
636 lecturas
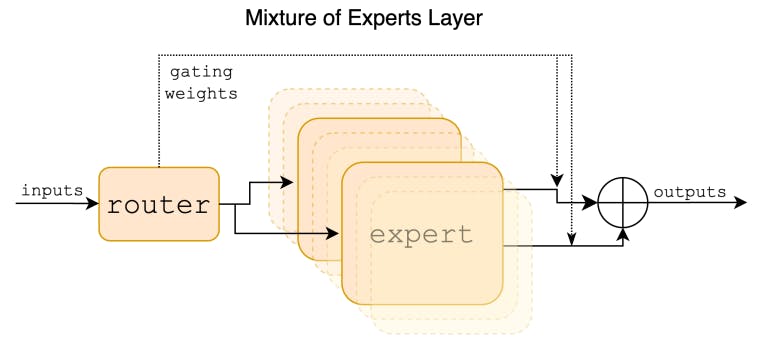
Mixtral: un modelo lingüístico multilingüe adestrado cun tamaño de contexto de 32k tokens
by byWritings, Papers and Blogs on Text Models@textmodels
byWritings, Papers and Blogs on Text Models@textmodels
We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
2024/10/18


















We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
Story's Credibility


We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
Story's Credibility
About Author

We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
COMENTARIOS










