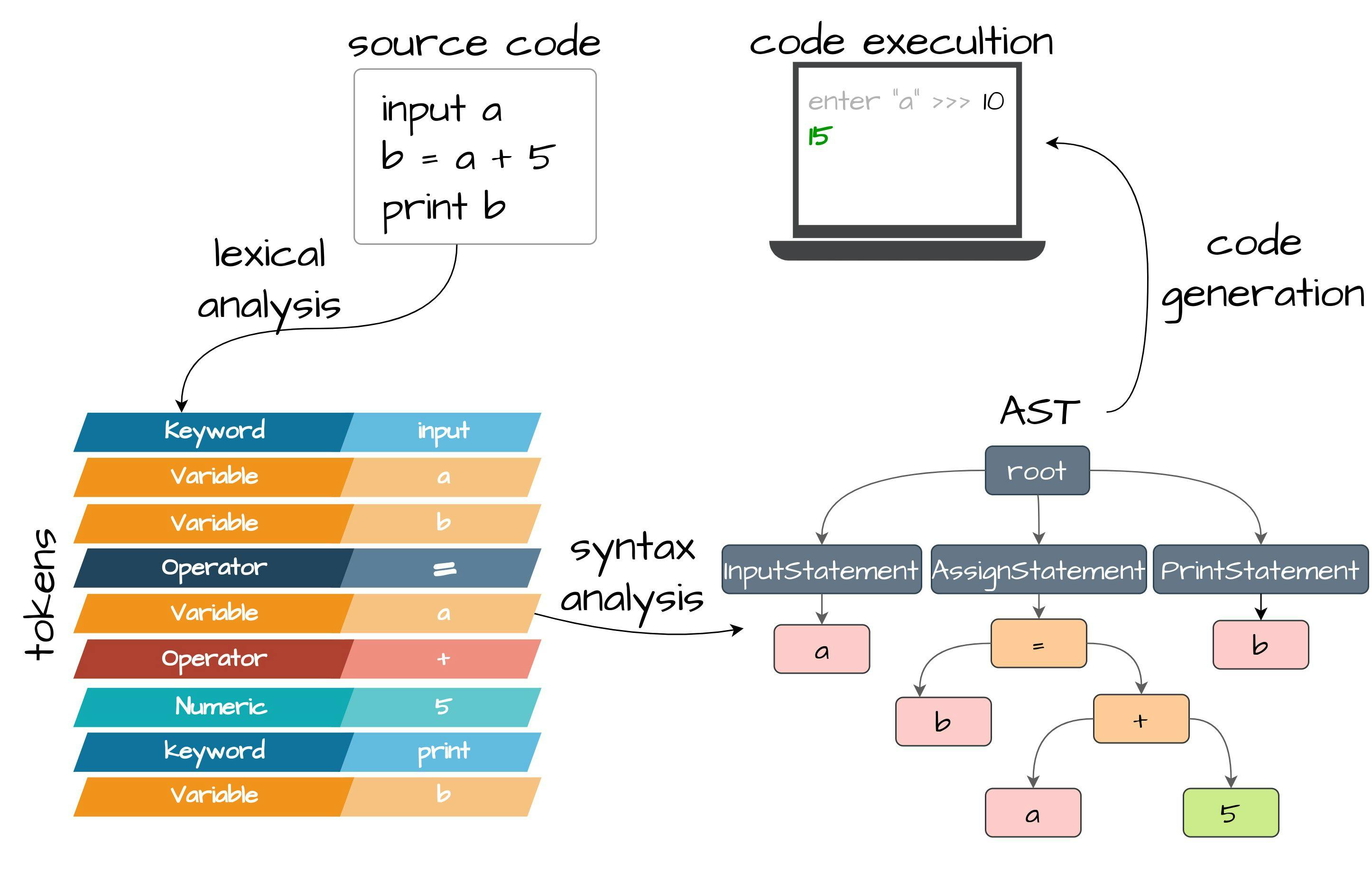
1. Introducción En este tutorial, construiremos nuestro propio lenguaje de programación y compilador usando Java (puedes usar cualquier otro lenguaje, preferiblemente orientado a objetos). El propósito de este artículo es ayudar a las personas que buscan una forma de crear su propio lenguaje de programación y compilador. Este es un ejemplo de juguete, pero intentará ayudarlo a comprender por dónde empezar y en qué dirección moverse. El código fuente completo está disponible en GitHub Cada idioma tiene varias etapas desde el código fuente hasta el archivo ejecutable final. Cada una de las etapas formatea los datos entrantes de cierta manera: en términos simples es una división del código fuente en tokens. Cada token puede contener un lexema diferente: palabra clave, identificador/variable, operador con el valor correspondiente, etc. El análisis léxico convierte una lista de tokens entrantes en el ( ), que le permite presentar estructuralmente las reglas del lenguaje que se está creando. El proceso en sí es bastante simple, como se puede ver a primera vista, pero con un aumento de las construcciones del lenguaje, puede volverse mucho más complicado. El análisis de sintaxis o analizador árbol de sintaxis abstracta AST Una vez que se ha creado AST, podemos generar el código. El código generalmente se genera recursivamente usando un árbol de sintaxis abstracta. Nuestro compilador, en aras de la simplicidad, producirá declaraciones durante el análisis de sintaxis. Crearemos un lenguaje sencillo con las siguientes capacidades: asignar las variables (numéricas, lógicas y de texto) declarar estructuras, crear instancias y acceder a campos realizar operaciones matemáticas simples (suma, resta, NOT) imprimir variables, valores y expresiones más complejas con operadores matemáticos leer valores numéricos, lógicos y de texto desde la consola realizar sentencias si-entonces Hay un ejemplo del código de nuestro lenguaje, es una mezcla de sintaxis de Ruby y Python: struct Person arg name arg experience arg is_developer end input your_name input your_experience_in_years input do_you_like_programming person = new Person [your_name your_experience_in_years do_you_like_programming == "yes"] print person if person :: is_developer then person_name = person :: name print "hey " + person_name + "!" experience = person :: experience if experience > 0 then started_in = 2022 - experience print "you had started your career in " + started_in end end 2 Análisis léxico En primer lugar, comenzaremos con el análisis léxico. Imaginemos que recibiste un mensaje de un amigo con el siguiente contenido: “Ienjoyreadingbooks” Esta expresión es un poco difícil de leer. Es solo un conjunto de letras sin ningún significado. Esto se debe a que nuestro analizador léxico natural no puede encontrar ninguna palabra apropiada en nuestro diccionario. Sin embargo, si ponemos los espacios correctamente, todo queda claro: “I enjoy reading books” El analizador léxico de un lenguaje de programación funciona según el mismo principio. Cuando hablamos destacamos palabras individuales por entonación y pausas para entendernos. De la misma forma debemos proporcionar el código al analizador léxico para que nos entienda. Si lo escribimos mal, el analizador léxico no podrá separar lexemas, palabras y construcciones sintácticas individuales. Hay seis unidades de lexemas (tokens) que contaremos en nuestro lenguaje de programación durante el análisis léxico: Espacio, retorno de carro y otros caracteres de espacio en blanco Estas unidades de lexema no tienen mucho sentido. No puede declarar ningún bloque de código o parámetro de función usando un espacio. La intención principal es solo ayudar a un desarrollador a dividir su código en lexemas separados. Por lo tanto, el analizador léxico primero buscará espacios y saltos de línea para comprender cómo resaltar los lexemas proporcionados en el código. Operadores: , , , , , + - = < > :: Pueden ser parte de declaraciones compuestas más complejas. El signo igual puede significar no solo un operador de asignación, sino que también puede combinar un operador de comparación de igualdad más complejo, que consta de dos `=` en una fila. En este caso, el analizador léxico intentará leer las expresiones de izquierda a derecha intentando captar el operador más largo. Divisores de grupo: , [ ] Los divisores de grupo pueden separar dos lexemas de grupo entre sí. Por ejemplo, se puede usar un corchete abierto para marcar el comienzo de un grupo específico y un corchete cerrado marcará el final del grupo iniciado. En nuestro idioma, los corchetes solo se utilizarán para declarar argumentos de instancia de estructura. Palabras clave: , , , , , , , print input struct arg end new if then Una palabra clave es un conjunto de caracteres alfabéticos con algún sentido específico asignado por el compilador. Por ejemplo, una combinación de 5 letras `print` forma una palabra y el compilador del lenguaje la percibe como una definición de declaración de salida de la consola. Este significado no puede ser cambiado por un programador. Esa es la idea básica de las palabras clave, son axiomas del lenguaje que combinamos para crear nuestras propias declaraciones: programas. Variables o identificadores Además de las palabras clave, también debemos tener en cuenta las variables. Una variable es una secuencia de caracteres con algún significado dado por un programador, no por un compilador. Al mismo tiempo, debemos poner ciertas restricciones en los nombres de las variables. Nuestras variables contendrán solo letras, números y caracteres de subrayado. No pueden aparecer otros caracteres dentro del identificador porque la mayoría de los operadores que describimos son delimitadores y, por lo tanto, no pueden formar parte de otro lexema. En este caso, la variable no puede comenzar con un dígito debido a que el analizador léxico detecta un dígito e inmediatamente intenta relacionarlo con un número. Además, es importante tener en cuenta que la variable no se puede expresar mediante una palabra clave. Significa que si nuestro lenguaje define la palabra clave `imprimir`, entonces el programador no puede introducir una variable con el mismo conjunto de caracteres definidos en el mismo orden. literales Si la secuencia de caracteres dada no es una palabra clave y no es una variable, la última opción permanece: puede ser una constante literal. Nuestro lenguaje podrá definir literales numéricos, lógicos y de texto. Los literales numéricos son variables especiales que contienen dígitos. En aras de la simplicidad, no usaremos números de punto flotante (fracciones), puede implementarlo usted mismo más adelante. Los literales lógicos pueden contener valores booleanos: falso o verdadero. El literal de texto es un conjunto arbitrario de caracteres del alfabeto entre comillas dobles. Ahora que tenemos la información básica sobre todos los lexemas posibles en nuestro lenguaje de programación, profundicemos en el código y comencemos a declarar nuestros tipos de token. Usaremos constantes de enumeración con la expresión de patrón correspondiente para cada tipo de lexema. Usaré las anotaciones de Lombok para minimizar el código repetitivo: @RequiredArgsConstructor @Getter public enum TokenType { Whitespace("[\\s\\t\\n\\r]"), Keyword("(if|then|end|print|input|struct|arg|new)"), GroupDivider("(\\[|\\])"), Logical("true|false"), Numeric("[0-9]+"), Text("\"([^\"]*)\""), Variable("[a-zA-Z_]+[a-zA-Z0-9_]*"), Operator("(\\+|\\-|\\>|\\<|\\={1,2}|\\!|\\:{2})"); private final String regex; } Para simplificar el análisis de literales, dividí cada uno de los tipos de literales en un lexema separado: , y . Para el literal, establecemos un grupo separado para tomar el valor literal sin comillas dobles. Para los iguales, declaramos el rango . Con dos signos iguales , esperamos obtener el operador de comparación en su lugar. de la asignación Para acceder a un campo de estructura declaramos el operador de dos puntos . Numeric Logical Text Text ([^"]*) {1,2} == :: Ahora, para encontrar un token en nuestro código, simplemente iteramos y filtramos todos los valores de TokenType aplicando expresiones regulares en nuestro código fuente. Para que coincida con el comienzo de la fila, colocamos el metacarácter al comienzo de cada expresión regular creando una instancia de patrón. El token de texto capturará el valor sin comillas en el grupo separado. Por lo tanto, para acceder al valor sin comillas tomamos un valor del grupo con índice 1 si tenemos al menos un grupo explícito: ^ for (TokenType tokenType : TokenType.values()) { Pattern pattern = Pattern.compile("^" + tokenType.getRegex()); Matcher matcher = pattern.matcher(sourceCode); if (matcher.find()) { // group(1) is used to get text literal without double quotes String token = matcher.groupCount() > 0 ? matcher.group(1) : matcher.group(); } } Para almacenar los lexemas encontrados, debemos declarar la siguiente clase de Token con campos de tipo y valor: @Builder @Getter public class Token { private final TokenType type; private final String value; } Ahora tenemos todo para crear nuestro analizador léxico. Recibiremos el código fuente como una cadena en el constructor e inicializaremos la lista de tokens: public class LexicalParser { private final List<Token> tokens; private final String source; public LexicalParser(String source) { this.source = source; this.tokens = new ArrayList<>(); } ... } Para recuperar todos los tokens del código fuente, necesitamos cortar la fuente después de cada lexema encontrado. Declararemos el método que aceptará el índice actual del código fuente como argumento y tomará el siguiente token que comienza después de la posición actual: nextToken() public class LexicalParser { ... private int nextToken(int position) { String nextToken = source.substring(position); for (TokenType tokenType : TokenType.values()) { Pattern pattern = Pattern.compile("^" + tokenType.getRegex()); Matcher matcher = pattern.matcher(nextToken); if (matcher.find()) { if (tokenType != TokenType.Whitespace) { // group(1) is used to get text literal without double quotes String value = matcher.groupCount() > 0 ? matcher.group(1) : matcher.group(); Token token = Token.builder().type(tokenType).value(value).build(); tokens.add(token); } return matcher.group().length(); } } throw new TokenException(String.format("invalid expression: `%s`", nextToken)); } } Después de una captura exitosa, creamos una instancia de Token y la acumulamos en la lista de tokens. No agregaremos los lexemas de en blanco ya que solo se usan para dividir dos lexemas entre sí. Al final devolvemos la longitud del lexema encontrado. Whitespace Para capturar todos los tokens en la fuente, creamos el método con el ciclo while aumentando la posición de la fuente cada vez que capturamos un token: parse() public class LexicalParser { ... public List<Token> parse() { int position = 0; while (position < source.length()) { position += nextToken(position); } return tokens; } ... } 3 Análisis de sintaxis Dentro de nuestro modelo de compilador, el analizador de sintaxis recibirá una lista de tokens del analizador léxico y verificará si la gramática del lenguaje puede generar esta secuencia. Al final, este analizador de sintaxis debería devolver un árbol de sintaxis abstracto. Iniciaremos el analizador de sintaxis declarando la interfaz : Expression public interface Expression { } Esta interfaz se utilizará para declarar literales, variables y expresiones compuestas con operadores. 3.1 Literales En primer lugar, creamos implementaciones de para los tipos literales de nuestro lenguaje: , y con los tipos de Java correspondientes: , y . Crearemos la clase base con tipo genérico que se extiende Comparable (se usará más adelante con operadores de comparación): Expression Numeric Text Logical Integer String Boolean Value @RequiredArgsConstructor @Getter public class Value<T extends Comparable<T>> implements Expression { private final T value; @Override public String toString() { return value.toString(); } } public class NumericValue extends Value<Integer> { public NumericValue(Integer value) { super(value); } } public class TextValue extends Value<String> { public TextValue(String value) { super(value); } } public class LogicalValue extends Value<Boolean> { public LogicalValue(Boolean value) { super(value); } } También declararemos para nuestras instancias de estructura: StructureValue public class StructureValue extends Value<StructureExpression> { public StructureValue(StructureExpression value) { super(value); } } se tratará un poco más adelante. StructureExpression 3.2 Variables La expresión variable tendrá un solo campo que representa su nombre: @AllArgsConstructor @Getter public class VariableExpression implements Expression { private final String name; } 3.3 Estructuras Para almacenar una instancia de estructura, necesitaremos conocer la definición de la estructura y los valores de los argumentos que estamos pasando para crear un objeto. Los valores de los argumentos pueden significar cualquier expresión, incluidos literales, variables y expresiones más complejas que implementan la interfaz . Por lo tanto, usaremos como tipo de valores: Expression Expression @RequiredArgsConstructor @Getter public class StructureExpression implements Expression { private final StructureDefinition definition; private final List<Expression> values; } @RequiredArgsConstructor @Getter @EqualsAndHashCode(onlyExplicitlyIncluded = true) public class StructureDefinition { @EqualsAndHashCode.Include private final String name; private final List<String> arguments; } Los valores pueden ser un tipo de . Necesitamos una forma de acceder al valor de la variable por su nombre. Delegaré esta responsabilidad a la interfaz de la función, que aceptará el nombre de la variable y devolverá un objeto de : VariableExpression Value ... public class StructureExpression implements Expression { ... private final Function<String, Value<?>> variableValue; } Ahora podemos implementar una interfaz para recuperar el valor de un argumento por su nombre, se usará para acceder a los valores de instancia de la estructura. El método se implementará un poco más tarde: getValue() ... public class StructureExpression implements Expression { … public Value<?> getArgumentValue(String field) { return IntStream .range(0, values.size()) .filter(i -> definition.getArguments().get(i).equals(field)) .mapToObj(this::getValue) //will be implemented later .findFirst() .orElse(null); } } No olvide que nuestra se utiliza como parámetro para el tipo genérico que amplía Comparable. Por lo tanto, debemos implementar una interfaz comparable para nuestra expresión de : StructureExpression StructureValue StructureExpression ... public class StructureExpression implements Expression, Comparable<StructureExpression> { ... @Override public int compareTo(StructureExpression o) { for (String field : definition.getArguments()) { Value<?> value = getArgumentValue(field); Value<?> oValue = o.getArgumentValue(field); if (value == null && oValue == null) continue; if (value == null) return -1; if (oValue == null) return 1; //noinspection unchecked,rawtypes int result = ((Comparable) value.getValue()).compareTo(oValue.getValue()); if (result != 0) return result; } return 0; } } También podemos anular el método estándar. Será útil si queremos imprimir una instancia de estructura completa en la consola: toString() ... public class ObjectExpression implements Expression, Comparable<ObjectExpression> { ... @Override public String toString() { return IntStream .range(0, values.size()) .mapToObj(i -> { Value<?> value = getValue(i); //will be implemented later String fieldName = definition.getArguments().get(i); return fieldName + " = " + value; }) .collect(Collectors.joining(", ", definition.getName() + " [ ", " ]")); } } 3.4 Operadores En nuestro lenguaje tendremos operadores unarios con 1 operando y operadores binarios con 2 operandos. Implementemos la interfaz Expression para cada uno de nuestros operadores. Declaramos la interfaz y creamos implementaciones base para operadores binarios y unarios: OperatorExpression public interface OperatorExpression extends Expression { } @RequiredArgsConstructor @Getter public class UnaryOperatorExpression implements OperatorExpression { private final Expression value; } @RequiredArgsConstructor @Getter public class BinaryOperatorExpression implements OperatorExpression { private final Expression left; private final Expression right; } También necesitamos declarar un método abstracto para cada una de nuestras implementaciones de operadores con los valores correspondientes de los operandos. Este método calculará el de los operandos dependiendo de la esencia de cada operador. La transición del operando de la al se cubrirá un poco más adelante. calc() Value Expression Value … public abstract class UnaryOperatorExpression extends OperatorExpression { … public abstract Value<?> calc(Value<?> value); } … public abstract class BinaryOperatorExpression extends OperatorExpression { … public abstract Value<?> calc(Value<?> left, Value<?> right); } Después de declarar las clases de operadores base, podemos crear implementaciones más detalladas: 3.4.1 ¡NO ! Este operador solo funcionará con devolviendo la nueva instancia de con valor invertido: LogicalValue LogicalValue public class NotOperator extends UnaryOperatorExpression { ... @Override public Value<?> calc(Value<?> value) { if (value instanceof LogicalValue) { return new LogicalValue(!((LogicalValue) value.getValue()).getValue()); } else { throw new ExecutionException(String.format("Unable to perform NOT operator for non logical value `%s`", value)); } } } Ahora cambiaremos a las implementaciones de con dos operandos: BinaryOperatorExpression 3.4.2 Suma + La primera es la suma. El método hará la adición de objetos . Para los otros tipos de valor, concatenaremos los valores de String que devuelven la instancia : calc() NumericValue toString() TextValue public class AdditionOperator extends BinaryOperatorExpression { public AdditionOperator(Expression left, Expression right) { super(left, right); } @Override public Value<?> calc(Value<?> left, Value<?> right) { if (left instanceof NumericValue && right instanceof NumericValue) { return new NumericValue(((NumericValue) left).getValue() + ((NumericValue) right).getValue()); } else { return new TextValue(left.toString() + right.toString()); } } } 3.4.3 Resta - hará una comparación de solo si ambos valores tienen el tipo . En el otro caso, ambos valores se asignarán a la Cadena, eliminando las coincidencias del segundo valor del primer valor: calc() getValue() NumericValue public class SubtractionOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { if (left instanceof NumericValue && right instanceof NumericValue) { return new NumericValue(((NumericValue) left).getValue() - ((NumericValue) right).getValue()); } else { return new TextValue(left.toString().replaceAll(right.toString(), "")); } } } 3.4.4 Igual == hará una comparación de solo si ambos valores tienen el mismo tipo. En el otro caso, ambos valores se asignarán a la Cadena: calc() getValue() public class EqualsOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { boolean result; if (Objects.equals(left.getClass(), right.getClass())) { result = ((Comparable) left.getValue()).compareTo(right.getValue()) == 0; } else { result = ((Comparable) left.toString()).compareTo(right.toString()) == 0; } return new LogicalValue(result); } } 3.4.5 Menor que < y mayor que > public class LessThanOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { boolean result; if (Objects.equals(left.getClass(), right.getClass())) { result = ((Comparable) left.getValue()).compareTo(right.getValue()) < 0; } else { result = left.toString().compareTo(right.toString()) < 0; } return new LogicalValue(result); } } public class GreaterThanOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { boolean result; if (Objects.equals(left.getClass(), right.getClass())) { result = ((Comparable) left.getValue()).compareTo(right.getValue()) > 0; } else { result = left.toString().compareTo(right.toString()) > 0; } return new LogicalValue(result); } } 3.4.6 Operador de valor de estructura :: Para leer el valor de un argumento de estructura, esperamos recibir el valor de la izquierda como un tipo de valor de : StructureValue public class StructureValueOperator extends BinaryOperatorExpression { ... @Override public Value<?> calc(Value<?> left, Value<?> right) { if (left instanceof StructureValue) return ((StructureValue) left).getValue().getArgumentValue(right.toString()); return left; } } 3.5 Evaluación del valor Si queremos pasar variables o implementaciones de más complejas a los operadores, incluidos los propios operadores, necesitamos una forma de transformar el objeto en . Para hacer esto, declaramos el método de en nuestra interfaz de : Expression Expression Value evaluate() Expression public interface Expression { Value<?> evaluate(); } La clase de valor solo devolverá instancia: this public class Value<T extends Comparable<T>> implements Expression { ... @Override public Value<?> evaluate() { return this; } } Para implementar la para , primero debemos proporcionar la capacidad de obtener por el nombre de la variable. Delegamos este trabajo al campo que aceptará el nombre de la variable y devolverá el objeto correspondiente: evaluate() VariableExpression Value Function Value ... public class VariableExpression implements Expression { ... private final Function<String, Value<?>> variableValue; @Override public Value<?> evaluate() { Value<?> value = variableValue.apply(name); if (value == null) { return new TextValue(name); } return value; } } Para evaluar , crearemos una instancia de . También necesitamos implementar el método faltante que aceptará un índice de argumento y devolverá un valor según el tipo de : StructureExpression StructureValue getValue() Expression ... public class StructureExpression implements Expression, Comparable<StructureExpression> { ... @Override public Value<?> evaluate() { return new StructureValue(this); } private Value<?> getValue(int index) { Expression expression = values.get(index); if (expression instanceof VariableExpression) { return variableValue.apply(((VariableExpression) expression).getName()); } else { return expression.evaluate(); } } } Para las expresiones de operador, evaluamos los valores de los operandos y los pasamos al método : calc() public abstract class UnaryOperatorExpression extends OperatorExpression { ... @Override public Value<?> evaluate() { return calc(getValue().evaluate()); } } public abstract class BinaryOperatorExpression extends OperatorExpression { ... @Override public Value<?> evaluate() { return calc(getLeft().evaluate(), getRight().evaluate()); } } 3.6 Declaraciones Antes de comenzar a crear nuestro analizador de sintaxis, debemos presentar un modelo para las declaraciones de nuestro lenguaje. Comencemos con la interfaz de con el método de procedimiento de que se llamará durante la ejecución del código: Statement execute() public interface Statement { void execute(); } 3.6.1 Imprimir declaración La primera declaración que implementaremos es . Esta declaración necesita saber la expresión para imprimir. Nuestro lenguaje admitirá la impresión de literales, variables y otras expresiones implementando que se evaluará durante la ejecución para calcular el objeto : PrintStatement Expression Value @AllArgsConstructor @Getter public class PrintStatement implements Statement { private final Expression expression; @Override public void execute() { Value<?> value = expression.evaluate(); System.out.println(value); } } 3.6.2 Sentencia de asignación Para declarar una asignación necesitamos saber el nombre de la variable y la expresión que queremos asignar. Nuestro lenguaje podrá asignar literales, variables y expresiones más complejas implementando la interfaz : Expression @AllArgsConstructor @Getter public class AssignStatement implements Statement { private final String name; private final Expression expression; @Override public void execute() { ... } } Durante la ejecución, necesitamos almacenar los valores de las variables en algún lugar. Deleguemos esta lógica al campo que pasará un nombre de variable y el valor asignado. Tenga en cuenta que el valor de debe evaluarse al realizar una tarea: BiConsumer Expression ... public class AssignStatement implements Statement { ... private final BiConsumer<String, Value<?>> variableSetter; @Override public void execute() { variableSetter.accept(name, expression.evaluate()); } } 3.6.3 Declaración de entrada Para leer una expresión desde la consola, necesitamos saber el nombre de la variable para asignarle un valor. Durante la debemos leer una línea desde la consola. Este trabajo se puede delegar al , por lo que no crearemos múltiples flujos de entrada. Después de leer la línea, la analizamos en el objeto correspondiente y delegamos la asignación a la instancia de como lo hicimos para : execute() Supplier Value BiConsumer AssignStatement @AllArgsConstructor @Getter public class InputStatement implements Statement { private final String name; private final Supplier<String> consoleSupplier; private final BiConsumer<String, Value<?>> variableSetter; @Override public void execute() { //just a way to tell the user in which variable the entered value will be assigned System.out.printf("enter \"%s\" >>> ", name.replace("_", " ")); String line = consoleSupplier.get(); Value<?> value; if (line.matches("[0-9]+")) { value = new NumericValue(Integer.parseInt(line)); } else if (line.matches("true|false")) { value = new LogicalValue(Boolean.valueOf(line)); } else { value = new TextValue(line); } variableSetter.accept(name, value); } } 3.6.4 Declaración de condición Primero, presentaremos la clase que contendrá una lista interna de declaraciones para ejecutar: CompositeStatement @Getter public class CompositeStatement implements Statement { private final List<Statement> statements2Execute = new ArrayList<>(); public void addStatement(Statement statement) { if (statement != null) statements2Execute.add(statement); } @Override public void execute() { statements2Execute.forEach(Statement::execute); } } Esta clase se puede reutilizar más tarde en caso de que creemos una construcción de sentencias compuestas. La primera de las construcciones será la declaración de . Para describir la condición podemos usar literales, variables y construcciones más complejas implementando la interfaz . Al final, durante la ejecución, calculamos el valor de la y nos aseguramos de que el valor sea Lógico y que el resultado interno sea verdadero. Solo en este caso podemos realizar sentencias internas: Condition Expression Expression @RequiredArgsConstructor @Getter public class ConditionStatement extends CompositeStatement { private final Expression condition; @Override public void execute() { Value<?> value = condition.evaluate(); if (value instanceof LogicalValue) { if (((LogicalValue) value).getValue()) { super.execute(); } } else { throw new ExecutionException(String.format("Cannot compare non logical value `%s`", value)); } } } 3.7 Analizador de declaraciones Ahora que tenemos las declaraciones para trabajar con nuestros lexemas, ahora podemos construir el . Dentro de la clase declaramos una lista de tokens y variables de posición de tokens mutables: StatementParser public class StatementParser { private final List<Token> tokens; private int position; public StatementParser(List<Token> tokens) { this.tokens = tokens; } ... } Luego creamos el método que manejará los tokens proporcionados y devolverá una declaración completa: parseExpression() public Statement parseExpression() { ... } Las expresiones de nuestro lenguaje solo pueden comenzar declarando una variable o una palabra clave. Por lo tanto, primero necesitamos leer un token y validar que tenga el tipo de token o . Para manejar esto, declaramos un método next() separado con tipos de token varargs como argumento que validará que el próximo token tenga el mismo tipo. En el caso real, incrementamos el campo de posición de y devolvemos el token encontrado: Variable Keyword StatementParser private Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable); ... } private Token next(TokenType type, TokenType... types) { TokenType[] tokenTypes = org.apache.commons.lang3.ArrayUtils.add(types, type); if (position < tokens.size()) { Token token = tokens.get(position); if (Stream.of(tokenTypes).anyMatch(t -> t == token.getType())) { position++; return token; } } Token previousToken = tokens.get(position - 1); throw new SyntaxException(String.format("After `%s` declaration expected any of the following lexemes `%s`", previousToken, Arrays.toString(tokenTypes))); } Una vez que hayamos encontrado el token apropiado, podemos construir nuestra declaración según el tipo de token. 3.7.1 Variables Cada asignación de variable comienza con el tipo de token , que ya leímos. El siguiente token que esperamos es el operador equals . Puede anular el método next() que aceptará con la representación del operador String (por ejemplo, ) y devolverá el siguiente token encontrado solo si tiene el mismo tipo y valor que el solicitado: Variable = TokenType = public Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable); switch (token.getType()) { case Variable: next(TokenType.Operator, "="); //skip equals Expression value; if (peek(TokenType.Keyword, "new")) { value = readInstance(); } else { value = readExpression(); } return new AssignStatement(token.getValue(), value, variables::put); } ... } Después del operador igual, leemos una expresión. Una expresión puede comenzar con la palabra clave cuando instanciamos una estructura. Cubriremos este caso un poco más adelante. Para consumir un token con la intención de validar su valor sin incrementar la posición y arrojar un error, crearemos un método adicional que devolverá el valor verdadero si el próximo token es el mismo que esperamos: new peek() ... private boolean peek(TokenType type, String value) { if (position < tokens.size()) { Token token = tokens.get(position); return type == token.getType() && token.getValue().equals(value); } return false; } ... Para crear una instancia de necesitamos pasar un objeto al constructor. Vayamos a la de campos de StatementParser y agreguemos un nuevo campo de variables de mapa que almacenará el nombre de la variable como una clave y el valor de la variable como un valor: AssignStatement BiConsumer StatementParser public class StatementParser { ... private final Map<String, Value<?>> variables; public StatementParser(List<Token> tokens) { ... this.variables = new HashMap<>(); } ... } expresión variable Primero, cubriremos la lectura de expresión de variable simple que puede ser un literal, otra variable o una expresión más compleja con operadores. Por lo tanto, el método devolverá la con las implementaciones correspondientes. Dentro de este método, declaramos la instancia de izquierda. Una expresión puede comenzar solo con un literal o con otra variable. Por lo tanto, esperamos obtener el tipo de token , , o de nuestro método . Después de leer un token adecuado, lo transformamos en el objeto Expression apropiado dentro del siguiente bloque de interruptores y lo asignamos a la variable de la izquierda: readExpression() Expression Expression Variable Numeric Logical Text next() Expression private Expression readExpression() { Expression left; Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text); String value = token.getValue(); switch (token.getType()) { case Numeric: left = new NumericValue(Integer.parseInt(value)); case Logical: left = new LogicalValue(Boolean.valueOf(value)); case Text: left = new TextValue(value); case Variable: default: left = new VariableExpression(value, variables::get); } ... } Después de leer la variable izquierda o el literal, esperamos capturar un lexema de : Operator private Expression readExpression() { Expression left; Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text); String value = token.getValue(); switch (token.getType()) { ... } Token operation = next(TokenType.Operator); Class<? extends OperatorExpression> operatorType = Operator.getType(operation.getValue()); ... } Luego mapeamos nuestro lexema de al objeto . Para hacerlo, puede usar un bloque de cambio que devuelva la clase adecuada según el valor del token. Usaré constantes de enumeración con un tipo de expresión de apropiado: Operator OperatorExpression OperatorExpression OperatorExpression @RequiredArgsConstructor @Getter public enum Operator { Not("!", NotOperator.class), Addition("+", AdditionOperator.class), Subtraction("-", SubtractionOperator.class), Equality("==", EqualsOperator.class), GreaterThan(">", GreaterThanOperator.class), LessThan("<", LessThanOperator.class), StructureValue("::", StructureValueOperator.class); private final String character; private final Class<? extends OperatorExpression> operatorType; public static Class<? extends OperatorExpression> getType(String character) { return Arrays.stream(values()) .filter(t -> Objects.equals(t.getCharacter(), character)) .map(Operator::getOperatorType) .findAny().orElse(null); } } Al final, leemos el literal o la variable de la derecha como lo hicimos con la de la izquierda. Para no duplicar el código, extraemos la de lectura en un método separado: Expression Expression nextExpression() private Expression nextExpression() { Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text); String value = token.getValue(); switch (token.getType()) { case Numeric: return new NumericValue(Integer.parseInt(value)); case Logical: return new LogicalValue(Boolean.valueOf(value)); case Text: return new TextValue(value); case Variable: default: return new VariableExpression(value, variables::get); } } Refactoricemos el método y leamos el lexema correcto usando . Pero antes de leer el lexema correcto, debemos estar seguros de que nuestro operador admite dos operandos. Podemos verificar si nuestro operador extiende . En el otro caso, si el operador es unario, creamos un solo usando la expresión de la izquierda. Para crear un objeto , recuperamos el constructor adecuado para la implementación del operador unario o binario y luego creamos una instancia con las expresiones anteriores obtenidas: readExpression() nextExpression() BinaryOperatorExpression OperatorExpression OperatorExpression @SneakyThrows private Expression readExpression() { Expression left = nextExpression(); Token operation = next(TokenType.Operator); Class<? extends OperatorExpression> operatorType = Operator.getType(operation.getValue()); if (BinaryOperatorExpression.class.isAssignableFrom(operatorType)) { Expression right = nextExpression(); return operatorType .getConstructor(Expression.class, Expression.class) .newInstance(left, right); } else if (UnaryOperatorExpression.class.isAssignableFrom(operatorType)) { return operatorType .getConstructor(Expression.class) .newInstance(left); } return left; } Además, podemos brindar la oportunidad de crear una expresión larga con múltiples operadores o sin operadores con solo un literal o variable. Incluyamos la operación read en el bucle while con la condición de que tengamos un Operador como el siguiente lexema. Cada vez que creamos una expresión de , la asignamos a la expresión de la izquierda, creando así un árbol de operadores posteriores dentro de una hasta que leemos la expresión completa. Al final devolvemos la expresión de la izquierda: OperatorExpression Expression @SneakyThrows private Expression readExpression() { Expression left = nextExpression(); //recursively read an expression while (peek(TokenType.Operator)) { Token operation = next(TokenType.Operator); Class<? extends OperatorExpression> operatorType = Operator.getType(operation.getValue()); if (BinaryOperatorExpression.class.isAssignableFrom(operatorType)) { Expression right = nextExpression(); left = operatorType .getConstructor(Expression.class, Expression.class) .newInstance(left, right); } else if (UnaryOperatorExpression.class.isAssignableFrom(operatorType)) { left = operatorType .getConstructor(Expression.class) .newInstance(left); } } return left; } private boolean peek(TokenType type) { if (position < tokens.size()) { Token token = tokens.get(position); return token.getType() == type; } return false; } Instancia de estructura Después de completar la implementación de , podemos volver a y finalizar la implementación de para instanciar una instancia de estructura: readExpression() parseExpression() readInstance() De acuerdo con la semántica de nuestro lenguaje, sabemos que la creación de instancias de nuestra estructura comienza con la palabra clave, podemos omitir el siguiente token llamando al método . El siguiente lexema significará el nombre de la estructura, lo leemos como el tipo de token . Después del nombre de la estructura, esperamos recibir argumentos entre corchetes como divisores de grupo. En algunos casos, nuestra estructura se puede crear sin ningún tipo de argumento. Por lo tanto, usamos primero. Cada argumento que se pasa a la estructura puede significar una expresión, por lo que llamamos a y pasamos el resultado a la lista de argumentos. Después de construir argumentos de estructura, podemos construir nuestra preliminarmente recuperando la apropiada: new next() Variable peek() readExpression() StructureExpression StructureDefinition private Expression readInstance() { next(TokenType.Keyword, "new"); //skip new Token type = next(TokenType.Variable); List<Expression> arguments = new ArrayList<>(); if (peek(TokenType.GroupDivider, "[")) { next(TokenType.GroupDivider, "["); //skip open square bracket while (!peek(TokenType.GroupDivider, "]")) { Expression value = readExpression(); arguments.add(value); } next(TokenType.GroupDivider, "]"); //skip close square bracket } StructureDefinition definition = structures.get(type.getValue()); if (definition == null) { throw new SyntaxException(String.format("Structure is not defined: %s", type.getValue())); } return new StructureExpression(definition, arguments, variables::get); } Para recuperar la definición de por nombre, debemos declarar el mapa de estructuras como el campo de , lo completaremos más tarde durante el análisis de palabras clave de : StructureDefinition StatementParser struct public class StatementParser { ... private final Map<String, StructureDefinition> structures; public StatementParser(List<Token> tokens) { ... this.structures = new HashMap<>(); } ... } 3.7.2 Palabra clave Ahora podemos continuar trabajando en el método cuando recibamos el lexema de la : parseExpression() Keyword public Statement parseExpression() { ... switch (token.getType()) { case Variable: ... case Keyword: switch (token.getValue()) { case "print": case "input": case "if": case "struct": } ... } } Nuestra expresión de lenguaje puede comenzar con las palabras clave , , y . print input if struct Impresión Para leer el valor de impresión, llamamos al método ya creado. Leerá una implementación de literal, variable o más compleja como lo hicimos para la asignación de variables. Luego creamos y devolvemos una instancia de : readExpression() Expression PrintStatement ... case "print": Expression expression = readExpression(); return new PrintStatement(expression); ... Aporte Para la declaración de entrada, necesitamos saber el nombre de la variable al que asignamos valor. Por lo tanto, le pedimos al método que capture el siguiente token de por nosotros: next() Variable ... case "input": Token variable = next(TokenType.Variable); return new InputStatement(variable.getValue(), scanner::nextLine, variables::put); ... Para crear una instancia de introducimos un objeto en la de campos de StatementParser que nos ayudará a leer una línea desde la consola: InputStatement Scanner StatementParser public class StatementParser { ... private final Scanner scanner; public StatementParser(List<Token> tokens) { ... this.scanner = new Scanner(System.in); } ... } Si La siguiente declaración que tocaremos es la condición : if/then En primer lugar, cuando recibimos la palabra clave , leemos la expresión de la condición llamando a . Luego, de acuerdo con la semántica de nuestro lenguaje, necesitamos captar la palabra clave . Dentro de nuestra condición podemos declarar otras declaraciones, incluidas otras declaraciones de condición. Por lo tanto, agregamos recursivamente a las declaraciones internas de la condición hasta que leamos la palabra clave : if readExpression() then parseExpression() end ... case "if": Expression condition = readExpression(); next(TokenType.Keyword, "then"); //skip then ConditionStatement conditionStatement = new ConditionStatement(condition); while (!peek(TokenType.Keyword, "end")) { Statement statement = parseExpression(); conditionStatement.addStatement(statement); } next(TokenType.Keyword, "end"); //skip end return conditionStatement; ... estructura La declaración de estructura es bastante simple porque consta solo de tipos de token y . Después de leer la palabra clave , esperamos leer el nombre de la estructura como tipo de token . Luego leemos los argumentos hasta que terminamos con la palabra clave . Al final, construimos nuestra definición de y la colocamos en el mapa de estructuras para acceder a ella en el futuro cuando creemos una instancia de estructura: Variable Keyword struct Variable end StructureDefinition ... case "struct": Token type = next(TokenType.Variable); Set<String> args = new HashSet<>(); while (!peek(TokenType.Keyword, "end")) { next(TokenType.Keyword, "arg"); Token arg = next(TokenType.Variable); args.add(arg.getValue()); } next(TokenType.Keyword, "end"); //skip end structures.put(type.getValue(), new StructureDefinition(type.getValue(), new ArrayList<>(args))); return null; ... El método completo: parseExpression() ... public Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable); switch (token.getType()) { case Variable: next(TokenType.Operator, "="); //skip equals Expression value; if (peek(TokenType.Keyword, "new")) { value = readInstance(); } else { value = readExpression(); } return new AssignStatement(token.getValue(), value, variables::put); case Keyword: switch (token.getValue()) { case "print": Expression expression = readExpression(); return new PrintStatement(expression); case "input": Token variable = next(TokenType.Variable); return new InputStatement(variable.getValue(), scanner::nextLine, variables::put); case "if": Expression condition = readExpression(); next(TokenType.Keyword, "then"); //skip then ConditionStatement conditionStatement = new ConditionStatement(condition); while (!peek(TokenType.Keyword, "end")) { Statement statement = parseExpression(); conditionStatement.addStatement(statement); } next(TokenType.Keyword, "end"); //skip end return conditionStatement; case "struct": Token type = next(TokenType.Variable); Set<String> args = new HashSet<>(); while (!peek(TokenType.Keyword, "end")) { next(TokenType.Keyword, "arg"); Token arg = next(TokenType.Variable); args.add(arg.getValue()); } next(TokenType.Keyword, "end"); //skip end structures.put(type.getValue(), new StructureDefinition(type.getValue(), new ArrayList<>(args))); return null; } default: throw new SyntaxException(String.format("Statement can't start with the following lexeme `%s`", token)); } } ... Para encontrar y acumular todas las declaraciones, creamos el método que analizará todas las expresiones de los tokens dados y devolverá la instancia de : parse() CompositeStatement ... public Statement parse() { CompositeStatement root = new CompositeStatement(); while (position < tokens.size()) { Statement statement = parseExpression(); root.addStatement(statement); } return root; } ... 4 Idioma del juguete Terminamos con el analizador léxico y sintáctico. Ahora podemos reunir ambas implementaciones en la clase y finalmente ejecutar nuestro lenguaje: ToyLanguage public class ToyLanguage { @SneakyThrows public void execute(Path path) { String source = Files.readString(path); LexicalParser lexicalParser = new LexicalParser(source); List<Token> tokens = lexicalParser.parse(); StatementParser statementParser = new StatementParser(tokens); Statement statement = statementParser.parse(); statement.execute(); } } 5 Resumiendo En este tutorial, construimos nuestro propio lenguaje con análisis léxico y sintáctico. Espero que este artículo sea útil para alguien. Le recomiendo que intente escribir su propio idioma, a pesar de que debe comprender muchos detalles de implementación. ¡Este es un experimento interesante, de aprendizaje y de superación personal!