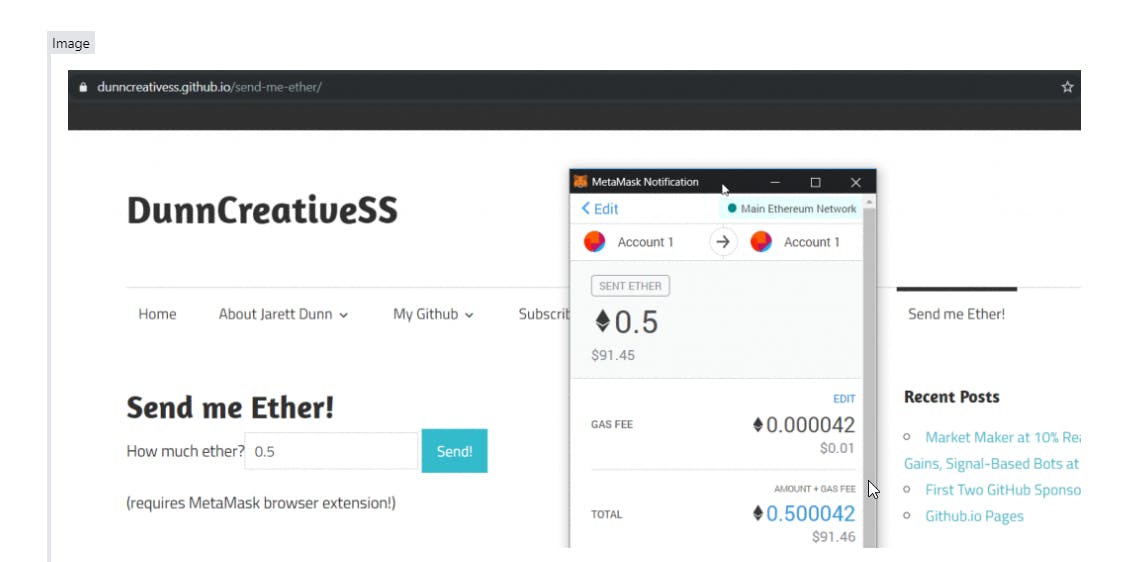
```html Outkeuses: Mayank Mishra⋆, IBM Matt Stallone⋆, IBM Gaoyuan Zhang⋆, IBM Yikang Shen, IBM Aditya Prasad, IBM Adriana Meza Soria, IBM Michele Merler, IBM Parameswaran Selvam, IBM Saptha Surendran, IBM Shivdeep Singh, IBM Manish Sethi, IBM Xuan-Hong Dang, IBM Pengyuan Li, IBM Kun-Lung Wu, IBM Syed Zawad, IBM Andrew Coleman, IBM Matthew White, IBM Mark Lewis, IBM Raju Pavuluri, IBM Yan Koyfman, IBM Boris Lublinsky, IBM Maximilien de Bayser, IBM Ibrahim Abdelaziz, IBM Kinjal Basu, IBM Mayank Agarwal, IBM Yi Zhou, IBM Chris Johnson, IBM Aanchal Goyal, IBM Hima Patel, IBM Yousaf Shah, IBM Petros Zerfos, IBM Heiko Ludwig, IBM Asim Munawar, IBM Maxwell Crouse, IBM Pavan Kapanipathi, IBM Shweta Salaria, IBM Bob Calio, IBM Sophia Wen, IBM Seetharami Seelam, IBM Brian Belgodere, IBM Carlos Fonseca, IBM Amith Singhee, IBM Nirmit Desai, IBM David D. Cox, IBM Ruchir Puri†, IBM Rameswar Panda†, IBM Opsomming Groot Taalmodelle (LLMs) wat op kode opgelei is, is besig om die sagtewareontwikkelingsproses te verander. Al hoe meer word kodegenererende LLMs geïntegreer in sagtewareontwikkelingsomgewings om die produktiwiteit van menslike programmeerders te verbeter, en LLM-gebaseerde agente begin belowend wees vir die selfstandige hantering van komplekse take. Om die volle potensiaal van kodegenererende LLMs te verwesenlik, is 'n wye reeks vermoëns nodig, insluitend kodegenerering, foutregstelling, kodeverklaring en -dokumentasie, bewaarplekke-onderhoud, en meer. In hierdie werk stel ons die Granite-reeks dekoder-alleen kodemodelle bekend vir kodegenererende take, opgelei met kode geskryf in 116 programmeertale. Die Granite Code-modellefamilie bestaan uit modelle wat wissel in grootte van 3 tot 34 miljard parameters, geskik vir toepassings wat wissel van komplekse toepassingmoderniseringstake tot toestelle met geheuebeperkings. Evaluering op 'n omvattende stel take demonstreer dat Granite Code-modelle konsekwent toonaangewende prestasie onder beskikbare oopbron kodegenererende LLMs bereik. Die Granite Code-model familie is geoptimaliseer vir ondernemingsagteware-ontwikkelingswerkvloeie en presteer goed oor 'n reeks koderingstake (bv. kodegenerering, -regstelling en -verklaring), wat dit 'n veelsydige "all-round" kodemodel maak. Ons stel al ons Granite Code-modelle vry onder 'n Apache 2.0-lisensie vir beide navorsings- en kommersiële gebruik. https://github.com/ibm-granite/granite-code-models 1 Inleiding Oor die afgelope paar dekades is sagteware in elke aspek van ons samelewing verweef. Soos die vraag na sagtewareontwikkeling toeneem, is dit van kritieke belang om die produktiwiteit van sagtewareontwikkeling te verhoog, en LLMs bied 'nbelowende pad vir die aanvulling van menslike programmeerders. Prominente ondernemingsgevalle vir LLMs in sagtewareontwikkelingsproduktiwiteit sluit in kodegenerering, kodeverklaring, kode regstelling, eenheidstoets- en dokumentasiegenerering, toepassingmodernisering, kwesbaarheidsdeteksie, kodetranslasie, en meer. Die afgelope paar jaar het vinnige vordering gesien in LLM se vermoë om kode te genereer en te manipuleer, en 'n reeks modelle met indrukwekkende koderingvermoëns is vandag beskikbaar. Modelle wissel in grootte van enkele miljarde parameters (bv. Llama-7B (Touvron et al., 2023), Gemma-7B (Gemma-Team et al., 2024), ens.) tot honderde miljarde: DBRX (Databricks), Arctic (Snowflake), Grok, Mixtral 8x22B (MistralAI), Command R+ (Cohere), en wissel in die algemeenheid van beoogde gebruik, met sommige modelle wat daarop gemik is om 'n reeks gebruike buite kode te dek, terwyl ander primêr op kodering-verwante take fokus (bv. StarCoder (Li et al., 2023a; Lozhkov et al., 2024), CodeGen (Nijkamp et al., 2023), CodeLlama (Rozie`re et al., 2023), en CodeGemma (CodeGemma Team et al., 2024)). Daar bly egter belangrike leemtes in die huidige veld van LLMs vir kode, veral in die konteks van ondernemingsagteware-ontwikkeling. Eerstens, hoewel baie groot, generalistiese LLMs uitstekende koderingprestasies kan behaal, maak hul grootte dit duur om te ontplooi. Kleiner kodgerigte modelle ( , ; , ; , ; , ; , ) kan uitstekende kodegenerasieprestasie in 'n kleiner en meer buigsame pakket behaal, maar prestasie in koderingstake buite generering (bv. regstelling en verklaring) kan agterbly by kodegenerasieprestasie. Li et al. 2023a Lozhkov et al. 2024 Nijkamp et al. 2023 Rozie`re et al. 2023 CodeGemma Team et al. 2024 In baie ondernemingskontekste kan LLM-adatpsie verder bemoeilik word deur faktore buite die prestasie van die modelle. Byvoorbeeld, selfs oop modelle word soms geteister deur 'n gebrek aan deursigtigheid oor die databronne en dataverwerkingsmetodes wat in die model ingesluit is, wat vertroue in modelle in missiekritieke en gereguleerde kontekste kan ondermyn. Verder kan lisensieterme in vandag se oop LLMs 'n onderneming se vermoë om 'n model te gebruik, beperk en bemoeilik. Hier bied ons Granite Code-modelle aan, 'n reeks hoogs bekwame kodegenererende LLMs, ontwerp om ondernemingsagteware-ontwikkeling oor 'n wye reeks koderingstake te ondersteun. Granite Code-modelle het twee hoofvariante wat ons in vier verskillende groottes (3B, 8B, 20B en 34B) vrystel: basiese fondamentmodelle vir kode-verwante take; Granite Code Basis: instruksie-volgende modelle gefine-tuned met behulp van 'n kombinasie van Git-verbintenisse gekoppel aan menslike instruksies en oopbron sinteties gegenereerde kodinstruksiedatastelle. Granite Code Instruct: Die basismodelle in die reeks is van voor af opgelei met 'n tweefase-opleidingsstrategie. In fase 1 word ons model opgelei op 3 tot 4 biljoen tokens verkry uit 116 programmeertale, wat 'n omvattende begrip van programmeertale en sintaksis verseker. In fase 2 word ons model verder opgelei op 500 miljard tokens met 'n noukeurig ontwerpte mengsel van hoëgehalte data uit kode- en natuurlike taalvelde om die model se vermoë om te redeneer te verbeter. Ons gebruik die onbewaakte taalmodelleringsdoelwit om die basismodelle in beide fases van opleiding te oefen. Die instruksiemodelle is afgelei deur die bogenoemde opgeleide basismodelle verder te fine-tune op 'n kombinasie van 'n gefiltreerde variant van CommitPack ( , ), natuurlike taal instruksie-volgende datastelle (OASST ( , ), HelpSteer ( , )) en oopbron wiskunde datastelle (MathInstruct ( , ) en MetaMathQA ( , )), insluitend sinteties gegenereerde kodedatastelle vir die verbetering van instruksie-volgende en redeneervermoëns. Muennighoff et al. 2023 Ko¨ pf et al. 2023 Wang et al. 2023 Yue et al. 2023 Yu et al. 2023 Ons voer uitgebreide evaluasies van ons kodegenererende LLMs uit op 'n omvattende stel benchmarks, insluitend HumanEvalPack ( , ), MBPP(+) ( , ; , ), RepoBench ( , ), ReCode ( , ), en meer. Hierdie stel benchmarks omvat baie verskillende soorte koderingstake benewens net kodsyntese in Python, bv. kode regstelling, kode verklaring, kode redigering, kodetranslasie, ens., oor die meeste groot programmeertale (Python, JavaScript, Java, Go, C++, Rust, ens.). Muennighoff et al. 2023 Austin et al. 2021 Liu et al. 2023a Liu et al. 2023b Wang et al. 2022 Ons bevindinge toon dat onder oopbronmodelle, die Granite Code-modelle oor die algemeen baie sterk prestasie oor alle modelgroottes en benchmarks toon (dikwels beter as ander oopbron kodemodelle wat twee keer so groot is as Granite). As 'n illustrasie toon figuur (bo) 'n vergelyking van Granite-8B-Code-Base met ander oopbron basis kodemodelle, insluitend onlangse hoë-presterende algemene basis LLMs soos Mistral ( , ) en LLama-3 ( , ) op HumanEvalPack ( , ). Terwyl CodeGemma en StarCoder2 redelik goed presteer in kodegenerering, presteer hulle aansienlik swakker op die kode regstelling en verklaring variante van HumanEvalPack. Gemiddeld presteer Granite-8B-Code-Base byna 12 punte beter as die mees mededingende CodeGemma-8B-model op HumanEvalPack (33.2% vs 21.3%), ten spyte daarvan dat dit op aansienlik minder tokens opgelei is (4.5T vs 7.5T tokens). Benewens basismodelle, toon die instruksie-tuned variante van ons Granite Code-modelle ook sterk prestasie op HumanEvalPack, wat ander oopbron (kode) instruksiemodelle oortref, wat voordele toon vir 'n wyer stel koderingstake met natuurlike taal instruksies (sien figuur (onder)). 1 Jiang et al. 2023b AI@Meta 2024 Muennighoff et al. 2023 1 Verder, aangesien redenering van kritieke belang is vir die oplossing van ingewikkelde vrae en take, toets ons ook ons Granite-8B-Code-Base model op ses wiskundige benchmarks, insluitend MATH ( , ), GSM8K ( , ) en probleemoplossing met toegang tot berekeningsinstrumente, waar ons Granite 8B-model beter prestasie behaal in vergelyking met die meeste toonaangewende 7B of 8B LLMs. Byvoorbeeld, Granite-8B-Code-Base presteer 12 punte beter as Llama-3-8B-Base op GSM8K en 6 punte beter op MATH (sien tabel ). Cobbe et al. 2021 Cobbe et al. 2021 15 Die sleutelvoordele van Granite Code-modelle sluit in: : Granite Code-modelle behaal mededingende of toonaangewende prestasie op verskillende soorte kode-verwante take, insluitend kodegenerering, verklaring, regstelling, redigering, translasie, ens., wat hul vermoë om diverse koderingstake op te los, demonstreer; All-rounder Kodegenererende LLM : Al ons modelle is opgelei op lisensie-toelaatbare data wat ingesamel is volgens IBM se AI Etiek beginsels en gelei deur IBM se Korporatiewe Regspan vir betroubare ondernemingsgebruik. Al die Granite Code-modelle word vrygestel onder die Apache 2.0-lisensie. Betroubare Ondernemingsgraad LLM 1 Ons beskryf ons volledige data-insameling, filtering en voorverwerkingspyplyn in afdeling . Afdeling beskryf die besonderhede van die modelargitektuur, gevolg deur opleidingsbesonderhede in Afdeling . Afdeling verskaf die besonderhede oor instruksie-fine-tuning, en Afdeling beskryf die eksperimente en resultate wat Granite Code-modelle met ander oopbron LLMs vergelyk. 2 3 4 5 6 2 Data-insameling In hierdie afdeling beskryf ons die proses van kruip en filtering (Sek. ), deduplikasie (Sek. ), HAP/PII-filtering (Sek. ) wat gebruik is om die koddata voor te berei vir modelopleiding. Ons verskaf ook 'n oorsig van hoëgehalte natuurlike taaldata wat gebruik is om die model se taalverstaan- en wiskundige redeneervaardighede te verbeter. 2.1 2.2 2.3 2.1 Data Kruip en Filtering Die vooraf-opleidingskoddata is verkry uit 'n kombinasie van publiek beskikbare datastelle soos Github Code Clean , StarCoderdata , en bykomende publieke kodbewaarplekke en kwessies van GitHub. Ons filter rou data om 'n lys van 116 programmeertale uit meer as 300 tale te behou, soos uiteengesit in bylae . Die toekenning van data aan programmeertale word slegs gebaseer op lêeruitbreiding uitgevoer, soortgelyk aan StarCoder ( , ). Na taal filtering pas ons vier sleutelfilterreëls toe om laer-gehalte kode uit te filter ( , ): (1) verwyder lêers met minder as 25% alfabetiese karakters, (2) behalwe vir die XSLT-taal, filter lêers uit waar die string "<?xml version=” binne die eerste 100 karakters voorkom, (3) vir HTML-lêers, hou slegs lêers waar die sigbare teks minstens 20% van die HTML-kode uitmaak en 'n minimum lengte van 100 karakters het, (4) vir JSON- en YAML-lêers, hou slegs lêers wat 'n karaktertelling tussen 50 en 5000 karakters het. Ons filter ook GitHub-kwessies met behulp van 'n stel kwaliteitsmetrieke wat die verwydering van outomaties gegenereerde teks insluit, die filtering van nie-Engelse kwessies, die uitsluiting van kommentaar deur bots, en die gebruik van die aantal gebruikers wat aan die gesprek deelneem as 'n aanduider van kwaliteit. Ons annoteer ook elke kodlêer met lisensie-inligting wat aan die onderskeie bewaarplek gekoppel is, gevind via GitHub APIs en hou slegs lêers met permissiewe lisensies vir modelopleiding. 2 3 A Li et al. 2023a Li et al. 2023a 2.2 Eksakte en Fuzzy Deduplikasie Ons pas 'n aggressiewe deduplikasie-strategie toe, insluitend beide eksakte en fuzzy deduplikasie, om dokumente met (naasteby) identiese kodinhoud in ons opleidingsstel te verwyder. Vir eksakte deduplikasie bereken ons eers die SHA256-hash van die dokumentinhoud en verwyder rekords met identiese haske. Na eksakte deduplikasie pas ons fuzzy deduplikasie toe met die doel om kodlêers te verwyder wat effense variasies mag hê en sodoende die data verder onbevooroordeeld maak. Ons pas 'n tweestapmetode hiervoor toe: (1) bereken MinHashes van alle dokumente en gebruik dan Locally Sensitive Hashing (LSH) om dokumente te groepeer op grond van hul MinHash-vingerafdrukke, (2) meet Jaccard-soortgelykheid tussen elke paar dokumente in dieselfde emmer en annoteer dokumente behalwe een as duplikate op grond van 'n soortgelykheidstrempel van 0.7. Ons pas hierdie naby-deduplikasieproses toe op alle programmeertale, insluitend GitHub-kwessies, om die rykheid en diversiteit van die opleidingsdatastel te verbeter. 2.3 HAP, PII, Malware Filtering Om die waarskynlikheid van die generering van haatlike, beledigende of onwelvoeglike (HAP) taal uit die modelle te verminder, doen ons ywerige pogings om HAP-inhoud uit die opleidingsstel te filter. Ons skep eers 'n woordeboek van HAP-sleutelwoorde en annoteer dan elke koddokument met die aantal voorkomste van sulke sleutelwoorde in die inhoud, insluitend kommentaar. Ons filter dokumente uit wat die HAP-drempel oorskry, wat bereken word op grond van 'n distribusionele analise asook handmatige inspeksie van kodlêers. Verder, om privaatheid te beskerm, volg ons StarCoder ( , ) en doen ons ywerige pogings om Persoonlik Identifiseerbare Inligting (PII) uit die opleidingsstel te redigeer. Spesifiek, ons gebruik die StarPII -model om IP-adresse, sleutels, e-posadresse, name, gebruikersname en wagwoorde wat in die inhoud voorkom, op te spoor. Die PII-redigeringsstap vervang die PII-teks met die ooreenstemmende tokens NAME , EMAIL , KEY , PASSWORD en verander die IP-adres met 'n sinteties gegenereerde IP-adres, soos in Li et al. (2023a). Ons skandeer ook ons datastelle met om gevalle van wanware in die bronkode te identifiseer en te verwyder. Li et al. 2023a 4 2.4 Natuurlike Taal Datastelle Benewens die insameling van koddata vir modelopleiding, kurateer ons verskeie publiek beskikbare hoëgehalte natuurlike taaldatastelle om die model se vaardigheid in taalverstaan- en wiskundige redenering te verbeter. Verteenwoordigende datastelle onder hierdie kategorie sluit webdokumente in (Stackexchange, CommonCrawl), wiskundige webtes (OpenWeb-Math; ( ), StackMathQA; ( )), akademiese teks (Arxiv, Wikipedia), en instruksie-tuning datastelle (FLAN; ( ), HelpSteer ( , )). Ons dedupliseer hierdie reeds voorafverwerkte natuurlike taaldatastelle nie. Paster et al. 2023 Zhang 2024 Longpre et al. 2023 Wang et al. 2023 3 Modelargitektuur Ons oefen 'n reeks kodemodelle van verskillende groottes gebaseer op die transformer-dekoder argitektuur ( , ). Die model hipersparameters vir hierdie modelle word in Tabel gegee. Vir alle modelargitekture gebruik ons voor-normalisering ( , ): normalisering toegepas op die inset van die aandag- en MLP-blokke. Vaswani et al. 2017 1 Xiong et al. 2020 : Die kleinste model in die Granite-kode model familie is opgelei met RoPE-inbedding ( , ) en Multi-Head Attention ( , ). Hierdie model gebruik die swish-aktiveringsfunksie ( , ) met GLU ( , ) vir die MLP, ook algemeen verwys as swiglu. Vir normalisering gebruik ons RMSNorm ( , ) aangesien dit berekeningsmatig doeltreffender is as LayerNorm ( , ). Die 3B-model is opgelei met 'n kontekslengte van 2048 tokens. 3B Su et al. 2023 Vaswani et al. 2017 Ramachandran et al. 2017 Shazeer 2020 Zhang & Sennrich 2019 Ba et al. 2016 : Die 8B-model het 'n soortgelyke argitektuur as die 3B-model met die uitsondering van die gebruik van Grouped-Query Attention (GQA) ( , ). Die gebruik van GQA bied 'n beter afweging tussen modelprestasie en inferensiedoeltreffendheid op hierdie skaal. Ons oefen die 8B-model met 'n kontekslengte van 4096 tokens. 8B Ainslie et al. 2023 : Die 20B-kodemodel is opgelei met geleerde absolute posisie-inbeddings. Ons gebruik Multi-Query Attention ( , ) tydens opleiding vir doeltreffende afwaartse inferensie. Vir die MLP-blok gebruik ons die GELU-aktiveringsfunksie ( , ). Vir die normalisering van die aktiverings gebruik ons LayerNorm ( , ). Hierdie model is opgelei met 'n kontekslengte van 8192 tokens. 20B Shazeer 2019 Hendrycks & Gimpel 2023 Ba et al. 2016 : Om die 34B-model op te lei, volg ons die benadering deur vir diepte-opskaal van die 20B-model. Spesifiek, ons verdubbel eers die 20B-kodemodel met 52 lae en verwyder dan die finale 8 lae van die oorspronklike model en die aanvanklike 8 lae van sy duplikaat om twee modelle te vorm. 34B Kim et al. Ten slotte, ons voeg beide modelle saam om die Granite-34B-Code-model met 88 lae te vorm (sien Figuur vir 'n illustrasie). Na die diepte-opskaal, waarneem ons dat die daling in prestasie vergeleke met die 20B-model baie klein is, anders as wat waargeneem word deur Hierdie prestasie word redelik vinnig herstel nadat ons die vooraf-opleiding van die opgeskaalde 34B-model voortgesit het. Soortgelyk aan 20B, gebruik ons 'n 8192-token konteks tydens voor-opleiding. 2 Kim et al. 4 Voor-opleiding In hierdie afdeling verskaf ons besonderhede oor die tweefase-opleiding (Sek. ), opleidingsdoelwitte (Sek. ), optimisasie (Sek. ) en infrastruktuur (Sek. ) wat gebruik is in die voor-opleiding van die modelle. 4.1 4.2 4.3 4.4 4.1 Tweefase-opleiding Granite Code-modelle word opgelei op 3.5T tot 4.5T tokens van koddata en natuurlike taaldatastelle wat met kode verband hou. Data word getokeniseer via byte pair encoding (BPE, ( , )), wat dieselfde tokenizer as StarCoder gebruik ( , ). In ooreenstemming met ( , ; , ), gebruik ons hoëgehalte data met twee fases van opleiding soos volg. Sennrich et al. 2015 Li et al. 2023a Shen et al. 2024 Hu et al. 2024 • : Gedurende fase 1 word beide 3B- en 8B-modelle vir 4 biljoen tokens van koddata, bestaande uit 116 tale, opgelei. Die 20B-parameter model word op 3 biljoen tokens kode opgelei. Die 34B-model word op 1.4T tokens opgelei na die diepte-opskaal wat op die 1.6T-kontrolepunt van die 20B-model gedoen word. Fase 1 (slegs kodopleiding) • : In fase 2 sluit ons bykomende hoëgehalte publiek beskikbare data uit verskeie domeine in, insluitend tegniese, wiskundige en webdokumente, om die model se prestasie in redenering- en probleemoplossingsvaardighede, wat noodsaaklik is vir kodgenerering, verder te verbeter. Ons oefen al ons modelle vir 500B tokens (80% kode en 20% taaldatavolume) in fase 2 opleiding. Fase 2 (kode + taalopleiding) 4.2 Opleidingsdoelwit Vir die opleiding van al ons modelle gebruik ons die kausale taalmodelleringsdoelwit en Fill-In-the-Middle (FIM) ( , ) doelwit. Die FIM-doelwit is om ingevoegde tokens te voorspel met die gegewe konteks en daaropvolgende teks. Ons oefen ons modelle om met beide PSM (Prefix-Suffix-Middle) en SPM (Suffix-Prefix-Middle) modusse te werk, met relevante formateringbeheer tokens, dieselfde as StarCoder ( , ). Bavarian et al. 2022 Li et al. 2023a Die algehele verlies word bereken as 'n geweegde kombinasie van die 2 doelwitte: