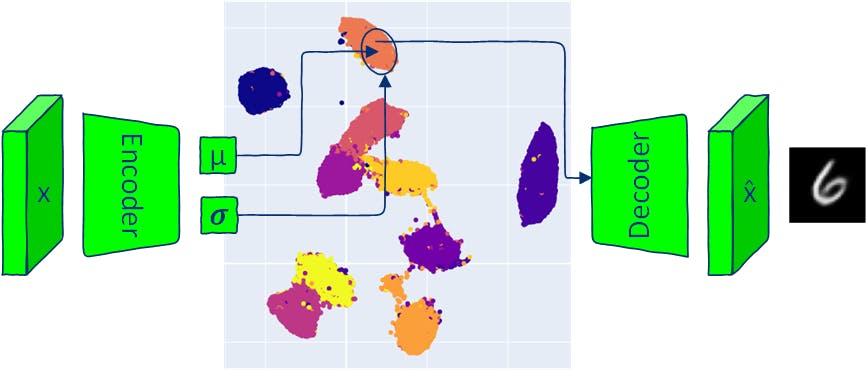
Tout comme les auto-encodeurs traditionnels, l'architecture VAE comporte deux parties : un encodeur et un décodeur. Les modèles AE traditionnels mappent les entrées dans un vecteur d'espace latent et reconstruisent la sortie de ce vecteur. VAE mappe les entrées dans une distribution normale multivariée (l'encodeur génère la moyenne et la variance de chaque dimension latente). Puisque le codeur VAE produit une distribution, les nouvelles données peuvent être générées en échantillonnant à partir de cette distribution et en transmettant le vecteur latent échantillonné au décodeur. L'échantillonnage à partir de la distribution produite pour générer des images de sortie signifie que la VAE permet la génération de nouvelles données similaires, mais identiques aux données d'entrée. Cet article explore les composants de l'architecture VAE et propose plusieurs façons de générer de nouvelles images (échantillonnage) avec des modèles VAE. Tout le code est disponible dans . Google Colab 1 Mise en œuvre du modèle VAE Les auto-encodeurs et les auto-encodeurs variationnels comportent tous deux deux parties : l'encodeur et le décodeur. Le réseau neuronal du codeur d'AE apprend à mapper chaque image en un seul vecteur dans l'espace latent et le décodeur apprend à reconstruire l'image originale à partir du vecteur latent codé. Le réseau neuronal codeur de VAE génère des paramètres qui définissent une distribution de probabilité pour chaque dimension de l'espace latent (distribution multivariée). Pour chaque entrée, l'encodeur produit une moyenne et une variance pour chaque dimension de l'espace latent. La moyenne et la variance de sortie sont utilisées pour définir une distribution gaussienne multivariée. Le réseau neuronal du décodeur est le même que dans les modèles AE. 1.1 Pertes VAE L'objectif de la formation d'un modèle VAE est de maximiser la probabilité de générer des images réelles à partir des vecteurs latents fournis. Lors de la formation, le modèle VAE minimise deux pertes : - la différence entre les images d'entrée et la sortie du décodeur. perte de reconstruction (divergence KL, une distance statistique entre deux distributions de probabilité) - la distance entre la distribution de probabilité de la sortie du codeur et une distribution antérieure (une distribution normale standard), aidant à régulariser l'espace latent. Perte de divergence Kullback – Leibler 1.2 Perte de reconstruction Les pertes de reconstruction courantes sont l'entropie croisée binaire (BCE) et l'erreur quadratique moyenne (MSE). Dans cet article, j'utiliserai l'ensemble de données MNIST pour la démo. Les images MNIST n'ont qu'un seul canal et les pixels prennent des valeurs comprises entre 0 et 1. Dans ce cas, la perte BCE peut être utilisée comme perte de reconstruction pour traiter les pixels des images MNIST comme une variable aléatoire binaire qui suit la distribution de Bernoulli. reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 Divergence Kullback-Leibler Comme mentionné ci-dessus, la divergence KL évalue la différence entre deux distributions. Notez qu'il n'a pas de propriété symétrique d'une distance : KL(P‖Q)!=KL(Q‖P). Les deux distributions à comparer sont : l'espace latent de la sortie du codeur étant donné les images d'entrée x : q(z|x) espace latent antérieur qui est supposé être une distribution normale avec une moyenne de zéro et un écart type de un dans chaque dimension de l'espace latent . p(z) N(0, ) I Une telle hypothèse simplifie le calcul de la divergence KL et encourage l'espace latent à suivre une distribution connue et gérable. from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 Encodeur class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 Décodeur class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 Modèle VAE Pour rétro-propager à travers un échantillon aléatoire, vous devez déplacer les paramètres de l'échantillon aléatoire ( et 𝝈) en dehors de la fonction pour permettre le calcul du gradient à travers les paramètres. Cette étape est également appelée « astuce de reparamétrage ». μ Dans PyTorch, vous pouvez créer une distribution avec la sortie de l'encodeur et 𝝈 et en échantillonner avec la méthode qui implémente l'astuce de reparamétrage : c'est la même chose que normale μ rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 Former une VAE Chargez les données de train et de test MNIST. transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) Créez une boucle de formation qui suit les étapes de formation VAE visualisées dans la figure ci-dessus. def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 Visualiser l'espace latent def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 Echantillonnage avec VAE L'échantillonnage à partir d'un auto-encodeur variationnel (VAE) permet la génération de nouvelles données similaires à celles observées lors de la formation et constitue un aspect unique qui sépare le VAE de l'architecture AE traditionnelle. Il existe plusieurs manières de prélever à partir d’une VAE : échantillonnage à partir de la distribution a posteriori étant donné une entrée fournie. échantillonnage a posteriori : échantillonnage à partir de l'espace latent en supposant une distribution multivariée normale standard. Ceci est possible grâce à l'hypothèse (utilisée lors de la formation VAE) que les variables latentes sont normalement distribuées. Cette méthode ne permet pas de générer des données avec des propriétés spécifiques (par exemple, générer des données à partir d'une classe spécifique). échantillonnage préalable : : l'interpolation entre deux points de l'espace latent peut révéler comment les changements dans la variable de l'espace latent correspondent aux changements dans les données générées. interpolation : parcours des dimensions latentes de la variance de l'espace latent VAE des données dépend de chaque dimension. Le parcours est effectué en fixant toutes les dimensions du vecteur latent sauf une dimension choisie et en faisant varier les valeurs de la dimension choisie dans sa plage. Certaines dimensions de l'espace latent peuvent correspondre à des attributs spécifiques des données (la VAE ne dispose pas de mécanismes spécifiques pour forcer ce comportement mais cela peut arriver). parcours des dimensions latentes Par exemple, une dimension dans l’espace latent peut contrôler l’expression émotionnelle d’un visage ou l’orientation d’un objet. Chaque méthode d'échantillonnage offre une manière différente d'explorer et de comprendre les propriétés des données capturées par l'espace latent de VAE. 2.1 Échantillonnage postérieur (à partir d'une image d'entrée donnée) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) L'échantillonnage a posteriori permet de générer des échantillons de données réalistes mais avec une faible variabilité : les données de sortie sont similaires aux données d'entrée. 2.2 Échantillonnage préalable (à partir d'un vecteur d'espace latent aléatoire) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) Un échantillonnage préalable avec N(0, ) ne génère pas toujours des données plausibles mais présente une grande variabilité. I 2.3 Échantillonnage à partir des centres de classe Les codages moyens de chaque classe peuvent être accumulés à partir de l'ensemble de données et être ensuite utilisés pour une génération contrôlée (conditionnelle). def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') L'échantillonnage à partir d'une distribution normale de classe moyenne μ garantit la génération de nouvelles données de la même classe. 2.4 Interpolation def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 Interpolation entre deux vecteurs latents aléatoires start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 Interpolation entre deux centres de classe for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 Traversée de l'espace latent Chaque dimension du vecteur latent représente une distribution normale ; la plage de valeurs de la dimension est contrôlée par la moyenne et la variance de la dimension. Un moyen simple de parcourir la plage de valeurs consisterait à utiliser les CDF inverses (fonctions de distribution cumulative) de la distribution normale. ICDF prend une valeur comprise entre 0 et 1 (représentant la probabilité) et renvoie une valeur de la distribution. Pour une probabilité donnée, l'ICDF génère une valeur telle que la probabilité qu'une variable aléatoire soit <= est égale à la probabilité donnée ? » p p_icdf p_icdf p Si vous avez une distribution normale, icdf(0.5) devrait renvoyer la moyenne de la distribution. icdf(0.95) devrait renvoyer une valeur supérieure à 95 % des données de la distribution. 2.5.1 Traversée de l'espace latent unidimensionnel def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') Le déplacement d'une seule dimension peut entraîner une modification du style des chiffres ou de l'orientation des chiffres de contrôle. 2.5.3 Traversée de l'espace latent à deux dimensions def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') Traverser plusieurs dimensions à la fois offre un moyen contrôlable de générer des données avec une grande variabilité. Bonus 2.6 - Collecteur 2D de chiffres de l'espace latent Si un modèle VAE est entraîné avec il est possible d'afficher une variété 2D de chiffres à partir de son espace latent. Pour ce faire, j'utiliserai avec et . = 2, z_dim la fonction traverse_two_latent_dimensions =0 dim_1 =2 dim_2 vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')