オープンまたはマネージド)。他の人々はQdrant/Weaviate/OpenSearch、Haystack、または類似のオーケストラリングを使用してオープンソースのデプロイを好み、コントロールとコスト予測のための自己ホストモデルです。いずれかのアプローチは、基本をサポートする場合に機能します:ドキュメント意識のインゲージ、ハイブリッドリリーバル、権 アーキテクチャ側では、システムは、清潔に分割されたときに操作しやすくなります:アシンクロンで動作し、安全にリリースすることができる摂取労働者、ポリシーを適用し、証拠を返す無国籍の回収サービス、制限された文脈と明確な出身地で動作する生成サービス。