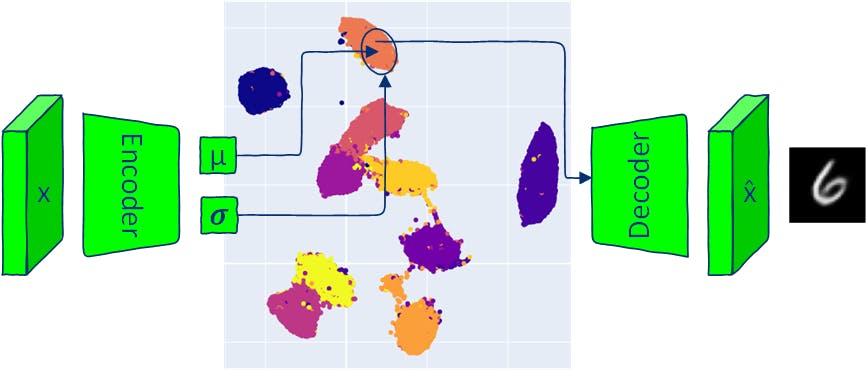
ঐতিহ্যগত অটোএনকোডারের মতোই, VAE আর্কিটেকচারের দুটি অংশ রয়েছে: একটি এনকোডার এবং একটি ডিকোডার। প্রথাগত AE মডেলগুলি একটি সুপ্ত-স্পেস ভেক্টরে ইনপুট ম্যাপ করে এবং এই ভেক্টর থেকে আউটপুট পুনর্গঠন করে। VAE ম্যাপ ইনপুটগুলিকে একটি মাল্টিভেরিয়েট সাধারন বন্টন (এনকোডার প্রতিটি সুপ্ত মাত্রার গড় এবং প্রকরণ আউটপুট করে)। যেহেতু VAE এনকোডার একটি ডিস্ট্রিবিউশন তৈরি করে, তাই এই ডিস্ট্রিবিউশন থেকে স্যাম্পলিং করে এবং ডিকোডারে নমুনাযুক্ত সুপ্ত ভেক্টর পাস করে নতুন ডেটা তৈরি করা যেতে পারে। আউটপুট ইমেজ তৈরি করতে উত্পাদিত বিতরণ থেকে নমুনা নেওয়ার অর্থ হল VAE অভিনব ডেটা তৈরি করার অনুমতি দেয় যা অনুরূপ, কিন্তু ইনপুট ডেটার সাথে অভিন্ন। এই নিবন্ধটি VAE আর্কিটেকচারের উপাদানগুলি অন্বেষণ করে এবং VAE মডেলগুলির সাথে নতুন চিত্র (নমুনা) তৈরি করার বিভিন্ন উপায় সরবরাহ করে। সমস্ত কোড এ উপলব্ধ। Google Colab- 1 VAE মডেল বাস্তবায়ন অটোএনকোডার এবং ভেরিয়েশনাল অটোএনকোডার উভয়েরই দুটি অংশ রয়েছে: এনকোডার এবং ডিকোডার। AE-এর এনকোডার নিউরাল নেটওয়ার্ক প্রতিটি ছবিকে সুপ্ত স্থানের একটি একক ভেক্টরে ম্যাপ করতে শেখে এবং ডিকোডার এনকোড করা সুপ্ত ভেক্টর থেকে মূল চিত্রটি পুনর্গঠন করতে শেখে। VAE আউটপুট প্যারামিটারগুলির এনকোডার নিউরাল নেটওয়ার্ক যা সুপ্ত স্থানের প্রতিটি মাত্রার (মাল্টিভেরিয়েট ডিস্ট্রিবিউশন) জন্য একটি সম্ভাব্যতা বন্টন সংজ্ঞায়িত করে। প্রতিটি ইনপুটের জন্য, এনকোডার সুপ্ত স্থানের প্রতিটি মাত্রার জন্য একটি গড় এবং একটি ভিন্নতা তৈরি করে। আউটপুট গড় এবং প্রকরণ একটি মাল্টিভেরিয়েট গাউসিয়ান ডিস্ট্রিবিউশন সংজ্ঞায়িত করতে ব্যবহৃত হয়। ডিকোডার নিউরাল নেটওয়ার্ক AE মডেলের মতোই। 1.1 VAE লোকসান একটি VAE মডেলকে প্রশিক্ষণের লক্ষ্য হল প্রদত্ত সুপ্ত ভেক্টর থেকে বাস্তব চিত্র তৈরি করার সম্ভাবনাকে সর্বাধিক করা। প্রশিক্ষণের সময়, VAE মডেল দুটি ক্ষতি কমিয়ে দেয়: - ইনপুট চিত্র এবং ডিকোডারের আউটপুটের মধ্যে পার্থক্য। পুনর্গঠন ক্ষতি (KL ডাইভারজেন্স একটি পরিসংখ্যান দূরত্ব দুটি সম্ভাব্যতা বিতরণের মধ্যে) - এনকোডারের আউটপুটের সম্ভাব্যতা বন্টন এবং একটি পূর্ববর্তী বন্টন (একটি আদর্শ স্বাভাবিক বন্টন), সুপ্ত স্থানকে নিয়মিত করতে সাহায্য করে। Kullback–Leibler ডাইভারজেন্স লস 1.2 পুনর্গঠনের ক্ষতি সাধারণ পুনর্গঠনের ক্ষতি হল বাইনারি ক্রস-এনট্রপি (BCE) এবং গড় বর্গক্ষেত্র ত্রুটি (MSE)। এই নিবন্ধে, আমি ডেমোর জন্য MNIST ডেটাসেট ব্যবহার করব। MNIST চিত্রগুলির একটি মাত্র চ্যানেল আছে এবং পিক্সেলগুলি 0 এবং 1 এর মধ্যে মান নেয়৷ এই ক্ষেত্রে, BCE ক্ষতি পুনর্গঠন ক্ষতি হিসাবে ব্যবহার করা যেতে পারে MNIST চিত্রগুলির পিক্সেলগুলিকে বাইনারি র্যান্ডম ভেরিয়েবল হিসাবে বিবেচনা করতে যা Bernoulli বিতরণকে অনুসরণ করে। reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 Kullback-Leibler ডাইভারজেন্স উপরে উল্লিখিত হিসাবে - KL ডাইভারজেন্স দুটি বিতরণের মধ্যে পার্থক্য মূল্যায়ন করে। মনে রাখবেন যে এটিতে দূরত্বের একটি প্রতিসম বৈশিষ্ট্য নেই: KL(P‖Q)!=KL(Q‖P)। যে দুটি বিতরণ তুলনা করা দরকার তা হল: এনকোডার আউটপুটের সুপ্ত স্থান প্রদত্ত ইনপুট চিত্র x: q(z|x) প্রচ্ছন্ন স্থান পূর্বে যা শূন্যের গড় এবং প্রতিটি সুপ্ত স্থানের মাত্রা এর একটির একটি আদর্শ বিচ্যুতি সহ একটি স্বাভাবিক বন্টন বলে ধরে নেওয়া হয়। p(z) N(0, ) I এই ধরনের অনুমান KL ডাইভারজেন্স গণনাকে সরল করে এবং সুপ্ত স্থানকে একটি পরিচিত, পরিচালনাযোগ্য বন্টন অনুসরণ করতে উৎসাহিত করে। from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 এনকোডার class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 ডিকোডার class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 VAE মডেল একটি এলোমেলো নমুনার মাধ্যমে ব্যাক-প্রচার করতে আপনাকে র্যান্ডম নমুনার ( এবং 𝝈) প্যারামিটারগুলিকে ফাংশনের বাইরে সরাতে হবে যাতে প্যারামিটারগুলির মাধ্যমে গ্রেডিয়েন্ট গণনা করা যায়। এই ধাপটিকে "পুনরায় পরিমাপকরণ কৌশল"ও বলা হয়। μ PyTorch-এ, আপনি এনকোডারের আউটপুট এবং 𝝈 দিয়ে একটি বন্টন তৈরি করতে পারেন এবং এটি থেকে পদ্ধতিতে নমুনা তৈরি করতে পারেন যা পুনরায় প্যারামিটারাইজেশন কৌশল প্রয়োগ করে: এটি μ সাধারণ rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 একটি VAE প্রশিক্ষণ MNIST ট্রেন লোড করুন এবং ডেটা পরীক্ষা করুন। transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) একটি প্রশিক্ষণ লুপ তৈরি করুন যা উপরের চিত্রে VAE প্রশিক্ষণের ধাপগুলি অনুসরণ করে। def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 সুপ্ত স্থান কল্পনা করুন def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 VAE সঙ্গে নমুনা একটি ভেরিয়েশনাল অটোএনকোডার (VAE) থেকে স্যাম্পলিং নতুন ডেটা তৈরি করতে সক্ষম করে যা প্রশিক্ষণের সময় দেখা একটির মতো এবং এটি একটি অনন্য দিক যা VAE কে ঐতিহ্যগত AE আর্কিটেকচার থেকে আলাদা করে। VAE থেকে নমুনা নেওয়ার বিভিন্ন উপায় রয়েছে: একটি প্রদত্ত ইনপুট দেওয়া পোস্টেরিয়র ডিস্ট্রিবিউশন থেকে নমুনা। পোস্টেরিয়র স্যাম্পলিং: একটি প্রমিত সাধারণ মাল্টিভেরিয়েট ডিস্ট্রিবিউশন ধরে নিয়ে সুপ্ত স্থান থেকে নমুনা নেওয়া। এটি সম্ভব হয়েছে অনুমানের কারণে (VAE প্রশিক্ষণের সময় ব্যবহৃত) যে সুপ্ত ভেরিয়েবলগুলি সাধারণত বিতরণ করা হয়। এই পদ্ধতিটি নির্দিষ্ট বৈশিষ্ট্য সহ ডেটা তৈরির অনুমতি দেয় না (উদাহরণস্বরূপ, একটি নির্দিষ্ট শ্রেণি থেকে ডেটা তৈরি করা)। পূর্বের স্যাম্পলিং: : সুপ্ত স্থানের দুটি বিন্দুর মধ্যে ইন্টারপোলেশন প্রকাশ করতে পারে কিভাবে সুপ্ত স্থান পরিবর্তনশীলের পরিবর্তনগুলি উৎপন্ন ডেটার পরিবর্তনের সাথে মিলে যায়। ইন্টারপোলেশন : ডেটার VAE সুপ্ত স্থানের বৈচিত্র্যের সুপ্ত মাত্রা অতিক্রম করা প্রতিটি মাত্রার উপর নির্ভর করে। একটি নির্বাচিত মাত্রা এবং তার পরিসরে নির্বাচিত মাত্রার বিভিন্ন মান ছাড়া সুপ্ত ভেক্টরের সমস্ত মাত্রা ঠিক করে ট্রাভার্সাল করা হয়। সুপ্ত স্থানের কিছু মাত্রা ডেটার নির্দিষ্ট বৈশিষ্ট্যের সাথে মিলিত হতে পারে (VAE-এর সেই আচরণকে বাধ্য করার জন্য নির্দিষ্ট প্রক্রিয়া নেই তবে এটি ঘটতে পারে)। সুপ্ত মাত্রার ট্রাভার্সাল উদাহরণস্বরূপ, সুপ্ত স্থানের একটি মাত্রা একটি মুখের মানসিক অভিব্যক্তি বা একটি বস্তুর অভিযোজন নিয়ন্ত্রণ করতে পারে। প্রতিটি নমুনা পদ্ধতি VAE-এর সুপ্ত স্থান দ্বারা ক্যাপচার করা ডেটা বৈশিষ্ট্যগুলি অন্বেষণ এবং বোঝার একটি ভিন্ন উপায় প্রদান করে। 2.1 পোস্টেরিয়র স্যাম্পলিং (একটি প্রদত্ত ইনপুট ইমেজ থেকে) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) পোস্টেরিয়র স্যাম্পলিং বাস্তবসম্মত ডেটা নমুনা তৈরি করতে দেয় কিন্তু কম পরিবর্তনশীলতার সাথে: আউটপুট ডেটা ইনপুট ডেটার অনুরূপ। 2.2 পূর্বের নমুনা (একটি এলোমেলো সুপ্ত স্থান ভেক্টর থেকে) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) N(0, ) এর সাথে পূর্বের নমুনা সর্বদা বিশ্বাসযোগ্য ডেটা তৈরি করে না তবে উচ্চ পরিবর্তনশীলতা রয়েছে। I 2.3 ক্লাস সেন্টার থেকে স্যাম্পলিং প্রতিটি শ্রেণীর গড় এনকোডিংগুলি সমগ্র ডেটাসেট থেকে সংগ্রহ করা যেতে পারে এবং পরে একটি নিয়ন্ত্রিত (শর্তাধীন প্রজন্ম) জন্য ব্যবহার করা যেতে পারে। def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') গড় ক্লাস μ সহ একটি সাধারণ বিতরণ থেকে নমুনা একই শ্রেণি থেকে নতুন ডেটা তৈরির গ্যারান্টি দেয়। 2.4 ইন্টারপোলেশন def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 দুটি এলোমেলো সুপ্ত ভেক্টরের মধ্যে ইন্টারপোলেশন start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 দুটি শ্রেণী কেন্দ্রের মধ্যে ইন্টারপোলেশন for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 সুপ্ত স্পেস ট্রাভার্সাল সুপ্ত ভেক্টরের প্রতিটি মাত্রা একটি স্বাভাবিক বন্টন প্রতিনিধিত্ব করে; মাত্রার মানগুলির পরিসর মাত্রার গড় এবং প্রকরণ দ্বারা নিয়ন্ত্রিত হয়। মানগুলির পরিসর অতিক্রম করার একটি সহজ উপায় হল স্বাভাবিক বন্টনের বিপরীত CDF (ক্রমবর্ধমান বন্টন ফাংশন) ব্যবহার করা। ICDF 0 এবং 1 এর মধ্যে একটি মান নেয় (সম্ভাব্যতা উপস্থাপন করে) এবং বিতরণ থেকে একটি মান প্রদান করে। একটি প্রদত্ত সম্ভাব্যতার জন্য একটি মান আউটপুট করে যাতে একটি র্যান্ডম ভেরিয়েবল হওয়ার সম্ভাবনা <= প্রদত্ত সমান হয়? ICDF p_icdf p_icdf সম্ভাব্যতার যদি আপনার একটি স্বাভাবিক বিতরণ থাকে, তাহলে icdf(0.5) বিতরণের গড় ফেরত দেবে। icdf(0.95) ডিস্ট্রিবিউশন থেকে ডাটার 95% এর চেয়ে বড় একটি মান ফেরত দেবে। 2.5.1 একক মাত্রা সুপ্ত স্পেস ট্রাভার্সাল def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') একটি একক মাত্রা অতিক্রম করার ফলে অঙ্ক শৈলী বা নিয়ন্ত্রণ অঙ্ক অভিযোজন পরিবর্তন হতে পারে। 2.5.3 দুটি মাত্রা সুপ্ত স্পেস ট্রাভার্সাল def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') একসাথে একাধিক মাত্রা অতিক্রম করা উচ্চ পরিবর্তনশীলতার সাথে ডেটা জেনারেট করার একটি নিয়ন্ত্রণযোগ্য উপায় প্রদান করে। 2.6 বোনাস - সুপ্ত স্থান থেকে সংখ্যার 2D বহুগুণ যদি একটি VAE মডেলকে তাহলে এর সুপ্ত স্থান থেকে সংখ্যার 2D বহুগুণ প্রদর্শন করা সম্ভব। এটি করার জন্য, আমি এবং সহ ফাংশন ব্যবহার করব। =2 দিয়ে প্রশিক্ষিত করা হয়, z_dim =0 dim_1 =2 dim_2 traverse_two_latent_dimensions vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')