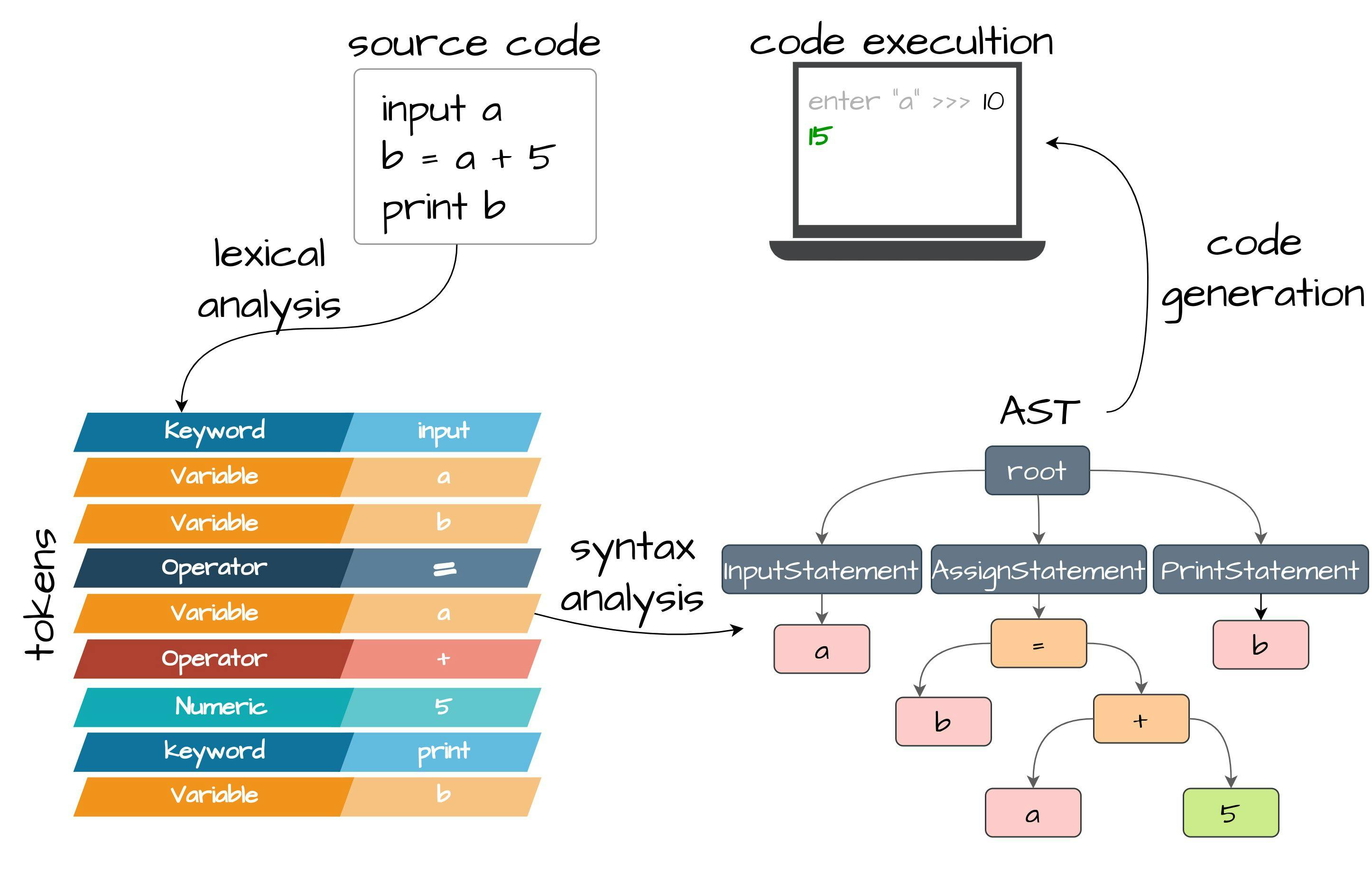
1 Introduction In this tutorial, we will build our own programming language and compiler using Java (you can use any other language, preferably object-oriented). The purpose of the article is to help people who are looking for a way to create their own programming language and compiler. This is a toy example, but it will try to help you understand where to start and in which direction to move. The full source code is available over on GitHub Each language has several stages from the source code to the final executable file. Each of the stages formats incoming data in a certain way: in simple terms it’s a division of the source code into tokens. Each token can contain a different lexeme: keyword, identifier/variable, operator with the corresponding value, etc. Lexical analysis converts a list of incoming tokens into the ( ), which allows you to structurally present the rules of the language being created. The process itself is quite simple as can be seen at the first glance, but with an increase of language constructions, it can become much more complicated. Syntax analysis or parser abstract syntax tree AST After AST has been built we can generate the code. Code is usually generated recursively using an abstract syntax tree. Our compiler for the sake of simplicity will produce statements during the syntax analysis. We will create a simple language with the following abilities: assign the variables (numeric, logical and text) declare structures, create instances and accessing fields perform simple mathematical operations (addition, subtraction, NOT) print variables, values and more complex expressions with mathematical operators read numeric, logical and text values from the console perform if-then statements There is an example of our language’s code, it’s a mix of Ruby and Python syntax: struct Person arg name arg experience arg is_developer end input your_name input your_experience_in_years input do_you_like_programming person = new Person [your_name your_experience_in_years do_you_like_programming == "yes"] print person if person :: is_developer then person_name = person :: name print "hey " + person_name + "!" experience = person :: experience if experience > 0 then started_in = 2022 - experience print "you had started your career in " + started_in end end 2 Lexical analysis First of all, we will start with the lexical analysis. Let’s imagine you got a message from a friend with the following content: “Ienjoyreadingbooks” This expression is a little difficult to read. It’s just a set of letters without any meaning. This is because our natural lexical analyzer can’t find any appropriate word from our dictionary. However, if we put spaces correctly, everything becomes clear: “I enjoy reading books” The lexical analyzer of a programming language works by the same principle. When we talk we highlight individual words by intonation and pauses to understand each other. In the same way we must provide the code to the lexical analyzer to make it understand us. If we write it wrong, the lexical analyzer will not be able to separate individual lexemes, words and syntax constructions. There are six lexemes units (tokens) we will count in our programming language during lexical analysis: Space, carriage return, and other whitespace characters These lexeme units do not make a lot of sense. You can’t declare any code blocks or function parameters by using a space. The main intent is to only help a developer to divide his code into separate lexemes. Therefore, the lexical analyzer will first of all look for spaces and newlines in order to understand how to highlight provided lexemes in the code. Operators: , , , , , + - = < > :: They can be a part of more complex compound statements. The equals sign can mean not only an assignment operator but can also combine a more complex equality compare operator, consisting of two `=` in a row. In this case, the lexical analyzer will try to read expressions from left to right trying to catch the longest operator. Group dividers: , [ ] Group dividers can separate two group lexemes from each other. For example, an open square bracket can be used to mark the beginning of some specific group and a close square bracket will mark the end of the started group. In our language square brackets will be only used to declare struct instance arguments. Keywords: , , , , , , , print input struct arg end new if then A keyword is a set of alphabetic characters with some specific sense assigned by the compiler. For example, a combination of 5 letters `print` makes one word and it’s perceived by the language compiler as a console output statement definition. This meaning cannot be changed by a programmer. That’s the basic idea of keywords, they are language axioms that we combine to create our own statements - programs. Variables or identifiers In addition to the keywords, we also need to take variables into account. A variable is a sequence of characters with some meaning given by a programmer, not a compiler. At the same time, we need to put certain restrictions on variable names. Our variables will contain only letters, numbers, and underscore characters. Other characters within the identifier cannot occur because most of the operators we described are delimiters and therefore cannot be part of another lexeme. In this case, the variable cannot begin with a digit due to the fact that the lexical analyzer detects a digit and immediately tries to match it with a number. Also, it’s important to note that the variable cannot be expressed by a keyword. It means that if our language defines the keyword `print`, then the programmer can’t introduce a variable with the same set of characters defined in the same order. Literals If the given sequence of characters is not a keyword and is not a variable, the last option remains - it can be a literal constant. Our language will be able to define numeric, logical and text literals. Numeric literals are special variables containing digits. For the sake of simplicity, we will not use floating-point numbers (fractions), you can implement it yourself later. Logical literals can contain boolean values: false or true. Text literal is an arbitrary set of characters from the alphabet enclosed in double-quotes. Now that we have the basic information about all possible lexemes in our programming language let’s dive into the code and start declaring our token types. One of the easiest ways to find tokens in source text is to use regular expressions. By having tokens with given regex expressions in the key-value form, you can scan the program code and grab all tokens with the given values. Each token must consist of at least two fields: the token type and its value, for example, a Keyword key with the input value. We will use enum constants with the corresponding Pattern expression for each lexeme type: @RequiredArgsConstructor @Getter public enum TokenType { Whitespace("[\\s\\t\\n\\r]"), Keyword("(if|then|end|print|input|struct|arg|new)"), GroupDivider("(\\[|\\])"), Logical("true|false"), Numeric("[0-9]+"), Text("\"([^\"]*)\""), Variable("[a-zA-Z_]+[a-zA-Z0-9_]*"), Operator("(\\+|\\-|\\>|\\<|\\={1,2}|\\!|\\:{2})"); private final String regex; } To simplify literals parsing I divided each of the literal types into a separate lexeme: , and . For the literal we set a separate group to grab literal value without double quotes. For the equals we declare range. With two equal signs we expect to get the compare operator instead of the assignment. To access a structure field we declared the double colon operator . Numeric Logical Text Text ([^"]*) {1,2} == :: Now to find a token in our code we just iterate and filter all TokenType values applying regex on our source code. To match the beginning of the row we put the meta character in the beginning of each regex expression creating a Pattern instance. The Text token will capture value without quotes into the separate group. Therefore, in order to access value without quotes we grab a value from group with index 1 if we have at least one explicit group: ^ for (TokenType tokenType : TokenType.values()) { Pattern pattern = Pattern.compile("^" + tokenType.getRegex()); Matcher matcher = pattern.matcher(sourceCode); if (matcher.find()) { // group(1) is used to get text literal without double quotes String token = matcher.groupCount() > 0 ? matcher.group(1) : matcher.group(); } } To store found lexemes we need to declare the following Token class with type and value fields: @Builder @Getter public class Token { private final TokenType type; private final String value; } Now we have everything to create our lexical parser. We will receive the source code as a String in the constructor and initialize tokens List: public class LexicalParser { private final List<Token> tokens; private final String source; public LexicalParser(String source) { this.source = source; this.tokens = new ArrayList<>(); } ... } In order to retrieve all tokens from the source code we need to cut the source after each found lexeme. We will declare the method that will accept the current index of the source code as an argument and grab the next token starting after the current position: nextToken() public class LexicalParser { ... private int nextToken(int position) { String nextToken = source.substring(position); for (TokenType tokenType : TokenType.values()) { Pattern pattern = Pattern.compile("^" + tokenType.getRegex()); Matcher matcher = pattern.matcher(nextToken); if (matcher.find()) { if (tokenType != TokenType.Whitespace) { // group(1) is used to get text literal without double quotes String value = matcher.groupCount() > 0 ? matcher.group(1) : matcher.group(); Token token = Token.builder().type(tokenType).value(value).build(); tokens.add(token); } return matcher.group().length(); } } throw new TokenException(String.format("invalid expression: `%s`", nextToken)); } } After successful capture we create a Token instance and accumulate it in the tokens list. We will not add the lexemes as they are only used to divide two lexemes from each other. In the end we return the found lexeme’s length. Whitespace To capture all tokens in the source we create the method with the while loop increasing source position each time we catch a token: parse() public class LexicalParser { ... public List<Token> parse() { int position = 0; while (position < source.length()) { position += nextToken(position); } return tokens; } ... } 3 Syntax analysis Within our compiler model, the syntax analyzer will receive a list of tokens from the lexical analyzer and check whether this sequence can be generated by the language grammar. In the end this syntax analyzer should return an abstract syntax tree. We will start the syntax analyzer by declaring the interface: Expression public interface Expression { } This interface will be used to declare literals, variables and composite expressions with operators. 3.1 Literals First of all, we create implementations for our language’s literal types: , and with corresponding Java types: , and . We will create the base class with generic type extending Comparable (it will be used later with comparison operators): Expression Numeric Text Logical Integer String Boolean Value @RequiredArgsConstructor @Getter public class Value<T extends Comparable<T>> implements Expression { private final T value; @Override public String toString() { return value.toString(); } } public class NumericValue extends Value<Integer> { public NumericValue(Integer value) { super(value); } } public class TextValue extends Value<String> { public TextValue(String value) { super(value); } } public class LogicalValue extends Value<Boolean> { public LogicalValue(Boolean value) { super(value); } } We will also declare for our structure instances: StructureValue public class StructureValue extends Value<StructureExpression> { public StructureValue(StructureExpression value) { super(value); } } will be covered a bit later. StructureExpression 3.2 Variables Variable expression will have a single field representing its name: @AllArgsConstructor @Getter public class VariableExpression implements Expression { private final String name; } 3.3 Structures In order to store a structure instance we will need to know the structure definition and arguments values we are passing to create an object. Argument values can signify any expressions including literals, variables and more complex expressions implementing interface. Therefore, we will use as values type: Expression Expression @RequiredArgsConstructor @Getter public class StructureExpression implements Expression { private final StructureDefinition definition; private final List<Expression> values; } @RequiredArgsConstructor @Getter @EqualsAndHashCode(onlyExplicitlyIncluded = true) public class StructureDefinition { @EqualsAndHashCode.Include private final String name; private final List<String> arguments; } Values can be a type of the . We need a way to access the variable's value by its name. I will delegate this responsibility to the Function interface which will accept variable name and return a object: VariableExpression Value ... public class StructureExpression implements Expression { ... private final Function<String, Value<?>> variableValue; } Now we can implement an interface to retrieve an argument's value by name, it will be used to access the structure instance values. The method will be implemented a bit later: getValue() ... public class StructureExpression implements Expression { … public Value<?> getArgumentValue(String field) { return IntStream .range(0, values.size()) .filter(i -> definition.getArguments().get(i).equals(field)) .mapToObj(this::getValue) //will be implemented later .findFirst() .orElse(null); } } Don’t forget our is used as a parameter for the generic type which extends Comparable. Therefore, we must implement Comparable interface for our : StructureExpression StructureValue StructureExpression ... public class StructureExpression implements Expression, Comparable<StructureExpression> { ... @Override public int compareTo(StructureExpression o) { for (String field : definition.getArguments()) { Value<?> value = getArgumentValue(field); Value<?> oValue = o.getArgumentValue(field); if (value == null && oValue == null) continue; if (value == null) return -1; if (oValue == null) return 1; //noinspection unchecked,rawtypes int result = ((Comparable) value.getValue()).compareTo(oValue.getValue()); if (result != 0) return result; } return 0; } } We can also override the standard method. It will be useful if we want to print an entire structure instance in the console: toString() ... public class ObjectExpression implements Expression, Comparable<ObjectExpression> { ... @Override public String toString() { return IntStream .range(0, values.size()) .mapToObj(i -> { Value<?> value = getValue(i); //will be implemented later String fieldName = definition.getArguments().get(i); return fieldName + " = " + value; }) .collect(Collectors.joining(", ", definition.getName() + " [ ", " ]")); } } 3.4 Operators In our language, we will have unary operators with 1 operand and binary operators with 2 operands. Let’s implement the Expression interface for each of our operators. We declare interface and create base implementations for unary and binary operators: OperatorExpression public interface OperatorExpression extends Expression { } @RequiredArgsConstructor @Getter public class UnaryOperatorExpression implements OperatorExpression { private final Expression value; } @RequiredArgsConstructor @Getter public class BinaryOperatorExpression implements OperatorExpression { private final Expression left; private final Expression right; } We also need to declare an abstract method for each of our operator implementations with corresponding values operands. This method will calculate the from operands depending on each operator’s essence. The operand’s transition from the to the will be covered a bit later. calc() Value Expression Value … public abstract class UnaryOperatorExpression extends OperatorExpression { … public abstract Value<?> calc(Value<?> value); } … public abstract class BinaryOperatorExpression extends OperatorExpression { … public abstract Value<?> calc(Value<?> left, Value<?> right); } After declaring base operator classes we can create more detailed implementations: 3.4.1 NOT ! This operator will only work with the returning the new instance with inverted value: LogicalValue LogicalValue public class NotOperator extends UnaryOperatorExpression { ... @Override public Value<?> calc(Value<?> value) { if (value instanceof LogicalValue) { return new LogicalValue(!((LogicalValue) value.getValue()).getValue()); } else { throw new ExecutionException(String.format("Unable to perform NOT operator for non logical value `%s`", value)); } } } Now we will switch to the implementations with two operands: BinaryOperatorExpression 3.4.2 Addition + The first one is addition. method will make the addition of objects. For the other Value types we will concat values returning instance: calc() NumericValue toString() TextValue public class AdditionOperator extends BinaryOperatorExpression { public AdditionOperator(Expression left, Expression right) { super(left, right); } @Override public Value<?> calc(Value<?> left, Value<?> right) { if (left instanceof NumericValue && right instanceof NumericValue) { return new NumericValue(((NumericValue) left).getValue() + ((NumericValue) right).getValue()); } else { return new TextValue(left.toString() + right.toString()); } } } 3.4.3 Subtraction - will make comparison only if both values have type. In the other case both values will be mapped to the String, removing 2nd value matches from the 1st value: calc() getValue() NumericValue public class SubtractionOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { if (left instanceof NumericValue && right instanceof NumericValue) { return new NumericValue(((NumericValue) left).getValue() - ((NumericValue) right).getValue()); } else { return new TextValue(left.toString().replaceAll(right.toString(), "")); } } } 3.4.4 Equals == will make comparison only if both values have the same type. In the other case both values will be mapped to the String: calc() getValue() public class EqualsOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { boolean result; if (Objects.equals(left.getClass(), right.getClass())) { result = ((Comparable) left.getValue()).compareTo(right.getValue()) == 0; } else { result = ((Comparable) left.toString()).compareTo(right.toString()) == 0; } return new LogicalValue(result); } } 3.4.5 Less than < and greater than > public class LessThanOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { boolean result; if (Objects.equals(left.getClass(), right.getClass())) { result = ((Comparable) left.getValue()).compareTo(right.getValue()) < 0; } else { result = left.toString().compareTo(right.toString()) < 0; } return new LogicalValue(result); } } public class GreaterThanOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { boolean result; if (Objects.equals(left.getClass(), right.getClass())) { result = ((Comparable) left.getValue()).compareTo(right.getValue()) > 0; } else { result = left.toString().compareTo(right.toString()) > 0; } return new LogicalValue(result); } } 3.4.6 Structure value operator :: To read a structure argument’s value we expect to receive the left value as a type: StructureValue public class StructureValueOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { if (left instanceof StructureValue) return ((StructureValue) left).getValue().getArgumentValue(right.toString()); return left; } } 3.5 Value evaluation If we want to pass variables or more complex implementations to the operators including operators itself, we need a way to transform object to the . To do this we declare method in our interface: Expression Expression Value evaluate() Expression public interface Expression { Value<?> evaluate(); } Value class will just return instance: this public class Value<T extends Comparable<T>> implements Expression { ... @Override public Value<?> evaluate() { return this; } } To implement for the first we must provide an ability to get by variable’s name. We delegate this work to the field which will accept variable name and return corresponding object: evaluate() VariableExpression Value Function Value ... public class VariableExpression implements Expression { ... private final Function<String, Value<?>> variableValue; @Override public Value<?> evaluate() { Value<?> value = variableValue.apply(name); if (value == null) { return new TextValue(name); } return value; } } To evaluate the we will create a instance. We need also implement the missing method that will accept an argument index and return value depending on the type: StructureExpression StructureValue getValue() Expression ... public class StructureExpression implements Expression, Comparable<StructureExpression> { ... @Override public Value<?> evaluate() { return new StructureValue(this); } private Value<?> getValue(int index) { Expression expression = values.get(index); if (expression instanceof VariableExpression) { return variableValue.apply(((VariableExpression) expression).getName()); } else { return expression.evaluate(); } } } For the operator expressions we evaluate operand values and pass them to the method: calc() public abstract class UnaryOperatorExpression extends OperatorExpression { ... @Override public Value<?> evaluate() { return calc(getValue().evaluate()); } } public abstract class BinaryOperatorExpression extends OperatorExpression { ... @Override public Value<?> evaluate() { return calc(getLeft().evaluate(), getRight().evaluate()); } } 3.6 Statements Before we start creating our syntax analyzer we need to introduce a model for our language’s statements. Let’s start with the interface with the proceeding method which will be called during code execution: Statement execute() public interface Statement { void execute(); } 3.6.1 Print statement The first statement we will implement is the . This statement needs to know the expression to print. Our language will support printing literals, variables and other expressions implementing which will be evaluated during execution to calculate the object: PrintStatement Expression Value @AllArgsConstructor @Getter public class PrintStatement implements Statement { private final Expression expression; @Override public void execute() { Value<?> value = expression.evaluate(); System.out.println(value); } } 3.6.2 Assign statement To declare an assignment we need to know the variable’s name and the expression we want to assign. Our language will be able to assign literals, variables and more complex expressions implementing interface: Expression @AllArgsConstructor @Getter public class AssignStatement implements Statement { private final String name; private final Expression expression; @Override public void execute() { ... } } During the execution we need to store the variables values somewhere. Let’s delegate this logic to the field which will pass a variable name and the assigning value. Note that value needs to be evaluated while doing an assignment: BiConsumer Expression ... public class AssignStatement implements Statement { ... private final BiConsumer<String, Value<?>> variableSetter; @Override public void execute() { variableSetter.accept(name, expression.evaluate()); } } 3.6.3 Input statement In order to read an expression from the console we need to know the variable name to assign value to. During the we must read a line from the console. This work can be delegated to the , thus we will not create multiple input streams. After reading the line we parse it to the corresponding object and delegate assignment to the instance as we did for the : execute() Supplier Value BiConsumer AssignStatement @AllArgsConstructor @Getter public class InputStatement implements Statement { private final String name; private final Supplier<String> consoleSupplier; private final BiConsumer<String, Value<?>> variableSetter; @Override public void execute() { //just a way to tell the user in which variable the entered value will be assigned System.out.printf("enter \"%s\" >>> ", name.replace("_", " ")); String line = consoleSupplier.get(); Value<?> value; if (line.matches("[0-9]+")) { value = new NumericValue(Integer.parseInt(line)); } else if (line.matches("true|false")) { value = new LogicalValue(Boolean.valueOf(line)); } else { value = new TextValue(line); } variableSetter.accept(name, value); } } 3.6.4 Condition statement First, we will introduce the class which will contain internal list of statements to execute: CompositeStatement @Getter public class CompositeStatement implements Statement { private final List<Statement> statements2Execute = new ArrayList<>(); public void addStatement(Statement statement) { if (statement != null) statements2Execute.add(statement); } @Override public void execute() { statements2Execute.forEach(Statement::execute); } } This class can be reused later in case we create composite statements construction. First of the constructions will be the statement. To describe the condition we can use literals, variables and more complex constructions implementing the interface. In the end during execution we calculate the value of the and make sure the value is Logical and the result inside is truthy. Only in this case we can perform inner statements: Condition Expression Expression @RequiredArgsConstructor @Getter public class ConditionStatement extends CompositeStatement { private final Expression condition; @Override public void execute() { Value<?> value = condition.evaluate(); if (value instanceof LogicalValue) { if (((LogicalValue) value).getValue()) { super.execute(); } } else { throw new ExecutionException(String.format("Cannot compare non logical value `%s`", value)); } } } 3.7 Statement parser Now we have the statements to work with our lexemes, we can now build the . Inside the class we declare a list of tokens and mutable tokens’ position variable: StatementParser public class StatementParser { private final List<Token> tokens; private int position; public StatementParser(List<Token> tokens) { this.tokens = tokens; } ... } Then we create the method which will handle provided tokens and return a full-fledged statement: parseExpression() public Statement parseExpression() { ... } Our language expressions can only begin with declaring a variable or a keyword. Therefore, first we need to read a token and validate that it has the or the token type. To handle this we declare a separate next() method with token types varargs as an argument which will validate that the next token has the same type. In truthy case we increment ’s position field and return the found token: Variable Keyword StatementParser private Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable); ... } private Token next(TokenType type, TokenType... types) { TokenType[] tokenTypes = org.apache.commons.lang3.ArrayUtils.add(types, type); if (position < tokens.size()) { Token token = tokens.get(position); if (Stream.of(tokenTypes).anyMatch(t -> t == token.getType())) { position++; return token; } } Token previousToken = tokens.get(position - 1); throw new SyntaxException(String.format("After `%s` declaration expected any of the following lexemes `%s`", previousToken, Arrays.toString(tokenTypes))); } After we have found the appropriate token, we can build our statement depending on the token type. 3.7.1 Variable Each variable assignment starts with the token type, which we already did read. The next token we expect is the equals operator. You can override the next() method that will accept with String operator representation (e.g. ) and return the next found token only if it has the same type and value as requested: Variable = TokenType = public Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable); switch (token.getType()) { case Variable: next(TokenType.Operator, "="); //skip equals Expression value; if (peek(TokenType.Keyword, "new")) { value = readInstance(); } else { value = readExpression(); } return new AssignStatement(token.getValue(), value, variables::put); } ... } After the equals operator, we read an expression. An expression can start with the keyword when we instantiate a structure. We will cover this case a bit later. To consume a token with intent to validate its value without incrementing position and throwing an error we will create an additional method that will return true value if the next token is the same as we expect: new peek() ... private boolean peek(TokenType type, String value) { if (position < tokens.size()) { Token token = tokens.get(position); return type == token.getType() && token.getValue().equals(value); } return false; } ... To create an instance we need to pass a object to the constructor. Let’s go to the fields declaration and add new Map variables field which will store variable name as a key and variable value as a value: AssignStatement BiConsumer StatementParser public class StatementParser { ... private final Map<String, Value<?>> variables; public StatementParser(List<Token> tokens) { ... this.variables = new HashMap<>(); } ... } Variable Expression First, we will cover the plain variable expression reading that can be a literal, another variable or a more complex expression with operators. Therefore, the method will return the with the corresponding implementations. Inside this method, we declare the left instance. An expression can start only with a literal or with another variable. Thus, we expect to get the , , or token type from our method. After reading a proper token we transform it to the appropriate Expression object inside the following switch block and assign it to the left variable: readExpression() Expression Expression Variable Numeric Logical Text next() Expression private Expression readExpression() { Expression left; Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text); String value = token.getValue(); switch (token.getType()) { case Numeric: left = new NumericValue(Integer.parseInt(value)); case Logical: left = new LogicalValue(Boolean.valueOf(value)); case Text: left = new TextValue(value); case Variable: default: left = new VariableExpression(value, variables::get); } ... } After left variable or literal has been read we expect to catch an lexeme: Operator private Expression readExpression() { Expression left; Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text); String value = token.getValue(); switch (token.getType()) { ... } Token operation = next(TokenType.Operator); Class<? extends OperatorExpression> operatorType = Operator.getType(operation.getValue()); ... } Then we map our lexeme to the object. To do it you can use a switch block returning proper class depending on the token value. I will use enum constants with an appropriate type: Operator OperatorExpression OperatorExpression OperatorExpression @RequiredArgsConstructor @Getter public enum Operator { Not("!", NotOperator.class), Addition("+", AdditionOperator.class), Subtraction("-", SubtractionOperator.class), Equality("==", EqualsOperator.class), GreaterThan(">", GreaterThanOperator.class), LessThan("<", LessThanOperator.class), StructureValue("::", StructureValueOperator.class); private final String character; private final Class<? extends OperatorExpression> operatorType; public static Class<? extends OperatorExpression> getType(String character) { return Arrays.stream(values()) .filter(t -> Objects.equals(t.getCharacter(), character)) .map(Operator::getOperatorType) .findAny().orElse(null); } } In the end we read the right literal or variable as we did for the left . In order to not duplicate code we extract reading into a separate method: Expression Expression nextExpression() private Expression nextExpression() { Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text); String value = token.getValue(); switch (token.getType()) { case Numeric: return new NumericValue(Integer.parseInt(value)); case Logical: return new LogicalValue(Boolean.valueOf(value)); case Text: return new TextValue(value); case Variable: default: return new VariableExpression(value, variables::get); } } Let’s refactor the method and read the right lexeme using . But before we read the right lexeme we need to be sure that our operator supports two operands. We can check if our operator extends the . In the other case if the operator is unary we create an only using the left expression. To create an object we retrieve suitable constructor for unary or binary operator implementation and then create an instance with obtained earlier expressions: readExpression() nextExpression() BinaryOperatorExpression OperatorExpression OperatorExpression @SneakyThrows private Expression readExpression() { Expression left = nextExpression(); Token operation = next(TokenType.Operator); Class<? extends OperatorExpression> operatorType = Operator.getType(operation.getValue()); if (BinaryOperatorExpression.class.isAssignableFrom(operatorType)) { Expression right = nextExpression(); return operatorType .getConstructor(Expression.class, Expression.class) .newInstance(left, right); } else if (UnaryOperatorExpression.class.isAssignableFrom(operatorType)) { return operatorType .getConstructor(Expression.class) .newInstance(left); } return left; } Additionally, we can provide an opportunity to create a long-expression with multiple operators or without operators at all with only one literal or variable. Let’s enclose the operation read into the while loop with the condition that we have an Operator as the next lexeme. Each time we create an , we assign it to the left expression thus creating a tree of subsequent operators inside one until we read the whole expression. In the end we return the left expression: OperatorExpression Expression @SneakyThrows private Expression readExpression() { Expression left = nextExpression(); //recursively read an expression while (peek(TokenType.Operator)) { Token operation = next(TokenType.Operator); Class<? extends OperatorExpression> operatorType = Operator.getType(operation.getValue()); if (BinaryOperatorExpression.class.isAssignableFrom(operatorType)) { Expression right = nextExpression(); left = operatorType .getConstructor(Expression.class, Expression.class) .newInstance(left, right); } else if (UnaryOperatorExpression.class.isAssignableFrom(operatorType)) { left = operatorType .getConstructor(Expression.class) .newInstance(left); } } return left; } private boolean peek(TokenType type) { if (position < tokens.size()) { Token token = tokens.get(position); return token.getType() == type; } return false; } Structure instance After we completed the implementation we can go back to the and finish the implementation to instantiate a structure instance: readExpression() parseExpression() readInstance() According to our language’s semantics we know that our structure instantiation starts with the keyword, we can skip the next token by calling the method. The next lexeme will signify the structure name, we read it as the token type. After the structure name we expect to receive arguments inside square brackets as group dividers. In some cases our structure can be created without any arguments at all. Therefore, we use first. Each passing argument to the structure can mean an expression, thus we call and pass the result to the arguments list. After building structure arguments we can build our preliminarily retrieving appropriate : new next() Variable peek() readExpression() StructureExpression StructureDefinition private Expression readInstance() { next(TokenType.Keyword, "new"); //skip new Token type = next(TokenType.Variable); List<Expression> arguments = new ArrayList<>(); if (peek(TokenType.GroupDivider, "[")) { next(TokenType.GroupDivider, "["); //skip open square bracket while (!peek(TokenType.GroupDivider, "]")) { Expression value = readExpression(); arguments.add(value); } next(TokenType.GroupDivider, "]"); //skip close square bracket } StructureDefinition definition = structures.get(type.getValue()); if (definition == null) { throw new SyntaxException(String.format("Structure is not defined: %s", type.getValue())); } return new StructureExpression(definition, arguments, variables::get); } To retrieve the by name we must declare the structures map as ’s field, we will fill it later during keyword analysis: StructureDefinition StatementParser struct public class StatementParser { ... private final Map<String, StructureDefinition> structures; public StatementParser(List<Token> tokens) { ... this.structures = new HashMap<>(); } ... } 3.7.2 Keyword Now we can continue working on the method when we receive the lexeme: parseExpression() Keyword public Statement parseExpression() { ... switch (token.getType()) { case Variable: ... case Keyword: switch (token.getValue()) { case "print": case "input": case "if": case "struct": } ... } } Our language expression can start with , , and keywords. print input if struct Print To read the printing value we call the already created method. It will read a literal, variable or more complex implementation as we did for the variable assignment. Then we create and return an instance of the : readExpression() Expression PrintStatement ... case "print": Expression expression = readExpression(); return new PrintStatement(expression); ... Input For the input statement, we need to know the variable name we assign value to. Therefore, we ask the method to catch the next token for us: next() Variable ... case "input": Token variable = next(TokenType.Variable); return new InputStatement(variable.getValue(), scanner::nextLine, variables::put); ... To create an instance we introduce a object in the fields declaration which will help us to read a line from the console: InputStatement Scanner StatementParser public class StatementParser { ... private final Scanner scanner; public StatementParser(List<Token> tokens) { ... this.scanner = new Scanner(System.in); } ... } If The next statement we will touch is condition: if/then Firstly, when we receive the keyword, we read the condition expression by calling . Then according to our language semantics, we need to catch the keyword. Inside our condition we can declare other statements including other condition statements. Therefore, we recursively add to the condition’s inner statements until we will read the finalizing keyword: if readExpression() then parseExpression() end ... case "if": Expression condition = readExpression(); next(TokenType.Keyword, "then"); //skip then ConditionStatement conditionStatement = new ConditionStatement(condition); while (!peek(TokenType.Keyword, "end")) { Statement statement = parseExpression(); conditionStatement.addStatement(statement); } next(TokenType.Keyword, "end"); //skip end return conditionStatement; ... Struct Structure declaration is quite simple because it consists only of and token types. After reading the keyword we expect to read the Structure name as token type. Then we read arguments until we end up with the keyword. In the end we build our and put it in the structures map to be accessed in the future when we’ll create a structure instance: Variable Keyword struct Variable end StructureDefinition ... case "struct": Token type = next(TokenType.Variable); Set<String> args = new HashSet<>(); while (!peek(TokenType.Keyword, "end")) { next(TokenType.Keyword, "arg"); Token arg = next(TokenType.Variable); args.add(arg.getValue()); } next(TokenType.Keyword, "end"); //skip end structures.put(type.getValue(), new StructureDefinition(type.getValue(), new ArrayList<>(args))); return null; ... The complete method: parseExpression() ... public Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable); switch (token.getType()) { case Variable: next(TokenType.Operator, "="); //skip equals Expression value; if (peek(TokenType.Keyword, "new")) { value = readInstance(); } else { value = readExpression(); } return new AssignStatement(token.getValue(), value, variables::put); case Keyword: switch (token.getValue()) { case "print": Expression expression = readExpression(); return new PrintStatement(expression); case "input": Token variable = next(TokenType.Variable); return new InputStatement(variable.getValue(), scanner::nextLine, variables::put); case "if": Expression condition = readExpression(); next(TokenType.Keyword, "then"); //skip then ConditionStatement conditionStatement = new ConditionStatement(condition); while (!peek(TokenType.Keyword, "end")) { Statement statement = parseExpression(); conditionStatement.addStatement(statement); } next(TokenType.Keyword, "end"); //skip end return conditionStatement; case "struct": Token type = next(TokenType.Variable); Set<String> args = new HashSet<>(); while (!peek(TokenType.Keyword, "end")) { next(TokenType.Keyword, "arg"); Token arg = next(TokenType.Variable); args.add(arg.getValue()); } next(TokenType.Keyword, "end"); //skip end structures.put(type.getValue(), new StructureDefinition(type.getValue(), new ArrayList<>(args))); return null; } default: throw new SyntaxException(String.format("Statement can't start with the following lexeme `%s`", token)); } } ... To find and accumulate all statements we create method that will parse all expressions from the given tokens and return instance: parse() CompositeStatement ... public Statement parse() { CompositeStatement root = new CompositeStatement(); while (position < tokens.size()) { Statement statement = parseExpression(); root.addStatement(statement); } return root; } ... 4 ToyLanguage We finished with the lexical and syntax analyzer. Now we can gather both implementations into the class and finally run our language: ToyLanguage public class ToyLanguage { @SneakyThrows public void execute(Path path) { String source = Files.readString(path); LexicalParser lexicalParser = new LexicalParser(source); List<Token> tokens = lexicalParser.parse(); StatementParser statementParser = new StatementParser(tokens); Statement statement = statementParser.parse(); statement.execute(); } } 5 Wrapping Up In this tutorial, we built our own language with lexical and syntax analysis. I hope this article will be useful to someone. I highly recommend you to try writing your own language, despite the fact that you have to understand a lot of implementation details. This is a learning, self-improving, and interesting experiment!