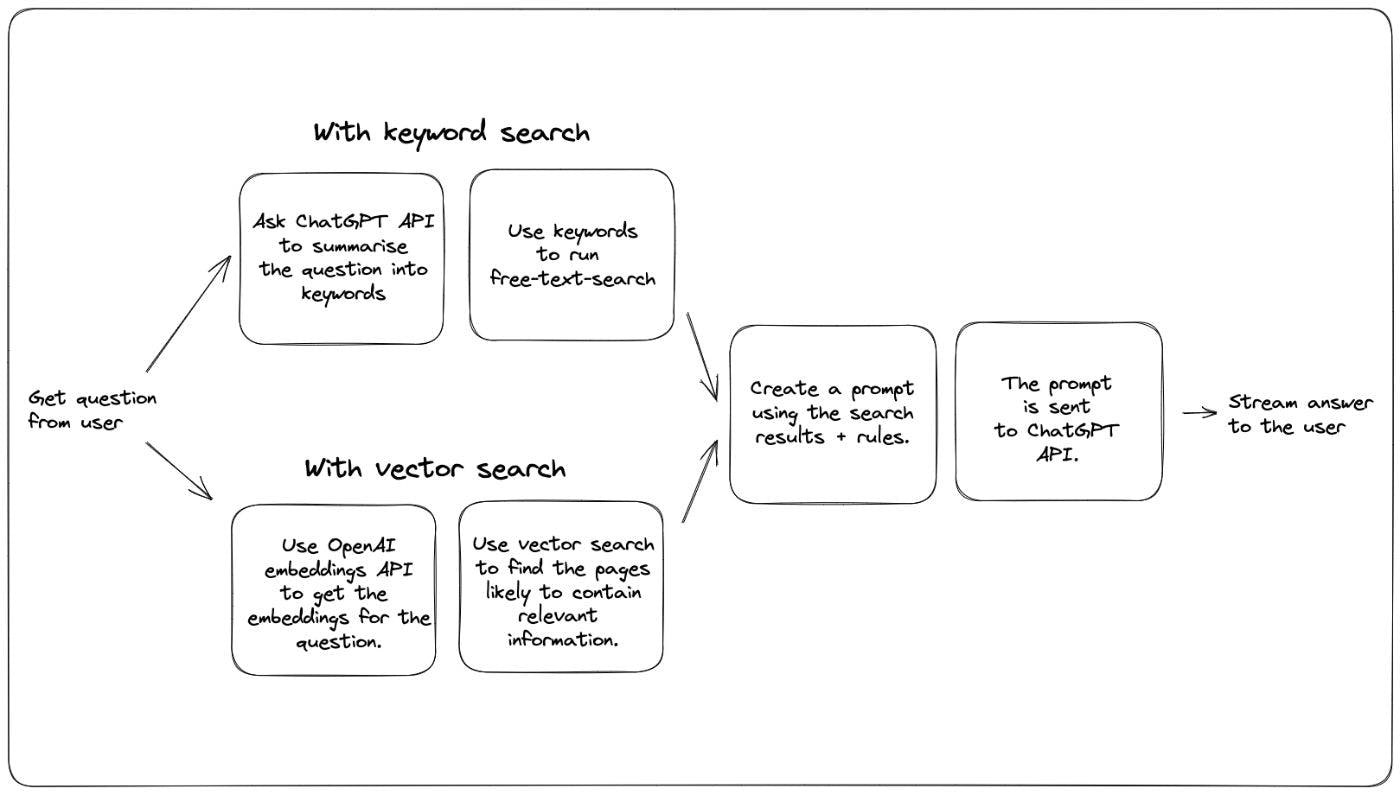
Last week we’ve added a Q&A bot that answers questions from . This leverages the ChatGPT tech to answer questions from the Xata documentation, even though the OpenAI GPT model was never trained on the Xata docs. our documentation The way we do this is by using an approach suggested by Simon Willison in this . The same approach can be found also in an . The idea is the following: blog post OpenAI cookbook Run a text search against the documentation to find the content that is most relevant to the question asked by the user. Produce a prompt with this general form: With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: Send the prompt to the ChatGPT API and let the model complete the answer. We found out that this works quite well and, combined with a relatively low model temperature (the concept of temperature is explained in this ), this tends to produce correct results and code snippets, as long as the answer can be found in the documentation. blog post A key limitation to this approach is that the prompt that you build in the second step above needs to have max 4000 tokens (~3000 words). This means that the first step, the text search to select the most relevant documents, becomes really important. If the search step does a good job and provides the right context, ChatGPT tends to also do a good job in producing a correct and to-the-point result. So what’s the best way to find the most relevant pieces of content in the documentation? The OpenAI cookbook, as well as Simon’s blog, use what is called semantic search. Semantic search leverages the language model to generate embeddings for both the question and the content. Embeddings are arrays of numbers that represent the text on a number of dimension. Pieces of text that have similar embeddings have a similar meaning. This means a good strategy is to find the pieces of content that the most similar embeddings to the question embeddings. Another possible strategy, based on the more classical keyword search, looks like this: Ask ChatGPT to extract the keywords from the question, with a prompt like this: Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. Use the provided keywords to run a free-text-search and pick the top results Putting it in a single diagram, the two methods look like this: We have tried both on our documentation and have noticed some pros and cons. Let’s start by comparing a few results. Both are ran against the same database, and they both use the ChatGPT model. As there is randomness involved, I ran each question 2-3 times and picked what looked to me like the best result. gpt-3.5-turbo Question: How do I install the Xata CLI? Answer with vector search: Answer with keyword search: : Both versions provided the correct answer, however the vector search one is a bit more complete. They both found the correct docs page for it, but I think our highlights-based heuristic selected a shorter chunk of text in case of the keyword strategy. Verdict Winner: vector search. Score: 1-0 Question: How do you use Xata with Deno? Answer with vector search: Answer with keyword search: Disappointing result for vector search, who somehow missed the dedicated Deno page in our docs. It did find some other Deno relevant content, but not the page that contained the very useful example. Verdict: Winner: keyword search. Score: 1-1 Question: How can I import a CSV file with custom column types? With vector search: With keyword search: Both have found the right page (”Import a CSV file”), but the keyword search version managed to get a more complete answer. I did run this multiple times to make sure it’s not a fluke. I think the difference comes from how the text fragment is selected (neighbouring the keywords in case of keyword search, from the beginning of the page in case of vector search). Verdict: Winner: keyword search. Score: 1-2 Question: How can I filter a table named Users by the email column? With vector search: With keyword search: The vector search did better on this one, because it found the “Filtering” page on which there were more examples that ChatGPT could use to compose the answer. The keyword search answer is subtly broken, because it uses “query” instead of “filter” for the method name. Verdict: Winner: vector search. Score: 2-2 Question: What is Xata? With vector search: With keyword search: This one is a draw, because both answers are quite good. The two picked different pages to summarize in an answer, but both did a good job and I can’t pick a winner. Verdict: Score: 3-3 Configuration and tuning This is a sample Xata request used for keyword search: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } And this what we use for vector search: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } As you can see, the keyword search version has more settings, configuring fuzziness and boosters and column weights. The vector search only uses a filter. I would call this a plus for keyword search: you have more dials to tune the search and therefore get better answers. But it’s also more work, and the results from vector search are quite good without this tuning. In our case, we already have tuned the keyword search for our, well, docs search functionality. So it wasn’t necessarily extra work, and while playing with ChatGPT we discovered improvements to our docs and search as well. Also, Xata just happens to have a very nice UI for tuning your keyword search, so the work wasn’t hard to begin with (planning a separate blog post about that). There is no reason for which vector search couldn’t also have boosters and column weights and the like, but we don’t have it yet in Xata and I don’t know of any other solution that makes that as easy as we make keyword search tuning. And, in general, there is more prior art to keyword search, but it is quite possible that vector search will catch up. For now, I’m going to call keyword search the winner Score: 3-4 Convenience Our documentation already had a search function, dog-fooding Xata, so that was quite simple to extend to a chat bot. Xata now also supports vector search natively, but using it required adding embeddings for all the documentation pages and figuring out a good chunking strategy. We have used the OpenAI embeddings API for producing the text embeddings, which had a minimal cost. Winner: Keyword search Score 3-5 Latency The keyword search approach needs an extra round-trip to the ChatGPT API. This adds in terms of latency to the result started to be streamed in the UI. By my measurements, this adds around 1.8s extra time. With vector search: With keyword search: The total and the content download times here are not relevant, because they mostly depend on how long the generated response is. Look at the “Waiting for server response” bar (the green one) to compare. Note: Winner: Vector search Score: 4-5 Cost The keyword search version needs to do an extra API call to the ChatGPT API, on the other hand, the vector search version needs to produce embeddings for all the documents in the database plus the question. Unless we’re talking about a lot of documents, I’m going to call this a tie. Score: 5-6 Conclusion The score is tight! In our case we have gone with using the keyword search for now, mostly because we have more ways of tuning it and as a result of that it generates slightly better answers for our set of test questions. Also, any improvements that we make to search automatically benefit both the search and the chat use cases. As we’re improving our vector search capabilities with more tuning options, we might switch to vector search, or a hybrid approach, in the future. If you’d like to set up a similar chat bot for your own documentation, or any kind of knowledge base, you can easily implement the above using the Xata ask endpoint. for free and join us on . I’d be happy to personally help you get it up and running! Create an account Discord