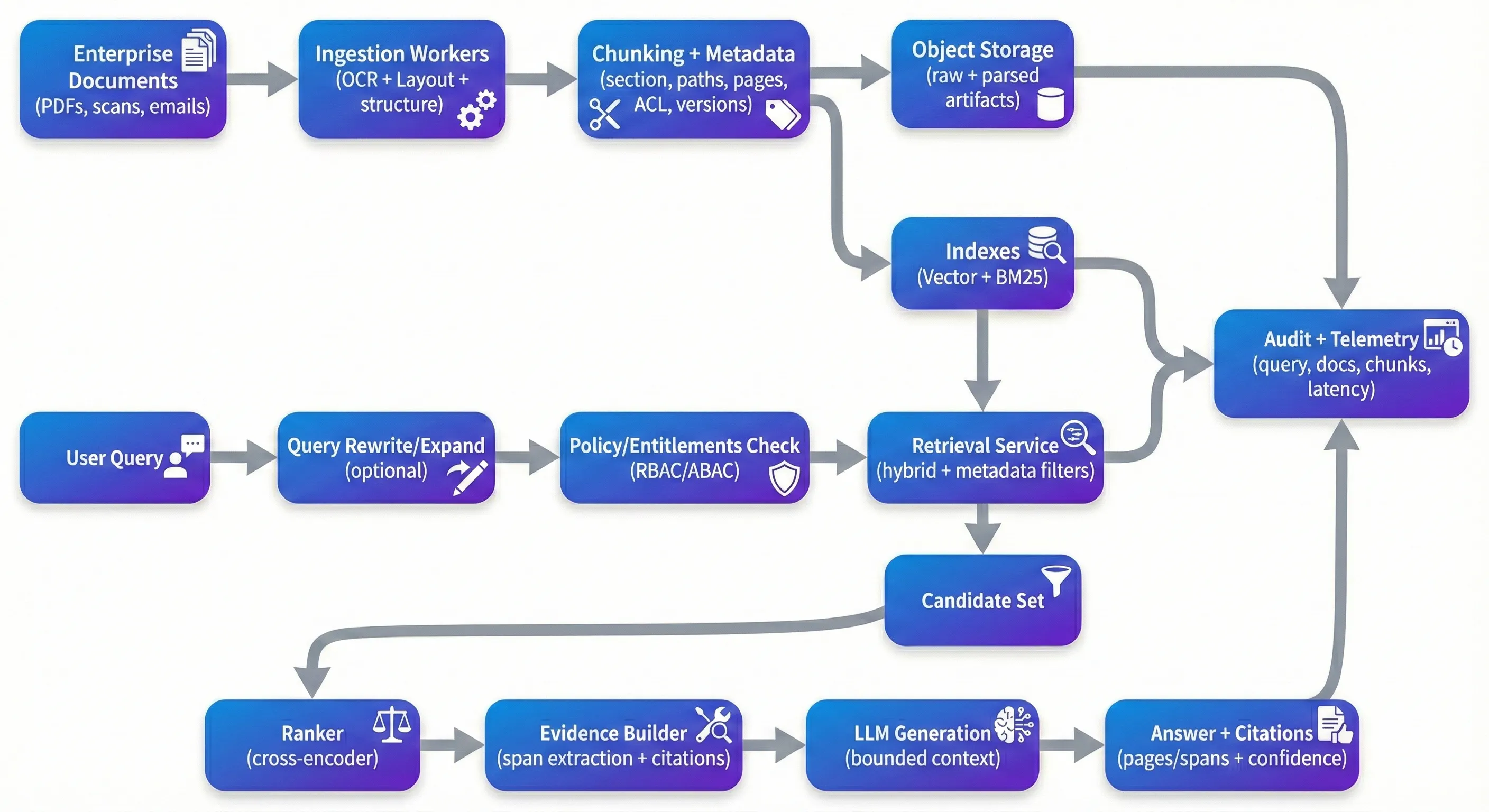
RAG is oral—en dit is nie verbasend nie. Dit is een van die mees praktiese maniere om groot dokumengroepe te maak sonder om breekbare, domein-spesifieke analiseurs vir elke vraagstype te bou. Die vang is dat wat in 'n beheerde demo werk, dikwels vinnig afneem wanneer jy dit voor werklike ondernemings-PDF's plaas: geskante kontrakte, ooreenstemmings, mediese rekords, beleid, en die lang haak van opstelling en kwaliteitsprobleme wat daarmee gepaard gaan. In produksie, is die "RAG-probleem" minder oor slim oproep en meer oor herhaalbaarheid: spoorbaarheid, sekuriteit, kwaliteitskontrole en die vermoë om te verduidelik waarom 'n antwoord korrek is (of waarom die stelsel geweier het). Dit is omdat die stelsel nie konsekwent antwoorde op die regte bewyse kan grond nie, nie bevoegdhede betroubaar kan handhaaf nie, of nie geëvalueer en verbeter kan word sonder om dinge te breek nie. The Demo Trap Die demo trap Die meeste prototipes volg dieselfde pad: drop dokumente in 'n vektorwinkel, vind top-k-stukke, en vra 'n LLM om te sinteseer. Op skoon, goed gestruktureerde teks, wat uitstekend kan lyk. Die probleem is wat volgende gebeur. Geskandeerde PDF's kom in gedraaide of verdraaide. Multi-kolom lees volgorde word geskraap. Tabels verloor struktuur tydens ekstraksie. Chunking splits midde-argument. Retrieval gee 'n "naak genoeg" konteks terug wat plausibel lees, maar nie werklik ondersteun die eis nie. En die model, wat doen wat dit geoptimaliseer is om te doen, antwoord vloeiend in elk geval. In produksie optimiseer jy vir verskillende eienskappe as 'n demo. Jy wil hê dat die stelsel betroubaar is oor rommelige inputs, reproduceerbaar oor pipeline veranderinge, en verdedigbaar onder toets. Dit beteken dat jy 'n antwoord kan spoor terug na spesifieke bewyse, en het sterk standaarde wanneer bewyse swak is: verduidelik vrae, weier gedrag, of bied "beste beskikbare bewyse" met uitdruklike onsekerheid. Ingestion: Where Quality Is Won or Lost Ingesteldheid: Waar gewen of verlore kwaliteit As jy 'n paar van hierdie stelsels gebou het, leer jy vinnig dat inname meer as die meeste downstream truuks die kwaliteit van herstel bepaal. Dokumente AI-voorverwerking is nie glamouurig nie, maar dit is waar jy struktuur bewaar - of dit permanent verloor. Vir ondernemingsdokumente is OCR alleen nie genoeg nie; jy benodig gewoonlik OCR met opsteldeteksie, lees-orde-herbou en struktuur-uittreksel wat koppe, afdelings en tabelle betekenisvol hou. Beheerde gereedskap soos Google Document AI, Azure Document Intelligence en Amazon Textract kan baie grond bedek. Open-source pipelines soos Unstructured en GROBID is algemeen wanneer jy transparensie of strengere beheer oor parsingbesluite nodig het. Chunking is waar teams dikwels die kompleksiteit onderskatting. 'N eenvoudige karakter of token splitsing is vinnig, maar dit is geneig om semantiese grense te sny - presies die grense wat gebruikers omgee in kontrakte en beleid. Adaptiewe chunking wat koppe, afdelinggrense en tabelgrense volg, verbeter gewoonlik beide opname en downstream grondlegging. Dit maak ook oorsprong natuurlik vir die eindgebruiker: in plaas van 'n duidelike interne ID soos chunk_4892, kan jy aandui op iets wat 'n beoordelaar onmiddellik kan verifieer - "MSA v3.2 → Afdeling 9 (End) → 9.2 (End for Cause), bladsy 12, rye 14-22." Metagegevens is nog 'n gebied wat geneig is om optioneel te lyk totdat jy dit nodig het. In die praktyk is metagegevens wat filtering, spoorbaarheid en herhaalbaarheid moontlik maak. Nuttige stukvlak metagegevens sluit gewoonlik in dokumente-ID's, afdelingpads, bladsy nommers, tydstempel (effektiewe datum, laaste gemodifiseer, ingespuit by), uittreksie vertroue-signale, en weergawes (dokument hash, chunking weergawe, embedding model weergawe). In maatskappy konteks, toegangsbeheer-attribute (huurder, afdeling, vertrouwelijkheid, rol tags) moet eersteklas wees, want hulle beperk direk terugvinding en audite. The Retrieval Stack That Actually Works Die Retrieval Stack wat werklik werk Vector gelykheid soek is 'n goeie baseline, maar dit is skaars genoeg op sigself vir maatskappy dokumente. In die praktyk, hybride terugvinding - dun embeddings plus skaars lexikaal terugvinding soos BM25 - is geneig om meer robuust te wees, veral wanneer gebruikers query met paragraaf nommers, identifikators, akronieme, of presiese frases. Reranking is dikwels waar stelsels die grootste sprong in waargenome gehalte maak, nie omdat dit magie is nie, maar omdat dit 'n algemene mislukkingsmodus herstel: die aanvanklike opnameset bevat "kinda relevante" stukke, en jy moet die werklik relevante stukke na die top bevorder. Cross-encoder re-rangers (open modelle soos bge-reranker of bestuurde API's soos Cohere ranker) rescore kandidaat stukke met behulp van 'n dieper query-passage interaksie. Teams sien gewoonlik 'n merkbare toename in konteks akkuraatheid wanneer herrangering behoorlik gemeten word (byvoorbeeld, op 'n goue stel met verwagte bronne). As jy 'n kwantitatiewe eis hier hou, is dit die beste om Query herschryf en uitbreiding is nog 'n hefboom wat maklik is om vroeër te slaan en dan later weer te ontdek. Gebruikers maak natuurlik nie vrae uit die manier waarop dokumente geskryf word nie. 'n herschryfstap kan akronieme uitbrei, entiteite normaliser en verskeie dele vrae verdeel in vindvriendelike subvragen. Dit hoef nie fancy te wees nie, maar dit benodig waarnembaarheid, want ongecontroleerde herschryf kan wegdraai van gebruikersbedoeling. Security: The Layer Everyone Forgets Veiligheid: Die laag wat almal vergeet Die meeste RAG-demo's ignoreer toegangsbeheer omdat dit die prototipe vertraag. In produksie is dit 'n primêre beperking. As u stelsel HR-dokumente, regsovereenkomste en tegniese spesifikasies saam indekser, benodig u 'n deterministiese regverdigingspad van gebruiker → toegelaat stukke, en terugvoer moet deur daardie pad beperk word voordat enige inhoud 'n LLM bereik. Die patroon wat geneig is om te skaal, is vooraf gefilterde vind: berekeningsregte (RBAC / ABAC), haal slegs van stukke met verenigbare ACL-attribute, herank binne die gemagtigde kandidaat-set, en log wat bewyse toeganklik is.Dit is ook waar die "metadata is nie optioneel" punt in die praktyk verskyn - sonder stukke-vlak tagging, eindig jy met lekkage grense of duur, broos post-filters. Behalwe ACL, bedryf ontplooiings benodig gewoonlik 'n kombinasie van PII opsporing / maskering, encryption by rust, kort-lewe tokens vir bron toegang, en audit logging wat query's vang, opgeneem stukke ID's, aanhalings, en dokument weergawes. Een meer moderne besorgdheid waard om ernstig te neem, is vinnige injectie inhoud binne dokumente. Jy hoef nie elke dokument as vyandig te behandel nie, maar jy benodig basiese wagrails sodat instruksies ingebed in bron teks nie jou stelsel se reëls kan vervang nie - veral rondom toegang, beheer en hoe die model toegelaat word om te gedra. Monitoring: Closing the Loop Bewaking: Sluit die loop As u een van hierdie stelsels vir meer as 'n paar weke bedryf, sal u 'n drift sien. Dokumente verander, die verspreiding van die query verander, die inname-pipeline verander, en modelkomponente word opgedateer. Prakties wil jy die gesondheid van die opname (recall@k teen 'n goue stel, kontekspresisie, ranger lift), gesondheid van die generasie (settingpresisie, grond / getrouheidskoers, weieringsratio's) en werksgesondheid (p50 / p95 latensie, koste per query, inname vertraging van dokumente-update na gesoekbare indeks) volg. Die mees effektiewe span wat ek gesien het, hou 'n goue evalueringsdataset - gekurate vrae met verwagte brondokumente - en hardloop dit op 'n skedule en op veranderinge gebeurtenisse (nuwe embeddings, nuwe chunking logika, nuwe dokumente batches). Tools soos Phoenix, TruLens, of kommersiële platforms kan help, maar die groter differensiator is die Een gebied wat dikwels ondergewaardeer word, is weergawe en herhaalbaarheid. Wanneer jy OCR-modelle verander, logika chunking, modelle embedding, herankers of generasie-opdragte, het jy 'n manier nodig om te spoor watter weergawes geproduseer wat antwoorde. Choosing Your Stack Kies jou stapel Stapelbeslissings is belangrik, maar vermoëns is belangriker. Vir baie teams is 'n bestuurde opstel aantreklik: ingeslag deur middel van 'n bestuurde Document AI-tool of ongestruktureerde-gebaseerde pijpleiding, 'n gehost vektordatabasis, 'n orkestrasielaag soos LlamaIndex of LangChain, en 'n herranker (open of bestuurde). Ander verkies oopbron-deplooie met behulp van Qdrant/Weaviate/OpenSearch, Haystack of soortgelyke orkestrasie, en selfhostede modelle vir beheer en koste-voorspelbaarheid. Beide benaderings kan werk as dit die basiese ondersteun: dokumente bewus ingeslag, hibrid herstel, regverklaring, oorsprong-vriendelike sit Aan die kant van die argitektuur word stelsels geneig om makliker te bedryf wanneer hulle skoon verdeel word: ingestel werkers wat asynchrone hardloop en veilig hersteld kan word; 'n statusloze terugvoer diens wat beleid handhaaf en bewyse terugkeer; en 'n generasie diens wat met begrensde konteks en duidelike oorsprong bedryf. 'n Tipiese verwysingsdeplooiing sluit in 'n API-poort, 'n werkhoek (Kafka/RabbitMQ), voorwerpopslag vir ruwe dokumente en gepasseerde artefakte, die indekslaag ( +dense sparse), plus sentrale logging/metrieke en 'n audit spoor.