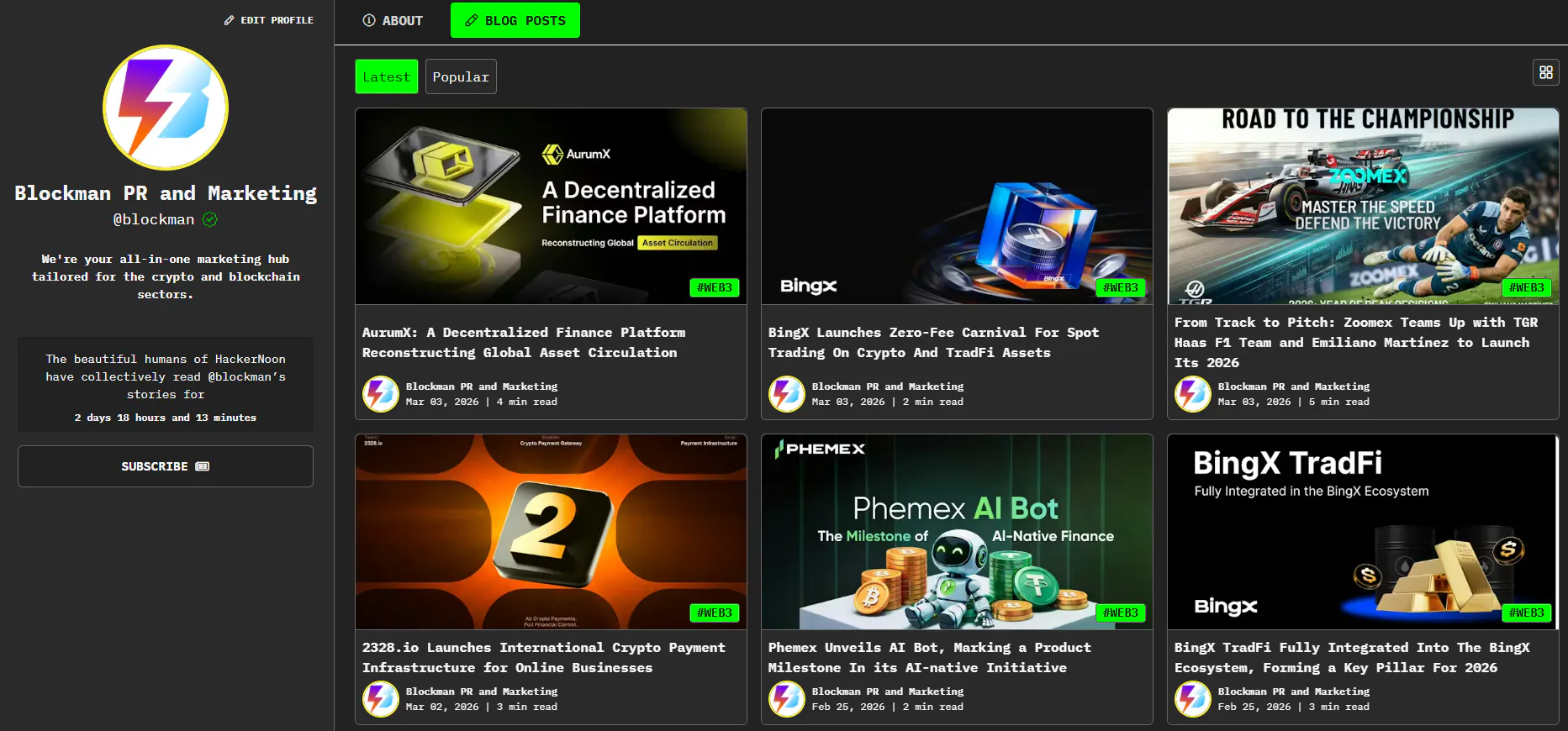
```html ผู้เขียน: Neereja Sundaresan Theodore J. Yoder Youngseok Kim Muyuan Li Edward H. Chen Grace Harper Ted Thorbeck Andrew W. Cross Antonio D. Córcoles Maika Takita บทคัดย่อ การแก้ไขข้อผิดพลาดควอนตัม (Quantum error correction) เป็นหนทางที่มีแนวโน้มที่ดีในการคำนวณควอนตัมที่มีความเที่ยงตรงสูง แม้ว่าการดำเนินการอัลกอริทึมแบบทนทานต่อความผิดพลาด (fault-tolerant) อย่างสมบูรณ์ยังไม่เกิดขึ้น แต่การปรับปรุงอุปกรณ์ควบคุมอิเล็กทรอนิกส์และฮาร์ดแวร์ควอนตัมในปัจจุบันได้ช่วยให้สามารถสาธิตการดำเนินการที่จำเป็นสำหรับการแก้ไขข้อผิดพลาดได้อย่างต่อเนื่อง ในที่นี้ เราดำเนินการแก้ไขข้อผิดพลาดควอนตัมบนคิวบิต (qubits) แบบตัวนำยิ่งยวดที่เชื่อมต่อกันในโครงตาข่ายแบบ heavy-hexagon เราเข้ารหัสคิวบิตเชิงตรรกะ (logical qubit) ที่มีระยะห่างสาม และดำเนินการวัดค่าซินโดรม (syndrome measurements) หลายรอบแบบทนทานต่อความผิดพลาด ซึ่งช่วยให้สามารถแก้ไขความผิดพลาดเดี่ยวใดๆ ในวงจรได้ ด้วยการใช้การตอบสนองแบบเรียลไทม์ เราจึงรีเซ็ตคิวบิตซินโดรมและแฟล็ก (flag qubits) ตามเงื่อนไขหลังแต่ละรอบการดึงค่าซินโดรม เรารายงานข้อผิดพลาดเชิงตรรกะ (logical error) ที่ขึ้นอยู่กับตัวถอดรหัส โดยมีค่าเฉลี่ยข้อผิดพลาดเชิงตรรกะต่อการวัดซินโดรมในฐาน Z(X) อยู่ที่ประมาณ 0.040 (0.088) และ 0.037 (0.087) สำหรับตัวถอดรหัสแบบจับคู่ (matching) และแบบความน่าจะเป็นสูงสุด (maximum likelihood) ตามลำดับ โดยใช้ข้อมูลหลังจากการคัดกรองการรั่วไหล (leakage post-selected data) บทนำ ผลลัพธ์ของการคำนวณควอนตัมอาจเกิดข้อผิดพลาดได้ในทางปฏิบัติ เนื่องมาจากสัญญาณรบกวนในฮาร์ดแวร์ เพื่อขจัดข้อผิดพลาดที่เกิดขึ้น สามารถใช้รหัสการแก้ไขข้อผิดพลาดควอนตัม (QEC codes) เพื่อเข้ารหัสข้อมูลควอนตัมลงในส่วนที่ได้รับการปกป้อง ซึ่งเป็นอิสระเชิงตรรกะ (logical degrees of freedom) และจากนั้นโดยการแก้ไขข้อผิดพลาดได้เร็วกว่าที่มันสะสม จะทำให้สามารถคำนวณแบบทนทานต่อความผิดพลาด (FT) ได้ การดำเนินการ QEC ที่สมบูรณ์น่าจะต้องประกอบด้วย: การเตรียมสถานะเชิงตรรกะ; การสร้างชุดเกตเชิงตรรกะสากล (universal set of logical gates) ซึ่งอาจต้องมีการเตรียมสถานะเมจิก (magic states); การวัดค่าซินโดรมซ้ำๆ; และการถอดรหัสค่าซินโดรมเพื่อแก้ไขข้อผิดพลาด หากประสบความสำเร็จ อัตราข้อผิดพลาดเชิงตรรกะที่ได้ควรจะน้อยกว่าอัตราข้อผิดพลาดทางกายภาพ (physical error rates) และลดลงเมื่อระยะห่างของรหัส (code distances) เพิ่มขึ้นจนถึงค่าที่น้อยมาก การเลือกรหัส QEC ต้องพิจารณาถึงฮาร์ดแวร์พื้นฐานและคุณสมบัติสัญญาณรบกวน สำหรับโครงตาข่ายแบบ heavy-hexagon [1, 2] ของคิวบิต รหัส QEC แบบ subsystem [3] นั้นน่าสนใจเนื่องจากเหมาะสมกับคิวบิตที่มีการเชื่อมต่อที่ลดลง รหัสอื่นๆ ก็ได้แสดงให้เห็นถึงศักยภาพเนื่องจากมีเกณฑ์ (threshold) ค่อนข้างสูงสำหรับการคำนวณแบบ FT [4] หรือจำนวนเกตเชิงตรรกะแบบ transversal มาก [5] แม้ว่าทรัพยากรด้านพื้นที่และเวลาของมันอาจเป็นอุปสรรคสำคัญต่อการขยายขนาด แต่ก็มีแนวทางที่น่าสนใจในการลดทรัพยากรที่มีค่าใช้จ่ายสูงที่สุดโดยการใช้ประโยชน์จากการลดข้อผิดพลาด (error mitigation) บางรูปแบบ [6] ในกระบวนการถอดรหัส ความสำเร็จในการแก้ไขขึ้นอยู่ไม่เพียงแต่กับประสิทธิภาพของฮาร์ดแวร์ควอนตัมเท่านั้น แต่ยังรวมถึงการใช้งานอุปกรณ์ควบคุมอิเล็กทรอนิกส์ที่ใช้ในการรับและประมวลผลข้อมูลคลาสสิกที่ได้จากการวัดค่าซินโดรม ในกรณีของเรา การเริ่มต้นทั้งคิวบิตซินโดรมและแฟล็กผ่านการตอบสนองแบบเรียลไทม์ระหว่างรอบการวัดสามารถช่วยลดข้อผิดพลาดได้ ในระดับการถอดรหัส แม้ว่าจะมีโปรโตคอลบางอย่างสำหรับการดำเนินการ QEC แบบอะซิงโครนัส (asynchronously) ภายในรูปแบบ FT [7, 8] แต่อัตราที่ได้รับค่าซินโดรมควรจะสอดคล้องกับเวลาประมวลผลคลาสสิกของมันเพื่อหลีกเลี่ยงการสะสมของข้อมูลซินโดรมที่เพิ่มขึ้น นอกจากนี้ โปรโตคอลบางอย่าง เช่น การใช้สถานะเมจิกสำหรับเกต T เชิงตรรกะ [9] จำเป็นต้องมีการใช้การป้อนกลับแบบเรียลไทม์ (real-time feed-forward) ดังนั้น วิสัยทัศน์ระยะยาวของ QEC ไม่ได้มุ่งเน้นไปที่เป้าหมายสูงสุดเพียงอย่างเดียว แต่ควรมองว่าเป็นกระบวนการต่อเนื่องของงานที่เกี่ยวข้องกันอย่างลึกซึ้ง เส้นทางทดลองในการพัฒนาเทคโนโลยีนี้จะประกอบด้วยการสาธิตงานเหล่านี้แยกกันก่อน แล้วจึงค่อยๆ รวมเข้าด้วยกันในภายหลัง โดยยังคงปรับปรุงเมตริกที่เกี่ยวข้องอย่างต่อเนื่อง ความก้าวหน้าบางส่วนนี้สะท้อนให้เห็นในความก้าวหน้าล่าสุดมากมายในระบบควอนตัมในแพลตฟอร์มทางกายภาพต่างๆ ซึ่งได้สาธิตหรือประมาณแง่มุมต่างๆ ของสิ่งที่ต้องการสำหรับการคำนวณควอนตัมแบบ FT โดยเฉพาะอย่างยิ่ง การเตรียมสถานะเชิงตรรกะแบบ FT ได้รับการสาธิตในไอออน [10] นิวเคลียร์สปินในเพชร [11] และคิวบิตแบบตัวนำยิ่งยวด [12] การวัดค่าซินโดรมซ้ำๆ ได้รับการแสดงให้เห็นในคิวบิตแบบตัวนำยิ่งยวดในรหัสตรวจจับข้อผิดพลาดขนาดเล็ก [13, 14] รวมถึงการแก้ไขข้อผิดพลาดบางส่วน [15] เช่นเดียวกับชุดเกตคิวบิตเดี่ยวแบบสากล (แต่ไม่ใช่ FT) [16] การสาธิตแบบ FT ของชุดเกตสากลบนคิวบิตเชิงตรรกะสองตัวได้ถูกรายงานล่าสุดในไอออน [17] ในขอบเขตของการแก้ไขข้อผิดพลาด ได้มีการตระหนักถึงรหัสพื้นผิว (surface code) ที่มีระยะห่างสามบนคิวบิตแบบตัวนำยิ่งยวดพร้อมกับการถอดรหัส [18] และการคัดกรอง [19] เช่นเดียวกับการดำเนินการ FT ของหน่วยความจำควอนตัมที่ได้รับการปกป้องแบบไดนามิกโดยใช้รหัสสี (color code) [20] และการเตรียมสถานะ การดำเนินการ และการวัดค่าแบบ FT รวมถึงสเตบิไลเซอร์ (stabilizers) ของสถานะเชิงตรรกะในรหัส Bacon-Shor ในไอออน [20, 21] ในที่นี้ เราได้รวมความสามารถของการตอบสนองแบบเรียลไทม์บนระบบคิวบิตแบบตัวนำยิ่งยวดเข้ากับโปรโตคอลการถอดรหัสแบบความน่าจะเป็นสูงสุด (maximum likelihood decoding protocol) ที่ยังไม่เคยมีการสำรวจในเชิงทดลองมาก่อน เพื่อปรับปรุงความอยู่รอดของสถานะเชิงตรรกะ เราสาธิตเครื่องมือเหล่านี้ในฐานะส่วนหนึ่งของการดำเนินการ FT ของรหัส subsystem [22] คือรหัส heavy-hexagon [1] บนโปรเซสเซอร์ควอนตัมแบบตัวนำยิ่งยวด สิ่งสำคัญในการทำให้การใช้งานรหัสนี้ทนทานต่อความผิดพลาดของเราคือคิวบิตแฟล็ก (flag qubits) ซึ่งเมื่อพบว่าไม่เป็นศูนย์ จะแจ้งเตือนตัวถอดรหัสถึงข้อผิดพลาดในวงจร ด้วยการรีเซ็ตคิวบิตแฟล็กและซินโดรมตามเงื่อนไขหลังแต่ละรอบการวัดซินโดรม เราปกป้องระบบของเราจากข้อผิดพลาดที่เกิดจากความไม่สมมาตรของสัญญาณรบกวนที่มีอยู่ในตัวมันเองเนื่องจากการผ่อนคลายพลังงาน (energy relaxation) นอกจากนี้ เรายังใช้ประโยชน์จากกลยุทธ์การถอดรหัสที่อธิบายไว้ล่าสุด [15] และขยายแนวคิดการถอดรหัสเพื่อรวมแนวคิดความน่าจะเป็นสูงสุด [4, 23, 24] ผลลัพธ์ รหัส heavy-hexagon และวงจรหลายรอบ รหัส heavy-hexagon ที่เราพิจารณาเป็นรหัสที่มีคิวบิต n = 9 เข้ารหัสคิวบิตเชิงตรรกะ k = 1 ที่มีระยะห่าง d = 3 [1] กลุ่มเกจ Z และ X (ดูรูปที่ 1a) และกลุ่มสเตบิไลเซอร์ถูกสร้างขึ้นโดย กลุ่มสเตบิไลเซอร์ S เป็นศูนย์กลางของกลุ่มเกจที่สอดคล้องกัน. ซึ่งหมายความว่าสเตบิไลเซอร์ ซึ่งเป็นผลคูณของตัวดำเนินการเกจ สามารถอนุมานได้จากการวัดเฉพาะตัวดำเนินการเกจเท่านั้น ตัวดำเนินการเชิงตรรกะสามารถเลือกให้เป็น XL = X1X2X3 และ ZL = Z1Z3Z7. กลุ่มเกจ Z (สีน้ำเงิน) และ X (สีแดง) (สมการที่ 1 และ 2) ที่แมปไปยังคิวบิต 23 ตัวที่ต้องการสำหรับรหัส heavy-hexagon ที่มีระยะห่างสาม คิวบิตรหัส (Q1 – Q9) แสดงเป็นสีเหลือง คิวบิตซินโดรม (Q17, Q19, Q20, Q22) ที่ใช้สำหรับสเตบิไลเซอร์ Z เป็นสีน้ำเงิน และคิวบิตแฟล็กและซินโดรมที่ใช้ในสเตบิไลเซอร์ X เป็นสีขาว ลำดับและทิศทางที่ใช้เกต CX ภายในแต่ละส่วนย่อย (0 ถึง 4) จะแสดงด้วยลูกศรที่มีหมายเลข ไดอะแกรมวงจรของการวัดซินโดรมรอบเดียว รวมถึงสเตบิไลเซอร์ X และ Z ไดอะแกรมวงจรแสดงถึงการขนานกันของเกตที่ได้รับอนุญาต: เกตที่อยู่ภายในขอบเขตที่กำหนดโดยอุปสรรคการกำหนดเวลา (เส้นประแนวตั้งสีเทา) เนื่องจากระยะเวลาของเกตสองคิวบิตแต่ละอันแตกต่างกัน การกำหนดเวลาเกตสุดท้ายจะถูกกำหนดด้วยการดำเนินการแบบ as-late-as-possible มาตรฐาน หลังจากนั้นจะมีการเพิ่ม dynamical decoupling ให้กับคิวบิตข้อมูลหากมีเวลา การดำเนินการวัดและรีเซ็ตจะถูกแยกออกจากเกตอื่นๆ โดยอุปสรรค เพื่อให้สามารถเพิ่ม dynamical decoupling ที่สม่ำเสมอให้กับคิวบิตข้อมูลที่ไม่ได้ใช้งาน , **d** กราฟการถอดรหัสสำหรับการวัดสเตบิไลเซอร์ Z และ X สามรอบตามลำดับ พร้อมสัญญาณรบกวนระดับวงจร ช่วยให้สามารถแก้ไขข้อผิดพลาด X และ Z ตามลำดับ โหนดสีน้ำเงินและสีแดงในกราฟแสดงถึงผลต่างของซินโดรม ในขณะที่โหนดสีดำคือขอบเขต โหนดจะถูกติดป้ายด้วยประเภทของการวัดสเตบิไลเซอร์ (Z หรือ X) พร้อมกับดัชนีที่ระบุสเตบิไลเซอร์ และตัวยกที่ระบุรอบ ขอบสีดำ เกิดจากข้อผิดพลาด Pauli Y บนคิวบิตรหัส (และจึงมีขนาด 2 เท่านั้น) เชื่อมต่อกราฟทั้งสองใน c และ d แต่ไม่ได้ใช้ในการถอดรหัสแบบจับคู่ ขอบขนาด 4 ซึ่งไม่ถูกใช้โดยการจับคู่ แต่ถูกใช้ในการถอดรหัสแบบความน่าจะเป็นสูงสุด สีเป็นเพียงเพื่อความชัดเจน การแปลแต่ละครั้งในเวลาด้วยหนึ่งรอบก็จะได้ขอบที่ถูกต้อง (มีการเปลี่ยนแปลงเล็กน้อยที่ขอบเขตเวลา) นอกจากนี้ ยังไม่ได้แสดงขอบขนาด 3 ใดๆ a b c e f ในที่นี้เราจะเน้นที่วงจร FT แบบเฉพาะเจาะจง เทคนิคหลายอย่างของเราสามารถนำไปใช้ได้ทั่วไปกับรหัสและวงจรที่แตกต่างกัน วงจรย่อยสองวงจร แสดงในรูปที่ 1b ถูกสร้างขึ้นเพื่อวัดตัวดำเนินการเกจ X และ Z วงจรวัดค่าเกจ Z ยังได้รับข้อมูลที่เป็นประโยชน์โดยการวัดคิวบิตแฟล็ก เราเตรียมสถานะรหัสในสถานะเชิงตรรกะ |0⟩L (|0⟩) โดยการเตรียมคิวบิตเก้าตัวในสถานะ |+⟩ และวัดค่าเกจ X (เกจ Z) จากนั้นเราดำเนินการวัดค่าซินโดรม r รอบ โดยหนึ่งรอบประกอบด้วยการวัดค่าเกจ Z ตามด้วยการวัดค่าเกจ X (หรือในทางกลับกัน) สุดท้าย เราอ่านค่าคิวบิตรหัสทั้งเก้าในฐาน Z (X) เราดำเนินการทดลองเดียวกันสำหรับสถานะเชิงตรรกะเริ่มต้น |1⟩L และ |+⟩L เช่นกัน โดยเพียงแค่เริ่มต้นคิวบิตเก้าตัวใน |1⟩ และ |+⟩ ตามลำดับ อัลกอริทึมการถอดรหัส ในการคำนวณควอนตัมแบบ FT ตัวถอดรหัสคืออัลกอริทึมที่รับค่าการวัดค่าซินโดรมจากรหัสแก้ไขข้อผิดพลาดควอนตัมเป็นอินพุตและส่งออกค่าแก้ไขไปยังคิวบิตหรือข้อมูลการวัด ในส่วนนี้ เราจะอธิบายอัลกอริทึมการถอดรหัสสองอัลกอริทึม: การถอดรหัสแบบจับคู่ที่สมบูรณ์แบบ (perfect matching decoding) และการถอดรหัสแบบความน่าจะเป็นสูงสุด (maximum likelihood decoding) ไฮเปอร์กราฟการถอดรหัส [15] เป็นคำอธิบายที่กระชับของข้อมูลที่รวบรวมได้จากวงจร FT และพร้อมใช้งานสำหรับอัลกอริทึมการถอดรหัส ประกอบด้วยชุดของจุดยอด หรือเหตุการณ์ที่ไวต่อข้อผิดพลาด V และชุดของไฮเปอร์เอดจ์ E ซึ่งเข้ารหัสความสัมพันธ์ระหว่างเหตุการณ์ที่เกิดจากข้อผิดพลาดในวงจร รูปที่ 1c–f แสดงส่วนต่างๆ ของไฮเปอร์กราฟการถอดรหัสสำหรับการทดลองของเรา การสร้างไฮเปอร์กราฟการถอดรหัสสำหรับวงจรสเตบิไลเซอร์ที่มีสัญญาณรบกวนแบบ Pauli สามารถทำได้โดยใช้การจำลอง Gottesman-Knill [25] มาตรฐาน หรือเทคนิค Pauli tracing ที่คล้ายคลึงกัน [26] ก่อนอื่น เหตุการณ์ที่ไวต่อข้อผิดพลาดจะถูกสร้างขึ้นสำหรับแต่ละการวัดที่กำหนดผลลัพธ์ ซึ่งผลลัพธ์ m ∈ {0, 1} สามารถคาดการณ์ได้โดยการบวกผลลัพธ์การวัดจากชุดของการวัดก่อนหน้า M ที่เป็นโมดูโลสอง นั่นคือ สำหรับวงจรที่ไม่มีข้อผิดพลาด, m = ∑_{m'∈S_M} m' (mod 2) โดยที่ชุด S_M สามารถหาได้จากการจำลองวงจร ตั้งค่าของเหตุการณ์ที่ไวต่อข้อผิดพลาดเป็น m − FM(mod2) ซึ่งเป็นศูนย์ (เรียกว่า trivial) ในกรณีที่ไม่มีข้อผิดพลาด ดังนั้น การสังเกตเหตุการณ์ที่ไวต่อข้อผิดพลาดที่ไม่ใช่ศูนย์ (เรียกว่า non-trivial) แสดงว่าวงจรได้รับผลกระทบจากข้อผิดพลาดอย่างน้อยหนึ่งครั้ง ในวงจรของเรา เหตุการณ์ที่ไวต่อข้อผิดพลาดคือการวัดค่าคิวบิตแฟล็ก หรือผลต่างของการวัดสเตบิไลเซอร์เดียวกันซ้ำๆ (บางครั้งเรียกว่า difference syndromes) ถัดไป ไฮเปอร์เอดจ์จะถูกเพิ่มเข้ามาโดยการพิจารณาข้อผิดพลาดของวงจร โมเดลของเรามีโอกาสเกิดข้อผิดพลาด pC สำหรับส่วนประกอบวงจรหลายส่วน ในที่นี้ เราแยกความแตกต่างระหว่างการดำเนินการเอกลักษณ์ id บนคิวบิตในช่วงเวลาที่คิวบิตอื่นกำลังดำเนินการเกตแบบ unitary กับการดำเนินการเอกลักษณ์ idm บนคิวบิตเมื่อคิวบิตอื่นกำลังดำเนินการวัดและรีเซ็ต เราจะรีเซ็ตคิวบิตหลังจากที่ได้วัดค่าแล้ว ในขณะที่เราเริ่มต้นคิวบิตที่ยังไม่ได้ใช้ในการทดลอง นอกจากนี้ cx คือเกต controlled-not, h คือเกต Hadamard และ x, y, z คือเกต Pauli (ดูหัวข้อ Methods “IBM_Peekskill and experimental details” สำหรับรายละเอียดเพิ่มเติม) ค่าตัวเลขสำหรับ pC จะแสดงอยู่ในหัวข้อ Methods “IBM_Peekskill and experimental details” โมเดลข้อผิดพลาดของเราคือสัญญาณรบกวนแบบ depolarizing noise สำหรับข้อผิดพลาดในการเริ่มต้นและรีเซ็ต จะมีการใช้ Pauli X ด้วยความน่าจะเป็น pinint และ preset ตามลำดับหลังจากการเตรียมสถานะที่สมบูรณ์แบบ สำหรับข้อผิดพลาดในการวัด Pauli X จะถูกใช้ด้วยความน่าจะเป็น px ก่อนการวัดที่สมบูรณ์แบบ เกต unitary หนึ่งคิวบิต (เกตสองคิวบิต) C จะได้รับผลกระทบด้วยความน่าจะเป็น pC หนึ่งในสาม (สิบห้า) ข้อผิดพลาด Pauli ที่ไม่ใช่เอกลักษณ์ตามหลังเกตที่สมบูรณ์แบบ มีโอกาสเท่ากันที่จะเกิดข้อผิดพลาด Pauli ใดๆ ในสาม (สิบห้า) ข้อ เมื่อเกิดข้อผิดพลาดเดี่ยวในวงจร จะส่งผลให้เหตุการณ์ที่ไวต่อข้อผิดพลาดบางส่วนไม่เป็นศูนย์ ชุดของเหตุการณ์ที่ไวต่อข้อผิดพลาดนี้จะกลายเป็นไฮเปอร์เอดจ์ ชุดของไฮเปอร์เอดจ์ทั้งหมดคือ E ซึ่งไฮเปอร์เอดจ์ที่แตกต่างกันสองอันอาจนำไปสู่ไฮเปอร์เอดจ์เดียวกัน ดังนั้นแต่ละไฮเปอร์เอดจ์อาจถูกมองว่าแสดงถึงชุดของข้อผิดพลาด ซึ่งแต่ละข้อผิดพลาดเองทำให้เหตุการณ์ในไฮเปอร์เอดจ์ไม่เป็นศูนย์ ความน่าจะเป็นที่เกี่ยวข้องกับแต่ละไฮเปอร์เอดจ์ ซึ่งในอันดับแรกคือผลรวมของความน่าจะเป็นของข้อผิดพลาดในชุด ข้อผิดพลาดอาจนำไปสู่ข้อผิดพลาดที่เมื่อแพร่กระจายไปยังส่วนท้ายของวงจร จะสลับกับตัวดำเนินการเชิงตรรกะของรหัสตั้งแต่หนึ่งตัวขึ้นไป ซึ่งจำเป็นต้องมีการแก้ไขเชิงตรรกะ เราสันนิษฐานเพื่อความทั่วไปว่ารหัสมี k คิวบิตเชิงตรรกะ และฐานของตัวดำเนินการเชิงตรรกะ 2k เราสามารถติดตามตัวดำเนินการเชิงตรรกะที่สลับกับข้อผิดพลาดโดยใช้เวกเตอร์จาก {0, 1}^k ดังนั้นแต่ละไฮเปอร์เอดจ์ h จะถูกติดป้ายด้วยเวกเตอร์เหล่านี้ γ เรียกว่าป้ายกำกับเชิงตรรกะ (logical label) โปรดทราบว่าหากรหัสมีระยะห่างอย่างน้อยสามแต่ละไฮเปอร์เอดจ์จะมีป้ายกำกับเชิงตรรกะที่ไม่ซ้ำกัน สุดท้าย เราสังเกตว่าอัลกอริทึมการถอดรหัสสามารถเลือกที่จะทำให้ไฮเปอร์กราฟการถอดรหัสง่ายขึ้นได้หลายวิธี วิธีหนึ่งที่เราใช้เสมอคือกระบวนการ deflagging การวัดค่าแฟล็กจากคิวบิต 16, 18, 21, 23 จะถูกเพิกเฉยโดยไม่มีการแก้ไขใดๆ หากแฟล็ก 11 ไม่เป็นศูนย์และ 12 เป็นศูนย์ ให้ใช้ Z กับ 2 หาก 12 ไม่เป็นศูนย์และ 11 เป็นศูนย์ ให้ใช้ Z กับคิวบิต 6 หากแฟล็ก 13 ไม่เป็นศูนย์และ 14 เป็นศูนย์ ให้ใช้ Z กับคิวบิต 4 หาก 14 ไม่เป็นศูนย์และ 13 เป็นศูนย์ ให้ใช้ Z กับคิวบิต 8 ดู [15] สำหรับรายละเอียดว่าทำไมจึงเพียงพอสำหรับการทนทานต่อความผิดพลาด ซึ่งหมายความว่าแทนที่จะรวมเหตุการณ์ที่ไวต่อข้อผิดพลาดจากการวัดค่าคิวบิตแฟล็กโดยตรง เราจะประมวลผลข้อมูลล่วงหน้าโดยใช้ข้อมูลแฟล็กเพื่อใช้การแก้ไข Pauli Z เสมือนและปรับเหตุการณ์ที่ไวต่อข้อผิดพลาดที่ตามมาให้เหมาะสม ไฮเปอร์เอดจ์สำหรับไฮเปอร์กราฟที่ deflagged สามารถพบได้ผ่านการจำลองสเตบิไลเซอร์ที่รวมการแก้ไข Z การแก้ไขต่างๆ การใช้ r เพื่อระบุจำนวนรอบ หลังจากการ deflagging ขนาดของชุด V สำหรับการทดลองฐาน Z (หรือฐาน X) คือ |V| = 6r + 2 (หรือ 6r + 4) เนื่องจากมีการวัดสเตบิไลเซอร์หกตัวต่อรอบ และมีสเตบิไลเซอร์เริ่มต้นสอง (หรือสี่) ตัวหลังจากการเตรียมสถานะ ขนาดของ E จะคล้ายคลึงกัน |E| = 60r − 13 (หรือ 60r − 1) สำหรับ r > 0 เมื่อพิจารณาข้อผิดพลาด X และ Z แยกกัน ปัญหาการหาการแก้ไขที่มีน้ำหนักน้อยที่สุด (minimum weight error correction) สำหรับรหัสพื้นผิวสามารถลดทอนเป็นการหาการจับคู่ที่สมบูรณ์แบบที่มีน้ำหนักน้อยที่สุด (minimum weight perfect matching) ในกราฟ [4] ตัวถอดรหัสแบบจับคู่ยังคงได้รับการศึกษาเนื่องจากความเป็นไปได้ในทางปฏิบัติ [27] และความสามารถในการนำไปใช้ได้อย่างกว้างขวาง [28, 29] ในส่วนนี้ เราจะอธิบายตัวถอดรหัสแบบจับคู่สำหรับรหัส heavy-hexagon ที่มีระยะห่างสามของเรา กราฟการถอดรหัส หนึ่งสำหรับข้อผิดพลาด X (รูปที่ 1c) และหนึ่งสำหรับข้อผิดพลาด Z (รูปที่ 1d) สำหรับการจับคู่ที่สมบูรณ์แบบที่มีน้ำหนักน้อยที่สุด แท้จริงแล้วเป็นกราฟย่อยของไฮเปอร์กราฟการถอดรหัสในส่วนก่อนหน้า เราจะเน้นที่กราฟสำหรับการแก้ไขข้อผิดพลาด X ที่นี่ เนื่องจากกราฟข้อผิดพลาด Z ก็คล้ายคลึงกัน ในกรณีนี้ จากไฮเปอร์กราฟการถอดรหัส เราจะเก็บโหนด VZ ที่สอดคล้องกับการวัดค่า Z-stabilizer (หรือผลต่างของการวัดซ้ำๆ) และเอดจ์ (เช่น ไฮเปอร์เอดจ์ที่มีขนาดสอง) ระหว่างโหนดเหล่านั้น นอกจากนี้ จะมีการสร้างจุดยอดขอบเขต b และไฮเปอร์เอดจ์ขนาดหนึ่งในรูปแบบ {v} โดยที่ v ∈ VZ จะแสดงโดยการรวมเอดจ์ {v, b} เอดจ์ทั้งหมดในกราฟข้อผิดพลาด X จะได้รับความน่าจะเป็นและป้ายกำกับเชิงตรรกะจากไฮเปอร์เอดจ์ที่สอดคล้องกัน (ดูตารางที่ 1 สำหรับข้อมูลเอดจ์ข้อผิดพลาด X และ Z สำหรับการทดลอง 2 รอบ) อัลกอริทึมการจับคู่ที่สมบูรณ์แบบจะรับกราฟที่มีเอดจ์ถ่วงน้ำหนักและชุดโหนดที่ไฮไลต์ซึ่งมีจำนวนเป็นเลขคู่ และส่งคืนชุดของเอดจ์ในกราฟที่เชื่อมต่อโหนดที่ไฮไลต์ทั้งหมดเป็นคู่ๆ และมีน้ำหนักรวมน้อยที่สุดในบรรดาชุดเอดจ์ดังกล่าวทั้งหมด ในกรณีของเรา โหนดที่ไฮไลต์คือเหตุการณ์ที่ไวต่อข้อผิดพลาดที่ไม่เป็นศูนย์ (หากมีจำนวนคี่ โหนดขอบเขตก็จะถูกไฮไลต์ด้วย) และน้ำหนักเอดจ์จะถูกเลือกให้เป็นหนึ่งทั้งหมด (วิธีมาตรฐาน) หรือตั้งค่าเป็น exp(−log P_e) โดยที่ P_e คือความน่าจะเป็นของเอดจ์ (วิธีวิเคราะห์) การเลือกหลังนี้หมายความว่าน้ำหนักรวมของชุดเอดจ์เท่ากับ log-likelihood ของชุดนั้น และการจับคู่ที่สมบูรณ์แบบที่มีน้ำหนักน้อยที่สุดจะพยายามเพิ่ม likelihood นี้เหนือเอดจ์ในกราฟ เมื่อได้การจับคู่ที่สมบูรณ์แบบที่มีน้ำหนักน้อยที่สุดแล้ว สามารถใช้ป้ายกำกับเชิงตรรกะของเอดจ์ในการจับคู่เพื่อตัดสินใจแก้ไขสถานะเชิงตรรกะ หรืออีกทางหนึ่ง กราฟข้อผิดพลาด X (ข้อผิดพลาด Z) สำหรับตัวถอดรหัสแบบจับคู่เป็นเช่นนั้น โดยแต่ละเอดจ์สามารถเชื่อมโยงกับคิวบิตรหัส (หรือข้อผิดพลาดในการวัด) โดยที่การรวมเอดจ์ในการจับคู่บ่งชี้ว่าควรใช้การแก้ไข X (Z) กับคิวบิตที่สอดคล้องกัน การถอดรหัสแบบความน่าจะเป็นสูงสุด (MLD) เป็นวิธีที่เหมาะสมที่สุด แต่ไม่สามารถขยายขนาดได้ สำหรับการถอดรหัสรหัสแก้ไขข้อผิดพลาดควอนตัม ในแนวคิดดั้งเดิม MLD ถูกนำไปใช้กับโมเดลสัญญาณรบกวนเชิงปรากฏการณ์ (phenomenological noise models) ซึ่งข้อผิดพลาดเกิดขึ้นก่อนที่จะมีการวัดค่าซินโดรม [24, 30] แน่นอนว่านี่เป็นการละเลยกรณีที่สมจริงกว่าซึ่งข้อผิดพลาดสามารถแพร่กระจายผ่านวงจรการวัดค่าซินโดรม เมื่อเร็วๆ นี้ MLD ได้ถูกขยายเพื่อรวมสัญญาณรบกวนในวงจร [23, 31] ในที่นี้ เราจะอธิบายว่า MLD แก้ไขสัญญาณรบกวนในวงจรได้อย่างไรโดยใช้ไฮเปอร์กราฟการถอดรหัส MLD อนุมานการแก้ไขเชิงตรรกะที่มีความเป็นไปได้มากที่สุดเมื่อพิจารณาจากการสังเกตเหตุการณ์ที่ไวต่อข้อผิดพลาด ซึ่งทำได้โดยการคำนวณการแจกแจงความน่าจะเป็น Pr[β, γ] โดยที่ β แทนเหตุการณ์ที่ไวต่อข้อผิดพลาด และ γ แทนการแก้ไขเชิงตรรกะ เราสามารถคำนวณ Pr[β, γ] โดยการรวมไฮเปอร์เอดจ์ทุกอันจากไฮเปอร์กราฟการถอดรหัส รูปที่ 1c–f เริ่มต้นจากการแจกแจงที่ไม่มีข้อผิดพลาด นั่นคือ Pr[0^|V|, 0^2k] = 1 หากไฮเปอร์เอดจ์ h มีความน่าจะเป็น ph ที่จะเกิดขึ้น โดยไม่ขึ้นกับไฮเปอร์เอดจ์อื่นใด เราจะรวม h โดยดำเนินการอัปเดต โดยที่ v_h เป็นเพียงการแสดงค่าแบบเวกเตอร์ไบนารีของไฮเปอร์เอดจ์ การอัปเดตนี้ควรดำเนินการหนึ่งครั้งสำหรับทุกไฮเปอร์เอดจ์ใน E เมื่อคำนวณ Pr[β, γ] แล้ว เราสามารถใช้เพื่ออนุมานการแก้ไขเชิงตรรกะที่ดีที่สุด หาก β* ถูกสังเกตในการทดลอง แสดงให้เห็นว่าการวัดค่าตัวดำเนินการเชิงตรรกะควรได้รับการแก้ไขอย่างไร สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับการใช้งาน MLD เฉพาะเจาะจง โปรดดูที่ Methods “Maximum likelihood implementations” การดำเนินการทดลอง สำหรับการสาธิตนี้ เราใช้ ibm_peekskill v2.0.0 โปรเซสเซอร์ IBM Quantum Falcon ขนาด 27 คิวบิต [32] ซึ่งแผนที่การเชื่อมต่อ (coupling map) ช่วยให้สามารถใช้รหัส heavy-hexagon ที่มีระยะห่างสามได้ ดูรูปที่ 1 เวลาทั้งหมดสำหรับการวัดคิวบิตและการรีเซ็ตตามเงื่อนไขหลังจากการวัด ค่านี้สำหรับแต่ละรอบคือ 768ns และเท่ากันสำหรับคิวบิตทั้งหมด การวัดค่าซินโดรมและการรีเซ็ตทั้งหมดเกิดขึ้นพร้อมกันเพื่อประสิทธิภาพที่ดีขึ้น ลำดับ dynamical decoupling แบบ Xπ-Xπ แบบง่ายถูกเพิ่มเข้าไปในคิวบิตรหัสทั้งหมดในช่วงเวลาที่ไม่ได้ใช้งาน การรั่วไหลของคิวบิต (Qubit leakage) เป็นเหตุผลสำคัญที่ทำให้โมเดลข้อผิดพลาดแบบ Pauli depolarizing ที่สมมติโดยการออกแบบตัวถอดรหัสอาจไม่ถูกต้อง ในบางกรณี เราสามารถตรวจจับได้ว่าคิวบิตรั่วไหลออกจากปริภูมิการคำนวณหรือไม่ ณ เวลาที่วัดค่า (ดู Methods “Post-selection method” สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธี post-selection และข้อจำกัด) การใช้สิ่งนี้ เราสามารถ post-select ข้อมูลการทดลองเมื่อตรวจไม่พบการรั่วไหล คล้ายกับ [18] ในรูปที่ 2a เราเตรียมสถานะเชิงตรรกะ |0⟩L (|0⟩) และดำเนินการ r รอบการวัดค่าซินโดรม โดยหนึ่งรอบรวมถึงสเตบิไลเซอร์ X และ Z (เวลารวมประมาณ 5.3 μs ต่อรอบ, รูปที่ 1b) โดยใช้การถอดรหัสแบบ perfect matching เชิงวิเคราะห์บนชุดข้อมูลทั้งหมด (500,000 ช็อตต่อรอบ) เราดึงค่าข้อผิดพลาดเชิงตรรกะในรูปที่ 2a สามเหลี่ยมสีแดง (สีน้ำเงิน) รายละเอียดของพารามิเตอร์ที่ปรับให้เหมาะสมที่ใช้ในการถอดรหัสแบบ perfect matching เชิงวิเคราะห์ สามารถพบได้ใน Methods “IBM_Peekskill and experimental details” การปรับเส้นโค้งการลดลงทั้งหมด (สมการที่ 14) สูงสุดถึง 10 รอบ เราดึงค่าข้อผิดพลาดเชิงตรรกะต่อรอบโดยไม่มี post-selection ในรูปที่ 2b เป็น 0.059(2) (0.058(3)) สำหรับ |0⟩L (|0⟩) และ 0.113(5) (0.107(4)) สำหรับ |1⟩L (|1⟩) ข้อผิดพลาดเชิงตรรกะเทียบกับจำนวนรอบการวัดค่าซินโดรม r โดยหนึ่งรอบรวมถึงการวัดสเตบิไลเซอร์ Z และ X สามเหลี่ยมชี้ไปทางขวา (สีน้ำเงิน) (สามเหลี่ยมสีแดง) แสดงถึงข้อผิดพลาดเชิงตรรกะที่ได้จากการใช้การถอดรหัสแบบ perfect matching เชิงวิเคราะห์กับข้อมูลการทดลองดิบสำหรับสถานะ |0⟩L (|0⟩) สี่เหลี่ยมสีฟ้าอ่อน (วงกลมสีแดงอ่อน) แสดงสำหรับสถานะ |+⟩L (| +⟩) ด้วยวิธีการถอดรหัสเดียวกัน แต่ใช้ข้อมูลการทดลองที่ผ่านการคัดกรองการรั่วไหลแล้ว แถบแสดงข้อผิดพลาดแสดงถึงข้อผิดพลาดจากการสุ่มตัวอย่างของแต่ละรอบ (500,000 ช็อตสำหรับข้อมูลดิบ จำนวนช็อตแปรผันสำหรับข้อมูลที่ผ่านการคัดกรอง) เส้นประแสดงการปรับให้เหมาะสมของข้อผิดพลาดที่แสดงใน b การใช้วิธีการถอดรหัสเดียวกันกับข้อมูลที่ผ่านการคัดกรองการรั่วไหล แสดงให้เห็นการลดลงอย่างมากในข้อผิดพลาดโดยรวมสำหรับสถานะเชิงตรรกะทั้งสี่ ดู Methods “Post-selection method” สำหรับรายละเอียดเกี่ยวกับการ post-selection อัตราการปฏิเสธต่อรอบที่ปรับได้สำหรับ |0⟩L, |1⟩L, |+⟩L, |-⟩L คือ 4.91%, 4.64%, 4.37%, และ 4.89% ตามลำดับ แถบแสดงข้อผิดพลาดแสดงถึงค่าเบี่ยงเบนมาตรฐานของอัตราที่ปรับได้ , **d** โดยใช้ข้อมูลที่ผ่านการคัดกรอง เราเปรียบเทียบข้อผิดพลาดเชิงตรรกะที่ได้จากตัวถอดรหัสทั้งสี่: matching uniform (สีชมพู), matching analytical (สีเขียว), matching analytical with soft information (สีเทา), และ maximum likelihood (สีน้ำเงิน) (ดูรูปที่ 6 สำหรับ |1⟩L และ |-⟩L) อัตราที่ปรับได้ที่แสดงใน e, f แถบแสดงข้อผิดพลาดแสดงถึงข้อผิดพลาดจากการสุ่มตัวอย่าง , **f** การเปรียบเทียบอัตราข้อผิดพลาดที่ปรับได้ต่อรอบสำหรับสถานะเชิงตรรกะทั้งสี่ โดยใช้ matching uniform (สีชมพู), matching analytical (สีเขียว), matching analytical with soft information (สีเทา), และ maximum likelihood (สีน้ำเงิน) แถบแสดงถึงค่าเบี่ยงเบนมาตรฐานของอัตราที่ปรับได้ a b c e การใช้วิธีการถอดรหัสเดียวกันกับข้อมูลที่ผ่านการคัดกรองการรั่วไหลช่วยลดข้อผิดพลาดเชิงตรรกะในรูปที่ 2a และส่งผลให้อัตราข้อผิดพลาดที่ปรับได้เป็น 0.041(1) (0.044(4)) สำหรับ |0⟩L (|0⟩) และ 0.088(3) (0.085(3)) สำหรับ |1⟩L (|1⟩) ดังแสดงในรูปที่ 2b อัตราการปฏิเสธต่อรอบจากการ post-selection สำหรับ |0⟩L, |1⟩L, |+⟩L, และ |-⟩L คือ 4.91%, 4.64%, 4.37%, และ 4.89% ตามลำดับ ดู Methods “Post-selection method” สำหรับรายละเอียด ในรูปที่ 2c–f เราเปรียบเทียบข้อผิดพลาดเชิงตรรกะสำหรับแต่ละรอบและข้อผิดพลาดเชิงตรรกะต่อรอบที่ดึงออกมา ซึ่งได้จากชุดข้อมูลที่ผ่านการคัดกรองโดยใช้ตัวถอดรหัสทั้งสามที่อธิบายไว้ก่อนหน้านี้ในหัวข้อ “Decoding algorithms” เรายังรวมเวอร์ชันของตัวถอดรหัสเชิงวิเคราะห์ที่ใช้ประโยชน์จาก soft-information [33] ซึ่งอธิบายไว้ใน Methods “Soft-information decoding” เราสังเกตเห็น (ดูรูปที่ 2e, f) การปรับปรุงที่สอดคล้องกันในการถอดรหัส จาก matching uniform (สีชมพู) ไปสู่ matching analytical (สีเขียว) ไปสู่ matching analytical with soft information และไปสู่ maximum likelihood (สีเทา) แม้ว่าการปรับปรุงนี้จะน้อยกว่ามากสำหรับสถานะเชิงตรรกะฐาน X การเปรียบเทียบเชิงปริมาณระหว่างตัวถอดรหัสทั้งสามสำหรับสถานะเชิงตรรกะทั้งสี่ที่ r = 2 รอบ จะมีให้ใน Methods “Logical error at r = 2 rounds” มีเหตุผลอย่างน้อยสามประการที่ทำให้สถานะฐาน X มีประสิทธิภาพแย่กว่าสถานะฐาน Z ประการแรกคือความไม่สมมาตรตามธรรมชาติของวงจร ความลึกที่มากขึ้นที่จำเป็นสำหรับการวัดค่าสเตบิไลเซอร์ Z ทำให้มีเวลามากขึ้นที่ข้อผิดพลาด Z บนคิวบิตข้อมูลสามารถสะสมได้โดยไม่ถูกตรวจพบ สิ่งนี้ได้รับการสนับสนุนจากการจำลอง เช่น ใน [1] ซึ่งใช้ตัวถอดรหัสที่แตกต่างกัน และที่นี่ใน Methods “Simulation details” ซึ่งพบประสิทธิภาพที่แย่กว่าของฐาน X สำหรับรหัส d = 3 นี้ ประการที่สอง การตัดสินใจในการถอดรหัส โดยเฉพาะอย่างยิ่งขั้นตอน deflagging สามารถทำให้ความไม่สมมาตรแย่ลงได้โดยการแปลงข้อผิดพลาดในการวัดและการรีเซ็ตให้เป็นข้อผิดพลาด Z บนคิวบิตข้อมูล ซึ่งส่งผลให้มีอัตราข้อผิดพลาด Z ที่มีประสิทธิภาพสูงซึ่งไม่สามารถปรับปรุงได้มาก แม้แต่ด้วยการถอดรหัสแบบความน่าจะเป็นสูงสุด ในทางตรงกันข้าม หากเรา deflag เฉพาะการวัดรอบแรก ข้อผิดพลาดเชิงตรรกะของตัวถอดรหัสแบบความน่าจะเป็นสูงสุดใน r = 2 รอบ, |1⟩L การทดลอง ลดลงประมาณ 2.8% เป็น 18.02(7)% การถอดรหัสแบบ flagged เช่นนี้จะใช้เวลานานขึ้นสำหรับจำนวนรอบที่มากขึ้น เนื่องจากการเพิ่มโหนดแฟล็กในไฮเปอร์กราฟการถอดรหัสจะเพิ่มขนาดของมันอย่างมาก สุดท้าย ตัวถอดรหัสจะดีเท่ากับโมเดลสัญญาณรบกวนจากการทดลองของเรา แหล่งสัญญาณรบกวนที่ไม่ใช่แบบ depolarizing เช่น ข้อผิดพลาด ZZ แบบผู้ชม (spectator ZZ errors) ซึ่งเรารู้ว่ามีอยู่ ไม่ได้ถูกจำลองโดยตัวถอดรหัสใดๆ ของเรา และจะส่งผลเสียต่อสถานะฐาน X มากกว่า การประเมินที่แม่นยำยิ่งขึ้นและการรวมสัญญาณรบกวนจากการทดลองดังกล่าวและผลกระทบต่อความทนทานต่อความผิดพลาดเป็นหัวข้อสำคัญสำหรับการวิจัยเพิ่มเติม การอภิปราย ผลลัพธ์ที่นำเสนอในงานนี้เน้นย้ำถึงความสำคัญของความก้าวหน้าร่วมกันของฮาร์ดแวร์ควอนตัม ทั้งในด้านขนาดและคุณภาพ และการประมวลผลข้อมูลคลาสสิก ทั้งที่เกิดขึ้นพร้อมกับการดำเนินการวงจรและแบบอะซิงโครนัสกับมัน ดังที่อธิบายไว้ด้วยตัวถอดรหัสที่ศึกษา การทดลองของเราประกอบด้วยการวัดค่ากลางวงจรและการดำเนินการตามเงื่อนไขเป็นส่วนหนึ่งของโปรโตคอล QEC ความสามารถทางเทคนิคเหล่านี้ทำหน้าที่เป็นองค์ประกอบพื้นฐานสำหรับการปรับปรุงบทบาทของวงจรไดนามิกใน QEC ต่อไป เช่น เพื่อการแก้ไขแบบเรียลไทม์และการดำเนินการป้อนกลับอื่นๆ ที่จะมีความสำคัญต่อการคำนวณแบบ FT ขนาดใหญ่ นอกจากนี้ เรายังแสดงให้เห็นว่าแพลตฟอร์มทดลองสำหรับ QEC ขนาดและความสามารถเหล่านี้สามารถกระตุ้นแนวคิดใหม่ๆ ไปสู่ตัวถอดรหัสที่ทนทานยิ่งขึ้น การเปรียบเทียบของเราระหว่างตัวถอดรหัสแบบ perfect matching และ maximum likelihood เป็นจุดเริ่มต้นที่มีแนวโน้มที่ดีในการทำความเข้าใจการแลกเปลี่ยนระหว่างความสามารถในการขยายขนาดของตัวถอดรหัสกับประสิทธิภาพเมื่อมีสัญญาณรบกวนจากการทดลอง โมเดลสัญญาณรบกวนที่ดีขึ้นและเทคนิคการประมวลผลข้อผิดพลาดล่วงหน้า [34, 35] อาจปรับปรุงประสิทธิภาพและเวลาทำงานของตัวถอดรหัสเหล่านี้ ส่วนประกอบสำคัญเหล่านี้ทั้งหมดจะมีบทบาทสำคัญในรหัสที่มีระยะห่างมากขึ้น ซึ่งคุณภาพของการดำเนินการแบบเรียลไทม์ (การรีเซ็ตคิวบิตตามเงื่อนไขและการกำจัดสัญญาณรบกวนจากการรั่วไหล, โปรโตคอลการเทเลพอร์ตสำหรับเกตเชิงตรรกะ, และการถอดรหัส) พร้อมกับระดับสัญญาณรบกวนของอุปกรณ์ จะเป็นตัวกำหนดประสิทธิภาพของรหัส ซึ่งอาจทำให้สามารถสาธิตการลดข้อผิดพลาดเชิงตรรกะด้วยระยะห่างของรหัสที่เพิ่มขึ้น วิธีการ ความน่าจะเป็นของเอดจ์และการดำเนินการจับคู่ที่สมบูรณ์แบบด้วยน้ำหนักน้อยที่สุด เราใช้ทฤษฎีบท Gottesman-Knill [25] เพื่อแพร่กระจายข้อผิดพลาด Pauli ผ่านวงจร Clifford ของเราและกำหนดว่าเหตุการณ์ที่ไวต่อข้อผิดพลาดใดที่ทำให้ไม่เป็นศูนย์ ตัวอย่างแสดงในรูปที่ 3 หาก p คือความน่าจะเป็นของข้อผิดพลาด Pauli เฉพาะและ e คือชุดของเหตุการณ์ที่ไม่เป็นศูนย์ที่สอดคล้องกัน p จะถูกเพิ่มเข้าไปในความน่าจะเป็นของเอดจ์ pe ตัวอย่างสองตัวอย่างของการแพร่กระจาย Pauli ผ่านวงจรการวัดค่าแบบมีแฟล็กสำหรับตัวดำเนินการเกจ Z การแก้ไข Pauli Z อันเนื่องมาจากการ deflagging แสดงอยู่ในกล่องจุดไข่ปลาและขึ้นอยู่กับผลการวัดค่าคิวบิตแฟล็ก ในส่วนล่างของรูปภาพเป็นสีน้ำเงิน เกต cx ตามด้วยข้อผิดพลาด XY (สีน้ำเงิน) ที่มีความน่าจะเป็น pcx/15 เกต cx ถัดไปจะแพร่กระจายข้อผิดพลาด X ไปยังคิวบิตซินโดรม Q19 ทำให้การวัด m พลิกกลับ ในขณะเดียวกัน ข้อผิดพลาด Y บน Q2 จะแพร่กระจายไปโดยไม่เปลี่ยนแปลง (จะมีผลต่อรอบการวัดในอนาคต) ข้อผิดพลาดที่แพร่กระจายอยู่ในวงกลมจุดไข่ปลา โปรดทราบว่าการวัดค่าแฟล็ก b ไม่ได้พลิกกลับ เนื่องจากเกต Hadamard ทำให้ข้อผิดพลาด X กลายเป็นข้อผิดพลาด Z ที่ไม่เป็นอันตราย ในส่วนบนของรูปภาพ เกิดข้อผิดพลาด Pauli Z บนคิวบิตแฟล็ก (สีแดง) ด้วยความน่าจะเป็น pcx/15 และแพร่กระจายไปยังข้อผิดพลาด Z บน Q6 และข้อผิดพลาด X ก่อนการวัด a (วงกลมจุดไข่ปลา) การ deflagging ใช้ Z กับ Q6 เพื่อยกเลิกข้อผิดพลาดที่นั่น เพื่อให้ข้อผิดพลาดที่แพร่กระจายสุดท้ายเป็นเพียงการพลิกของการวัด a โปรดทราบว่าสำหรับการทดลองกับสถานะ |0⟩ และ |1⟩ เราต้องการแก้ไขเฉพาะข้อผิดพลาด X และใช้เฉพาะสเตบิไลเซอร์ Z เท่านั้น รูปที่ 1c สำหรับการทดลองกับ |+⟩ และ |-⟩ เราต้องการแก้ไขเฉพาะข้อผิดพลาด Z ด้วยกราฟในรูปที่ 1d ความน่าจะเป็นของเอดจ์จะแสดงสำหรับชุดทดลอง 2 รอบ |0⟩ และ |+⟩ ในตารางที่ 1 เราแสดงเฉพาะน้ำหนักเอดจ์สำหรับ r = 2 รอบของการดึงค่าซินโดรมเนื่องจากสิ่งนี้จะจับพฤติกรรมที่ขอบเขตเวลา t = 1 และ t = r + 1 รวมถึงพฤติกรรมสำหรับ 1 < t < r + 1 พฤติกรรมส่วนที่เหลือนี้จะซ้ำกันเมื่อเวลาผ่านไปสำหรับกรณี r > 2 ในการดำเนินการจับคู่ เราใช้ PyMatching [28] เพื่อดำเนินการจับคู่และถอดรหัส หลังจากตั้งค่ากราฟการถอดรหัสแล้ว การถอดรหัสชุดข้อมูลทั้งหมดที่ผ่านการคัดกรองการรั่วไหล (เช่น โดยทั่วไปอยู่ระหว่าง 100,000 ถึง 200,000 บิตสตริงที่ไม่ซ้ำกัน) จะใช้เวลาประมาณ 10 วินาที ซึ่งแทบไม่ขึ้นอยู่กับ r > 1 การดำเนินการความน่าจะเป็นสูงสุด มีวิธีการดำเนินการถอดรหัสแบบความน่าจะเป็นสูงสุด (MLD) อย่างน้อยสองวิธี ซึ่งเราเรียกว่าการดำเนินการแบบออฟไลน์และแบบออนไลน์ของตัวถอดรหัส แม้ว่าทั้งสองวิธีจะให้ผลลัพธ์เหมือนกัน แต่การดำเนินการอาจแตกต่างกันอย่างมากในด้านเวลาทำงาน ขึ้นอยู่กับการใช้งานเฉพาะ ในกรณีออฟไลน์ เราจะคำนวณและจัดเก็บการแจกแจงทั้งหมด Pr[β, γ] และสอบถามเพื่อกำหนดค่าแก้ไขสำหรับการทดลองแต่ละครั้ง การคำนวณใช้เวลา O(|E|^2|V| + 2^k) เนื่องจากเราต้องดำเนินการอัปเดตจากสมการที่ 6 กับการแจกแจงสำหรับทุกไฮเปอร์เอดจ์ใน E การกำหนดค่าแก้ไขโดยใช้สมการที่ 7 ใช้เวลา O(2^2k) ต่อการทดลอง อีกทางเลือกหนึ่ง เราสามารถละเว้นการคำนวณการแจกแจงทั้งหมด และคำนวณการแจกแจงที่เบาบาง (sparse distributions) ที่เฉพาะเจาะจงสำหรับแต่ละสตริงการสังเกต β* ในชุดข้อมูล MLD แบบออนไลน์บรรลุสิ่งนี้โดยการตัดการแจกแจงออกเมื่อทำการอัปเดต โดยเก็บเฉพาะรายการที่สอดคล้องกับ β* เราจินตนาการว่าได้รับข้อมูลทีละบิตของ β* สำหรับบิตที่ j การอัปเดตจะดำเนินการโดยใช้สมการที่ 6 สำหรับไฮเปอร์เอดจ์ทั้งหมดที่มีบิต j และยังไม่ได้ถูกรวมเข้ามา อันที่จริง การอัปเดตทั้งหมดเหล่านี้สำหรับบิตที่กำหนดสามารถรวมเข้าด้วยกันเป็นเมทริกซ์การเปลี่ยน (transition matrix) ที่คำนวณไว้ล่วงหน้า เนื่องจากจะไม่มีการอัปเดตเพิ่มเติมสำหรับบิต j อีกต่อไป เราสามารถตัดการแจกแจงออกได้โดยการเก็บเฉพาะรายการ Pr[β, γ] ที่ β สอดคล้องกับ β* เราสามารถดำเนินการอย่างรวดเร็วผ่านตัวอย่างของกระบวนการนี้สำหรับการทดลอง 0 รอบ, |0⟩ ที่นี่มีเพียง |V| = 2 เหตุการณ์ที่ไวต่อข้อผิดพลาด และ |E| = 3 ไฮเปอร์เอดจ์ การจัดระเบียบพารามิเตอร์ไฮเปอร์เอดจ์เช่น (βh, γh): ph เราเขียน โดยที่เราละเว้นบิต ZL ของ γh เนื่องจาก การแก้ไข ZL ไม่เกี่ยวข้องกับการทดลอง |0⟩ ซึ่งสอดคล้องกับหนึ่งรอบของกราฟในรูปที่ 1c และนิพจน์สำหรับ p1, p2, p3 คือสามแถวสุดท้ายของตารางที่ 1 เราจะใช้ p̄ = 1 − p ด้านล่าง สมมติว่าเราต้องการถอดรหัสการสังเกต β* = 01 เราเริ่มต้นด้วยการแจกแจงความน่าจะเป็น P0 = {(00, 0): 1} สัญกรณ์นี้หมายถึง Pr[β = 00, γ = 0] = 1 ค่าอื่นๆ ทั้งหมดของ β และ γ มีความน่าจะเป็นเป็นศูนย์และไม่ได้ถูกเขียนไว้ ดำเนินการอัปเดตตามไฮเปอร์เอดจ์ (10, 1) และ (11, 0) เพื่อให้ได้ ตอนนี้เราสามารถตัดการแจกแจงได้เนื่องจากเราเสร็จสิ้นการอัปเดตทั้งหมดที่เกี่ยวข้องกับเหตุการณ์แรก เนื่องจากบิตแรกของ β* คือ 0 ซึ่งทำให้เราเหลือ ตอนนี้การอัปเดตจะดำเนินการสำหรับไฮเปอร์เอดจ์อื่นๆ ที่เกี่ยวข้องกับเหตุการณ์ที่สอง ซึ่งในกรณีนี้คือ (01, 0) เท่านั้น ซึ่งในทำนองเดียวกันจะถูกตัดให้เหลือ เพื่อพิจารณาว่า β* ต้องการการแก้ไขเชิงตรรกะหรือไม่ ให้เปรียบเทียบ P(no error) กับ P(error) เนื่องจาก p_error เป็นอันดับสองของอัตราข้อผิดพลาดจากการทดลอง และ p_noerror เป็นอันดับแรก เราจึงอนุมานได้ว่ามีความเป็นไปได้มากกว่าที่จะไม่มีข้อผิดพลาดเชิงตรรกะเกิดขึ้น และใช้การแก้ไขเป็นศูนย์ สมมติว่าจำนวนรายการที่ไม่ใช่ศูนย์ในการแจกแจงความน่าจะเป็นหลังจากการตัดหลังบิตที่ j คือ Sj ในระหว่าง MLD แบบออนไลน์ จะมีขนาดสูงสุดชั่วคราวของการแจกแจงความน่าจะเป็น เช่น S_max เวลาทั้งหมดในการกำหนดค่าแก้ไขคือ O(S_max * |E|) ต่อการทดลอง โดยสมมติว่าจำนวนการอัปเดตไฮเปอร์เอดจ์คงที่ต่อบิต โปรดทราบว่า S_max ขึ้นอยู่กับไฮเปอร์กราฟการถอดรหัส และลำดับที่เหตุการณ์ที่ไวต่อข้อผิดพลาดถูกรวมเข้าด้วยกัน สามารถโต้แย้งได้ว่าสำหรับรหัส [[n, k]] การวัดค่าซินโดรมซ้ำๆ และเหตุการณ์ที่รวมเข้าด้วยกันตามลำดับเวลา, S_max = O(2^k) ขีดจำกัดล่างนั้นเป็นจริงเนื่องจากหลังจากการอัปเดตและการตัดรอบที่สมบูรณ์แล้ว บิตซินโดรมใดๆ ในรอบถัดไปของ n − k อาจถูกพลิกกลับเนื่องจากข้อผิดพลาดในการวัดค่าซินโดรม ขีดจำกัดบนเป็นผลมาจากไฮเปอร์เอดจ์ที่จำกัดให้มีเหตุการณ์จากสองรอบที่ติดต่อกันสูงสุด ตัวถอดรหัสแบบออนไลน์ยังสามารถใช้วิธี dynamic programming ได้ โดยจัดเก็บการแจกแจงความน่าจะเป็นที่คำนวณไว้บางส่วนจนถึง j ที่มีขนาดปานกลาง สิ่งนี้ช่วยประหยัดเวลาโดยการหลีกเลี่ยงการคำนวณซ้ำๆ เมื่อทำการถอดรหัสสังเกตการณ์ที่มีพรีฟิกซ์เหมือนกัน ตัวอย่างเช่น ในตัวอย่างข้างต้น เราสามารถจัดเก็บ P1 ได้ เนื่องจากทั้งการสังเกต β* = 00 และ 01 จะนำไปสู่การคำนวณ P1 ในการวิเคราะห์การทดลองสามรอบของเรา เราจัดเก็บการแจกแจงจนถึง j = 15 ในขณะที่สำหรับการทดลองสี่รอบ เราเก็บไว้จนถึง j = 21 ซึ่งส่วนใหญ่เป็นการพยายามปรับสมดุลการใช้เวลาและหน่วยความจำ เนื่องจาก MLD แบบออนไลน์ใช้เวลาเป็นเลขชี้กำลัง (ใน n, จำนวนคิวบิตทางกายภาพในรหัส) ต่อการทดลอง หาก |V| เล็กพอ MLD แบบออฟไลน์จะดีกว่า หาก |V| มีขนาดใหญ่แต่ n และ k มีขนาดเล็ก (อาจเป็นการทดลองรหัสขนาดเล็กที่ดำเนินการวัดค่าซินโดรมหลายรอบ) ตัวถอดรหัสแบบออนไลน์จะกลายเป็นทางเลือกเดียวที่เป็นไปได้ ในการทดลองที่นี่ MLD แบบออนไลน์จะดีกว่า MLD แบบออฟไลน์สำหรับสามรอบขึ้นไป สำหรับ r = 2 ทั้ง MLD แบบออฟไลน์หรือออนไลน์สามารถถอดรหัสชุดข้อมูลที่สมบูรณ์ได้ในเวลาประมาณ 90 วินาทีสำหรับสถานะ Z-eigenstates เชิงตรรกะ (ประมาณ 13,000 บิตสตริงที่ไม่ซ้ำกัน) และประมาณ 12 นาทีสำหรับสถานะ X-eigenstates เชิงตรรกะ (ประมาณ 21,000 บิตสตริงที่ไม่ซ้ำกัน) อย่างไรก็ตาม สำหรับ r = 10 MLD ออนไลน์อาจใช้เวลาถึง 3 สัปดาห์สำหรับชุดข้อมูลที่สมบูรณ์ (ประมาณ 130,000 บิตสตริงที่ไม่ซ้ำกัน) การคำนวณ MLD ออนไลน์ทั้งหมด r ≥ 3 ถูกรันบนเซิร์ฟเวอร์ Linux x86_64 ที่ใช้ร่วมกัน การใช้ฮาร์ดแวร์พิเศษ เช่น FPGA ไม่ใช่แนวทางที่เราได้สำรวจ อย่างไรก็ตาม เมื่อพิจารณาจากปัจจัย 2^k ในความซับซ้อนของเวลา เราไม่คาดว่า MLD ออนไลน์จะสามารถใช้งานได้กับอุปกรณ์ควอนตัมที่ใหญ่ขึ้น รายละเอียดการจำลอง เราได้ผลลัพธ์การจำลองทางทฤษฎีโดยใช้การจำลองสเตบิไลเซอร์ของ Qiskit software stack [36] เพื่อประเมินประสิทธิภาพของวงจรการแก้ไขข้อผิดพลาดควอนตัมบนระบบ IBM Quantum Falcon เราได้ทำการจำลองวงจรควอนตัมกับคิวบิตที่แมปไปยังอุปกรณ์ Falcon โดยใช้โมเดลข้อผิดพลาดที่ปรับแต่งเองเพื่อสะท้อนพฤติกรรมสัญญาณรบกวนของฮาร์ดแวร์จากการทดลอง ข้อผิดพลาดของวงจรในการจำลองของเราถูกจำลองเป็นข้อผิดพลาดแบบ depolarizing เพื่อให้สามารถจับผลกระทบของแหล่งข้อผิดพลาดต่างๆ ที่มีความแรงแตกต่างกันได้ โมเดลสัญญาณรบกวนถูกสร้างขึ้นตามตำแหน่งข้อผิดพลาดและช่องทางข้อผิดพลาดที่อธิบายไว้ในหัวข้อ “Decoding algorithms” โดยใช้ โมเดลข้อผิดพลาดแบบ depolarizing สำหรับการดำเนินการคิวบิตเดี่ยวและสองคิวบิตแต่ละครั้งในวงจรควอนตัม โดยมีอัตราข้อผิดพลาดที่ได้จากการ randomized benchmarking (RB) แบบพร้อมกัน โมเดลข้อผิดพลาดแบบ bit-flip สำหรับข้อผิดพลาดในการวัด การเริ่มต้น และการรีเซ็ต โมเดลสัญญาณรบกวนแบบ depolarizing สำหรับข้อผิดพลาดขณะไม่ได้ใช้งาน (idling error) โดยใช้โมเดลข้อผิดพลาดที่อธิบายข้างต้น เราได้กำหนดโมเดลข้อผิดพลาดแบบ depolarizing ที่สมจริง ซึ่งการจำลองจะดำเนินการด้วยพารามิเตอร์สัญญาณรบกวนที่ส่งออกโดยตรงจากโปรเซสเซอร์ IBM Quantum ที่ใช้สำหรับงานนี้ ibm_peekskill (ตารางที่ 2 และ 3) รวมถึง อัตราข้อผิดพลาดเฉพาะสำหรับการดำเนินการควอนตัมคิวบิตเดี่ยวและสองคิวบิตแต่ละครั้ง โดยมีพารามิเตอร์ช่องทางควอนตัมแบบ depolarizing ที่ได้จาก RB แบบพร้อมกันตามความสัมพันธ์ โดยที่ ϵ_gate, n, α_gate แทนถึงข้อผิดพลาดต่อเกต จำนวนคิวบิตในเกต และพารามิเตอร์ช่องทางควอนตัมแบบ depolarizing, การเริ่มต้น การวัด และการรีเซ็ตข้อผิดพลาดที่ได้ตามที่อธิบายไว้ในตารางที่ 2, ข้อผิดพลาดขณะไม่ได้ใช้งานที่มีความแรงสัญญาณรบกวนเป็นสัดส่วนกับขีดจำกัดความสอดคล้องกัน (coherence limit) ของเกต โดยคำนวณขีดจำกัดความสอดคล้องกันโดยใช้ T1, T2 และเวลาที่ไม่ได้ใช้งานของแต่ละคิวบิตในระหว่างการดำเนินการของการดำเนินการควอนตัมแต่ละครั้งในวงจร และระยะเวลาของเกตแต่ละอันจะตรงกับอุปกรณ์จริง (ตารางเวลาวงจรตรงกับข้อมูลจากการทดลอง) นอกจากนี้ เพื่อสาธิตประสิทธิภาพเฉลี่ยของวงจรในโมเดลข้อผิดพลาดแบบ depolarizing ที่ค่อนข้างสม่ำเสมอ เราได้กำหนดโมเดลข้อผิดพลาดแบบ depolarizing เฉลี่ย ซึ่งแทนที่จะใช้อัตราข้อผิดพลาดเฉพาะสำหรับเกตและคิวบิตต่างๆ ที่ระบุไว้ข้างต้น เราจะใช้อัตราข้อผิดพลาดเฉลี่ยทั่วทั้งอุปกรณ์เพื่อกำหนดช่องทางข้อผิดพลาดแบบ depolarizing โดยใช้อัลกอริทึมการถอดรหัสแบบ perfect matching เชิงวิเคราะห์ที่อธิบายไว้ข้างต้น พารามิเตอร์ pC = [0.0126, 0.000266, 0.0, 0.001, 0.002, 0.000266, 0.000266, 0.0, 0.00713, 0.0142, 0.0290] เรียงตามตำแหน่งข้อผิดพลาด Ci ที่กำหนดในหัวข้อ “Decoding algorithms” เราได้อัตราข้อผิดพลาดเชิงตรรกะต่อรอบที่จำลองได้สำหรับวงจรที่มีรอบการวัดค่าซินโดรมสูงสุด 10 รอบ เป็น 0.059 (0.038) สำหรับสถานะเชิงตรรกะ |0⟩ และ 0.152 (0.106) สำหรับสถานะเชิงตรรกะ |+⟩ ภายใต้อิทธิพลของโมเดลข้อผิดพลาดแบบ depolarizing ที่สมจริง (เฉลี่ย) ตามลำดับ เมื่อเปรียบเทียบกับข้อผิดพลาดเชิงตรรกะต่อรอบบนข้อมูลที่ผ่านการคัดกรองการรั่วไหล (ด้วยการถอดรหัสแบบ perfect matching เชิงวิเคราะห์) ดังแสดงในรูปที่ 2a ซึ่งเป็น 0.0409 สำหรับ |0⟩ และ 0.0882 สำหรับ |+⟩ อัตราข้อผิดพลาดเชิงตรรกะต่อรอบที่ใช้โมเดลข้อผิดพลาดแบบ depolarizing เฉลี่ยจะตรงกับข้อมูลได้ดีกว่าโมเดลที่สมจริง อย่างไรก็ตาม โมเดลเฉลี่ยยังคงประเมินค่าสถานะ |+⟩ สูงเกินไป แสดงว่าโมเดลที่ง่ายกว่านี้ไม่ได้จับข้อผิดพลาดในระบบได้อย่างสมบูรณ์ เราเชื่อว่าโมเดลที่สมจริงประเมินข้อผิดพลาดทั้งฐาน Z และ X สูงเกินไปส่วนหนึ่งเนื่องจากเกณฑ์ข้อผิดพลาด (ดูตารางที่ 2 และ 3) ที่ป้อนให้กับโมเดลนั้นไม่ได้คำนึงถึงการรั่วไหล ดังนั้นเกณฑ์ข้อผิดพลาดจึงน่าจะสูงขึ้นเนื่องจากข้อผิดพลาดการรั่วไหล เราเห็นว่าโมเดลที่สมจริงทำได้ดีกว่าในการทำนาย |+⟩ มากกว่า |0⟩ นี่เป็นหัวข้อที่ยังเปิดกว้าง สำหรับการจำลองและอาจรวมถึงการถอดรหัส เพื่อจับข้อมูลจากการทดลองได้ดียิ่งขึ้นนอกเหนือจากการรั่วไหล IBM_Peekskill และรายละเอียดการทดลอง ข้อมูลในส่วนนี้ใช้หมายเลขคิวบิต (QFN ตรงกันข้ามกับ QN ในรูปที่ 1) ที่นำเสนอในรูปที่ 4a ซึ่งตรงกับระบบ IBM Falcon มาตรฐาน สรุปในตารางที่ 2 เป็นเกณฑ์มาตรฐานคิวบิตเดี่ยวสำหรับ ibm_peekskill โดยเกตคิวบิตเดี่ยวสำหรับคิวบิตทั้งหมด (ไม่รวมเกต Z เสมือน) ใช้เวลาเท่ากันคือ 35.55ns ในขณะที่เลย์เอาต์ Falcon มี 27 คิวบิต สำหรับวงจร d=3 ที่นำเสนอในเอกสารนี้ เราจำเป็นต้องใช้เพียง 23 คิวบิตตามที่แสดงในรูปที่ 4a โดยไม่รวมคิวบิต QF0, QF6, QF20 และ QF26 การแปลงหมายเลขคิวบิต (QN) ในรูปที่ 1a เป็นหมายเลข IBM-Falcon มาตรฐาน (QFN) ZZ แบบคงที่ระหว่างคู่คิวบิตที่เชื่อมต่อทั้งหมดเทียบกับการดีจูนระหว่างคิวบิต ค่าเฉลี่ยของความไม่เป็นเชิงเส้นของคิวบิต (median qubit anharmonicity) ดูตารางที่ 2 สำหรับรายละเอียด คือ -345 MHz a b รูปขนาดเต็ม การเชื่อมต่อแบบเปิดตลอดเวลาระหว่างคู่คิวบิตที่เชื่อมต่อบน ibm_peekskill ยังส่งผลให้เกิด ZZ แบบคงที่ที่ไม่พึงประสงค์ ซึ่งแสดงในรูปที่ 4b เป็นฟังก์ชันของดีจูนระหว่างคิวบิต เพื่อลดผลกระทบเหล่านี้บางส่วน ลำดับ dynamical decoupling แบบ Xπ-Xπ แบบง่ายจะถูกเพิ่มเข้าไปในคิวบิตรหัสตลอดวงจร นอกจากนี้ โดยการแนะนำ randomized RB แบบพร้อมกันที่มีมิติผสม [37] เราสามารถจับผลกระทบข้างเคียงที่ไม่พึงประสงค์ของการเชื่อมต่อนี้ได้โดยการเปรียบเทียบข้อผิดพลาดเกตคิวบิตเดี่ยวและสองคิวบิตที่ได้จากการ RB มาตรฐานกับคิวบิตผู้ชม/เกตที่ไม่ได้ใช้งาน หรือกับเกตที่ทำงานพร้อมกันตามข้อกำหนดการจัดตารางเวลาของการตรวจสอบ Z และ X ดังนั้น ข้อผิดพลาดเกตพร้อมกันสำหรับเกตและคิวบิตที่ไม่ใช่ส่วนหนึ่งของการวัดเหล่านี้ (ไม่ได้ใช้งานตลอดเวลาในระหว่างการทดลองที่นำเสนอในข้อความหลัก) จึงไม่รวมอยู่ในลักษณะเฉพาะเพิ่มเติมนี้ (ในตารางเป็น NaN) ผลลัพธ์เหล่านี้แสดงในตารางที่ 2 และ 3 การปรับเกตคิวบิตสองตัวให้เหมาะสมได้รับการดำเนินการบน ibm_peekskill เพื่อให้แน่ใจว่าจะไม่มีการเสื่อมสภาพอย่างมีนัยสำคัญในข้อผิดพลาดเกตหรือการเพิ่มขึ้นของการรั่วไหลออกจากปริภูมิการคำนวณในการทดสอบแบบพร้อมกัน โดยใช้วิธีการเดียวกันที่นำเสนอใน [15] การดำเนินการรีเซ็ตตามผลการวัดก่อนหน้าจะใช้สำหรับการดำเนินการรีเซ็ตกลางวงจร ดังแสดงในรูปที่ 1b เวลาทั้งหมดของรอบการวัด + รีเซ็ตคือ 768ns และรวมถึงการวัดประมาณ 400ns การหน่วงเวลา cavity ring-down ที่ซ้อนทับกับความล่าช้าของเส้นทางควบคุมคลาสสิก และการใช้ Xπ ตามเงื่อนไข เพื่อความสอดคล้องกัน คิวบิตทั้งหมดจะถูกปรับเทียบให้ใช้ระยะเวลาพัลส์และความล่าช้าเท่ากัน โดยมีการปรับแอมพลิจูดพัลส์ทีละตัวเพื่อเพิ่มประสิทธิภาพ QND-ness ของการอ่านค่า เพื่อเพิ่มประสิทธิภาพการถอดรหัสแบบ perfect matching เชิงวิเคราะห์บนข้อมูลจากการทดลอง อัลกอริทึมการปรับให้เหมาะสมได้ถูกรันบนข้อมูลจากการทดลองของการวัดสเตบิไลเซอร์รอบเดียวของรหัส heavy hexagon ที่มีระยะห่างสามบนฮาร์ดแวร์เดียวกันเพื่อค้นหาชุดพารามิเตอร์ข้อผิดพลาดอินพุตที่ลดอัตราข้อผิดพลาดเชิงตรรกะของผลลัพธ์ตัวถอดรหัสให้เหลือน้อยที่สุด ในที่นี้ เราเลือกใช้อัลกอริทึม L-BFGS-B [38] เนื่องจากประสิทธิภาพของการปรับให้เหมาะสมและความสามารถในการทำงานกับข้อจำกัดเชิงเส้นอย่างง่าย การปรับให้เหมาะสมนี้ดำเนินการโดยเริ่มต้นด้วยพารามิเตอร์สัญญาณรบกวนทางกายภาพที่พบจากการปรับเทียบอุปกรณ์ โดยค่อยๆ อัปเดตพารามิเตอร์ในขณะที่ลดข้อผิดพลาดเชิงตรรกะโดยรวม มีจุดประสงค์เพื่อชดเชยการขาดความรู้ของตัวถอดรหัสเกี่ยวกับกระบวนการสัญญาณรบกวนที่สมจริง และส่งออกชุดพารามิเตอร์การถอดรหัสที่ให้ประสิทธิภาพตัวถอดรหัสที่ดีขึ้น การปรับให้เหมาะสมส่งผลให้ได้ชุดพารามิเตอร์ข้อผิดพลาดอินพุตต่อไปนี้สำหรับอัลกอริทึมการถอดรหัสแบบ perfect matching เชิงวิเคราะห์ pC = [0.01, 0.00028, 0.0, 0.001, 0.002, 0.00028, 0.00028, 0.0, 0.0005, 0.0, 0.00001] ตามตำแหน่งข้อผิดพลาด Ci ที่กำหนดในหัวข้อ “Decoding algorithms” เราใช้สมการต่อไปนี้เพื่อปรับค่าข้อผิดพลาดเชิงตรรกะที่รอบการวัดค่าซินโดรม r, โดยที่ A คือข้อผิดพลาด SPAM, p_leak คือความน่าจะเป็นในการรั่วไหล, และ ϵ คืออัตราข้อผิดพลาดเชิงตรรกะต่อรอบการวัดค่าซินโดรม (รูปที่ 2b, e, f) การรั่วไหลในระบบ ข้อผิดพลาดการรั่วไหลออกนอกปริภูมิการคำนวณ ซึ่งประกอบด้วยสถานะ |g⟩ และ |e⟩ ไปยัง |f⟩ หรือสถานะที่สูงกว่า ไม่สามารถแก้ไขได้ด้วยรหัสการแก้ไขข้อผิดพลาดควอนตัมของเรา ดังนั้นจึงเป็นภัยคุกคามร้ายแรงต่อการคำนวณแบบทนทานต่อความผิดพลาด สำหรับคิวบิตแบบตัวนำยิ่งยวดที่มีความถี่คงที่ การกำหนดค่าความถี่คิวบิตบางชุดอาจนำไปสู่การชนกันของความถี่ระหว่างการดำเนินการเกตแบบ cross-resonant [2] ตัวอย่างเช่น เมื่อความถี่คิวบิตเป้าหมายอยู่ใกล้กับความถี่การเปลี่ยน e → f ของคิวบิตควบคุม จะเกิดข้อผิดพลาดการรั่วไหลระหว่างการดำเนินการเกตสองคิวบิต อีกตัวอย่างหนึ่งคือการดำเนินการเกตสองคิวบิตพร้อมกันกับเกตคิวบิตเดี่ยวผู้ชม (spectator) ซึ่งความถี่คิวบิตผู้ชมร่วมกับความถี่คิวบิตเป้าหมายตรงกับความถี่การเปลี่ยน e → f ของคิวบิตควบคุม สิ่งนี้สามารถส่งผลให้เกิดข้อผิดพลาดการรั่วไหลซึ่งสามารถจำแนกลักษณะได้โดยการ randomized benchmarking ของเกตคิวบิตเดี่ยวและสองคิวบิตที่เกี่ยวข้อง [39] ข้อผิดพลาดการรั่วไหลอาจเกิดขึ้นระหว่างการวัดค่าด้วย [40] เมื่อเราเร่งความเร็วเวลาการวัดโดยการเพิ่มกำลังการวัด คิวบิตจะไวต่อการรั่วไหลมากขึ้น เราจำแนกลักษณะข้อผิดพลาดการรั่วไหลที่เกิดจากการวัดนี้โดยการวัดคิวบิตซ้ำๆ และดึงอัตราการรั่วไหล การทดลองอธิบายไว้ในรูปที่ 5a ซึ่งลำดับประกอบด้วย Xπ/2 ตามด้วยโทนการวัด Xπ/2 พัลส์จะแมป |0⟩ หรือ |1⟩ ไปยังเส้นศูนย์สูตรของ Bloch sphere ดังนั้น ลำดับจะสุ่มตัวอย่างการรั่วไหลจาก |0⟩ หรือ |1⟩ ในระหว่างการวัดค่าถัดไป ดังนั้นอัตราการรั่วไหลที่วัดได้จึงเป็นค่าเฉลี่ยของอัตราการรั่วไหลจากสถานะ |0⟩ และ |1⟩ ผลลัพธ์ที่ได้จากลำดับในรูปที่ 5a จะถูกจัดหมวดหมู่ตามข้อมูลการสอบเทียบที่ได้จากการเตรียมสถานะ |0⟩, |1⟩, และ |2⟩ โดยใช้การกระจายเฉลี่ยที่ใกล้เคียงที่สุดสำหรับแต่ละผลลัพธ์ และจากนั้นใช้การแก้ไขข้อผิดพลาดในการอ่านค่าโดยการจำกัดรูปแบบที่อธิบายไว้ใน [41] สำหรับการอ่านค่าหลายคิวบิตไปยังปริภูมิสถานะสามสถานะของคิวบิตเดี่ยวของเรา การแก้ไขข้อผิดพลาดในการอ่านค่าคิวบิตเดี่ยวนี้จะถูกนำไปใช้กับชุดการวัดที่ได้สำหรับแต่ละรอบของลำดับพัลส์ ลำดับการวัดจะถูกทำซ้ำ m = 70 ครั้ง และเราจะหาค่าเฉลี่ยของ 10,000 ช็อตสำหรับแต่ละ m เพื่อคำนวณค่าเฉลี่ยความน่าจะเป็นที่คิวบิตจะถูกจัดกลุ่มในสถานะ |2⟩ รูปที่ 5b แสดงความน่าจะเป็นการรั่วไหล, P_leak, โดยที่คิวบิตรั่วไหลไปยังสถานะ |2⟩ ต่อการวัด (ดูตารางที่ 2 สำหรับรายละเอียดเพิ่มเติม) ในที่สุด จะถึงสภาวะคงตัวของประชากรในสถานะ |2⟩ ซึ่งกำหนดโดยอัตราการรั่วไหลและการซึมผ่าน (seepage rate) เราดึงอัตราการรั่วไหลและอัตราการซึมผ่านโดยใช้สมการ โดยที่อัต