
636 čítania
Mixtral — viacjazyčný jazykový model trénovaný s veľkosťou kontextu 32 000 tokenov
by byWritings, Papers and Blogs on Text Models@textmodels
byWritings, Papers and Blogs on Text Models@textmodels
We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
2024/10/18


















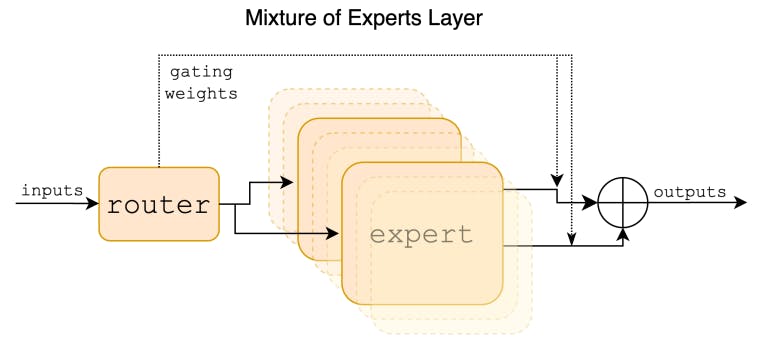
We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
Story's Credibility


We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
Story's Credibility
About Author

We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
KOMENTÁRE

ZAVISTE ŠTÍTKY
TENTO ČLÁNOK BOL PREDSTAVENÝ V



Related Stories









When Blood Told
Jan 20, 1970
THE CRAB-SPIDER
Jan 20, 1970