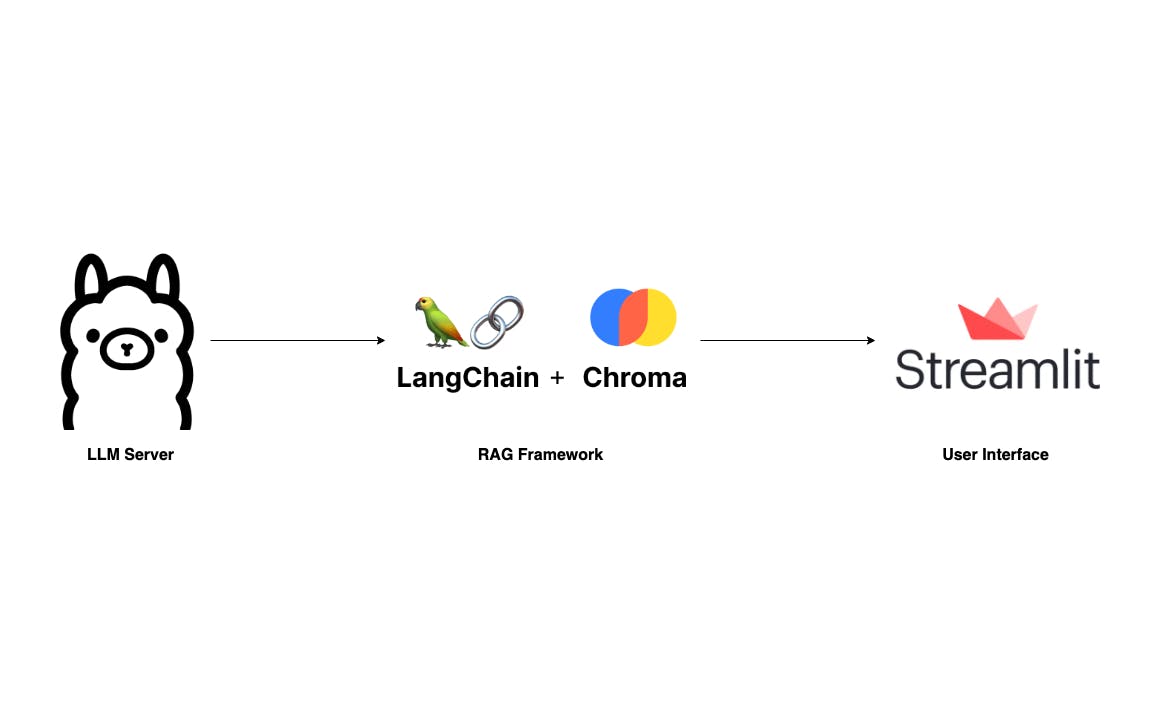
Mit dem Aufkommen großer Sprachmodelle und ihren beeindruckenden Fähigkeiten werden viele ausgefallene Anwendungen auf der Grundlage riesiger LLM-Anbieter wie OpenAI und Anthropic erstellt. Der Mythos hinter solchen Anwendungen ist das RAG-Framework, das in den folgenden Artikeln ausführlich erläutert wurde: Erstellen von RAG-basierten LLM-Anwendungen für die Produktion Retrieval Augmented Generation (RAG) erklärt: Schlüsselkonzepte verstehen Was ist Retrieval-Augmented Generation? Um sich mit RAG vertraut zu machen, empfehle ich die Lektüre dieser Artikel. Dieser Beitrag überspringt jedoch die Grundlagen und führt Sie direkt zum Erstellen Ihrer eigenen RAG-Anwendung, die lokal auf Ihrem Laptop ausgeführt werden kann, ohne sich Gedanken über Datenschutz und Token-Kosten machen zu müssen. Wir werden eine Anwendung erstellen, die F ähnelt, aber einfacher ist. Hier können Benutzer über eine unkomplizierte Benutzeroberfläche ein PDF-Dokument hochladen und Fragen stellen. Unser Tech-Stack ist mit Langchain, Ollama und Streamlit super einfach. ChatPD : Die wichtigste Komponente dieser App ist der LLM-Server. Dank an Wir verfügen über einen robusten LLM-Server, der lokal, sogar auf einem Laptop, eingerichtet werden kann. Während ist eine Option, ich finde, dass Ollama, geschrieben in Go, einfacher einzurichten und auszuführen ist. LLM-Server Ollama lama.cpp : Zweifellos sind dies die beiden führenden Bibliotheken im LLM-Bereich Und . Für dieses Projekt werde ich Langchain verwenden, da ich damit aus meiner Berufserfahrung vertraut bin. Ein wesentlicher Bestandteil jedes RAG-Frameworks ist die Vektorspeicherung. Wir werden verwenden hier, da es sich gut in Langchain integrieren lässt. RAG Langkette LLamIndex Chroma : Die Benutzeroberfläche ist ebenfalls eine wichtige Komponente. Obwohl viele Technologien verfügbar sind, bevorzuge ich die Verwendung , eine Python-Bibliothek, zur Sicherheit. Chat-Benutzeroberfläche Streamlit Okay, beginnen wir mit der Einrichtung. Ollama einrichten Wie oben erwähnt, ist die Einrichtung und Ausführung von Ollama unkompliziert. Erster Besuch und laden Sie die für Ihr Betriebssystem geeignete App herunter. ollama.ai Öffnen Sie als Nächstes Ihr Terminal und führen Sie den folgenden Befehl aus, um die neueste Version abzurufen . Während es viele andere gibt Ich wähle Mistral-7B wegen seiner kompakten Größe und wettbewerbsfähigen Qualität. Mistral-7B LLM-Modelle verfügbar ollama pull mistral Führen Sie anschließend aus, um zu überprüfen, ob das Modell korrekt gezogen wurde. Die Terminalausgabe sollte wie folgt aussehen: ollama list Wenn der LLM-Server noch nicht läuft, initiieren Sie ihn nun mit . Wenn eine Fehlermeldung wie , bedeutet dies, dass der Server standardmäßig bereits ausgeführt wird, und Sie können mit dem nächsten Schritt fortfahren. ollama serve "Error: listen tcp 127.0.0.1:11434: bind: address already in use" Erstellen Sie die RAG-Pipeline Der zweite Schritt in unserem Prozess ist der Aufbau der RAG-Pipeline. Aufgrund der Einfachheit unserer Anwendung benötigen wir hauptsächlich zwei Methoden: und . ingest ask Die akzeptiert einen Dateipfad und lädt ihn in zwei Schritten in den Vektorspeicher: Erstens teilt sie das Dokument in kleinere Teile auf, um das Token-Limit des LLM zu berücksichtigen. Zweitens vektorisiert es diese Chunks mithilfe von Qdrant FastEmbeddings und speichert sie in Chroma. ingest Die Methode verarbeitet Benutzeranfragen. Benutzer können eine Frage stellen, und dann ruft RetrievalQAChain mithilfe von Vektorähnlichkeitssuchtechniken die relevanten Kontexte (Dokumentblöcke) ab. ask Mit der Frage des Benutzers und den abgerufenen Kontexten können wir eine Eingabeaufforderung verfassen und eine Vorhersage vom LLM-Server anfordern. from langchain.vectorstores import Chroma from langchain.chat_models import ChatOllama from langchain.embeddings import FastEmbedEmbeddings from langchain.schema.output_parser import StrOutputParser from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.vectorstores.utils import filter_complex_metadata class ChatPDF: vector_store = None retriever = None chain = None def __init__(self): self.model = ChatOllama(model="mistral") self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) self.prompt = PromptTemplate.from_template( """ <s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. [/INST] </s> [INST] Question: {question} Context: {context} Answer: [/INST] """ ) def ingest(self, pdf_file_path: str): docs = PyPDFLoader(file_path=pdf_file_path).load() chunks = self.text_splitter.split_documents(docs) chunks = filter_complex_metadata(chunks) vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings()) self.retriever = vector_store.as_retriever( search_type="similarity_score_threshold", search_kwargs={ "k": 3, "score_threshold": 0.5, }, ) self.chain = ({"context": self.retriever, "question": RunnablePassthrough()} | self.prompt | self.model | StrOutputParser()) def ask(self, query: str): if not self.chain: return "Please, add a PDF document first." return self.chain.invoke(query) def clear(self): self.vector_store = None self.retriever = None self.chain = None Die Eingabeaufforderung stammt vom Langchain-Hub: . Diese Eingabeaufforderung wurde tausende Male getestet und heruntergeladen und dient als zuverlässige Ressource zum Erlernen der LLM-Eingabeaufforderungstechniken. Langchain RAG-Eingabeaufforderung für Mistral Erfahren Sie mehr über LLM-Prompting-Techniken . Hier Weitere Details zur Umsetzung: : Wir verwenden PyPDFLoader, um die vom Benutzer hochgeladene PDF-Datei zu laden. Der von Langchain bereitgestellte RecursiveCharacterSplitter teilt dieses PDF dann in kleinere Teile auf. Es ist wichtig, komplexe Metadaten, die von ChromaDB nicht unterstützt werden, mithilfe der Funktion von Langchain herauszufiltern. ingest filter_complex_metadata Für die Vektorspeicherung wird Chroma verwendet, gekoppelt mit als unser Einbettungsmodell. Dieses leichte Modell wird dann in einen Retriever mit einem Punkteschwellenwert von 0,5 und k=3 umgewandelt, was bedeutet, dass es die drei besten Blöcke mit den höchsten Punkten über 0,5 zurückgibt. Schließlich erstellen wir eine einfache Konversationskette mit . Qdrant FastEmbed LECL : Diese Methode übergibt einfach die Frage des Benutzers an unsere vordefinierte Kette und gibt dann das Ergebnis zurück. ask : Diese Methode wird verwendet, um die vorherige Chat-Sitzung und den Speicher zu löschen, wenn eine neue PDF-Datei hochgeladen wird. clear Entwerfen Sie eine einfache Benutzeroberfläche Für eine einfache Benutzeroberfläche verwenden wir , ein UI-Framework, das für das schnelle Prototyping von KI/ML-Anwendungen entwickelt wurde. Streamlit import os import tempfile import streamlit as st from streamlit_chat import message from rag import ChatPDF st.set_page_config(page_title="ChatPDF") def display_messages(): st.subheader("Chat") for i, (msg, is_user) in enumerate(st.session_state["messages"]): message(msg, is_user=is_user, key=str(i)) st.session_state["thinking_spinner"] = st.empty() def process_input(): if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0: user_text = st.session_state["user_input"].strip() with st.session_state["thinking_spinner"], st.spinner(f"Thinking"): agent_text = st.session_state["assistant"].ask(user_text) st.session_state["messages"].append((user_text, True)) st.session_state["messages"].append((agent_text, False)) def read_and_save_file(): st.session_state["assistant"].clear() st.session_state["messages"] = [] st.session_state["user_input"] = "" for file in st.session_state["file_uploader"]: with tempfile.NamedTemporaryFile(delete=False) as tf: tf.write(file.getbuffer()) file_path = tf.name with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"): st.session_state["assistant"].ingest(file_path) os.remove(file_path) def page(): if len(st.session_state) == 0: st.session_state["messages"] = [] st.session_state["assistant"] = ChatPDF() st.header("ChatPDF") st.subheader("Upload a document") st.file_uploader( "Upload document", type=["pdf"], key="file_uploader", on_change=read_and_save_file, label_visibility="collapsed", accept_multiple_files=True, ) st.session_state["ingestion_spinner"] = st.empty() display_messages() st.text_input("Message", key="user_input", on_change=process_input) if __name__ == "__main__": page() Führen Sie diesen Code mit dem Befehl , um zu sehen, wie er aussieht. streamlit run app.py Okay, das ist es! Wir haben jetzt eine ChatPDF-Anwendung, die vollständig auf Ihrem Laptop läuft. Da sich dieser Beitrag hauptsächlich darauf konzentriert, einen allgemeinen Überblick darüber zu geben, wie Sie Ihre eigene RAG-Anwendung erstellen, gibt es mehrere Aspekte, die einer Feinabstimmung bedürfen. Sie können die folgenden Vorschläge in Betracht ziehen, um Ihre App zu verbessern und Ihre Fähigkeiten weiterzuentwickeln: : Derzeit wird der Konversationsablauf nicht gespeichert. Das Hinzufügen eines temporären Speichers hilft Ihrem Assistenten, sich des Kontexts bewusst zu werden. Speicher zur Konversationskette hinzufügen : Es ist in Ordnung, jeweils nur über ein Dokument zu chatten. Aber stellen Sie sich vor, wir könnten über mehrere Dokumente sprechen – Sie könnten Ihr gesamtes Bücherregal dort unterbringen. Das wäre supercool! Mehrere Datei-Uploads zulassen : Mistral ist zwar effektiv, es stehen jedoch viele andere Alternativen zur Verfügung. Möglicherweise finden Sie ein Modell, das Ihren Anforderungen besser entspricht, z. B. LlamaCode für Entwickler. Bedenken Sie jedoch, dass die Wahl des Modells von Ihrer Hardware abhängt, insbesondere von der Menge an RAM, über die Sie verfügen 💵 Verwenden Sie andere LLM-Modelle : Innerhalb der RAG gibt es Raum für Experimente. Möglicherweise möchten Sie die Abrufmetrik, das Einbettungsmodell usw. ändern oder Ebenen wie einen Re-Ranker hinzufügen, um die Ergebnisse zu verbessern. Verbessern Sie die RAG-Pipeline Zum Schluss vielen Dank fürs Lesen. Wenn Sie diese Informationen nützlich finden, erwägen Sie bitte ein Abonnement von my oder meine persönliche . Ich habe vor, mehr über RAG- und LLM-Anwendungen zu schreiben. Sie können gerne Themen vorschlagen, indem Sie unten einen Kommentar hinterlassen. Prost! Unterstapel Blog Vollständiger Quellcode: https://github.com/vndee/local-rag-example