10 Ways To Refactor Your Python Code

Mar 07, 2021

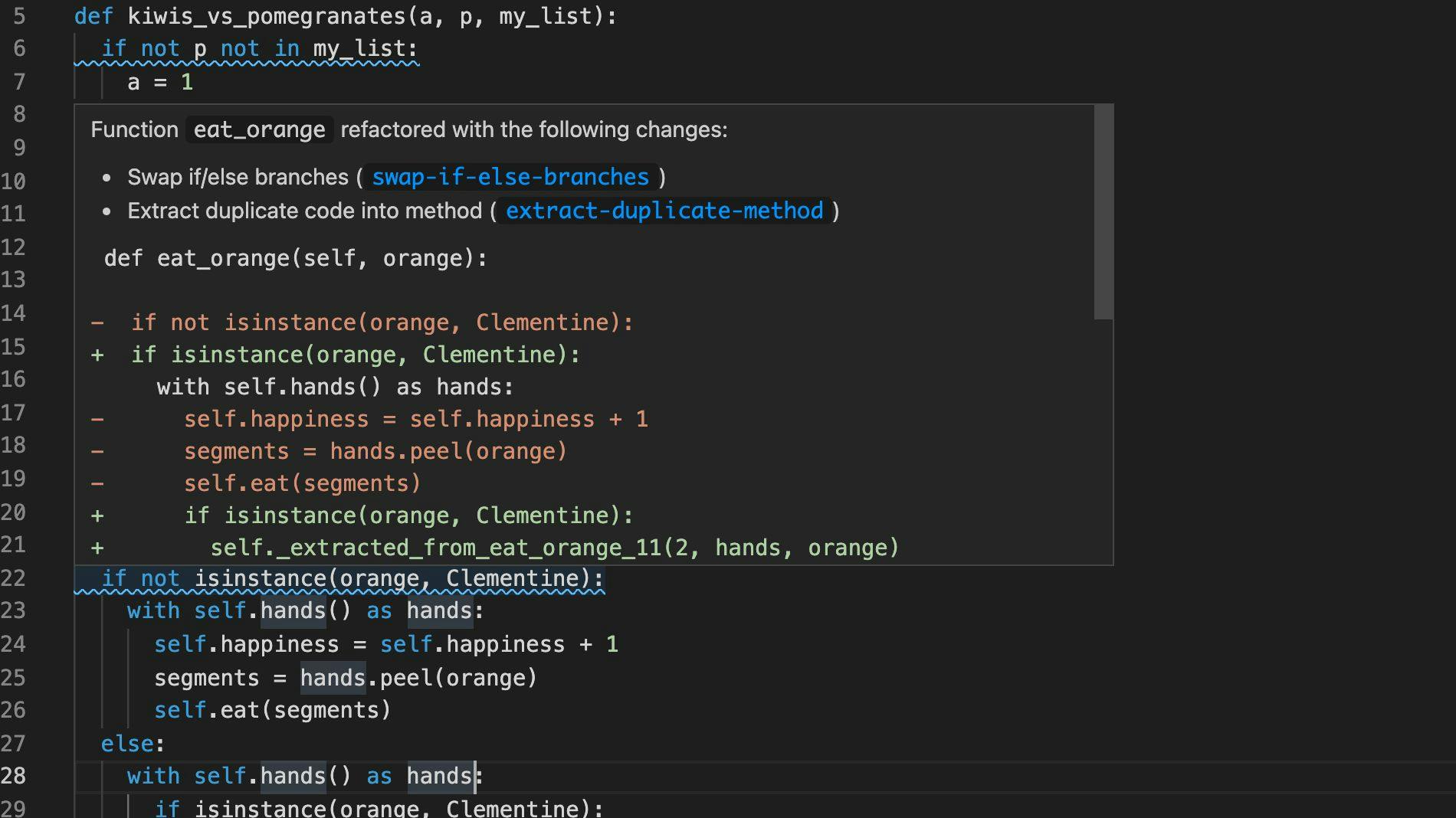
We help you make your Python code easier to read, understand, and work with through automatic refactoring suggestions!
We help you make your Python code easier to read, understand, and work with through automatic refactoring suggestions!
We help you make your Python code easier to read, understand, and work with through automatic refactoring suggestions!
We help you make your Python code easier to read, understand, and work with through automatic refactoring suggestions!