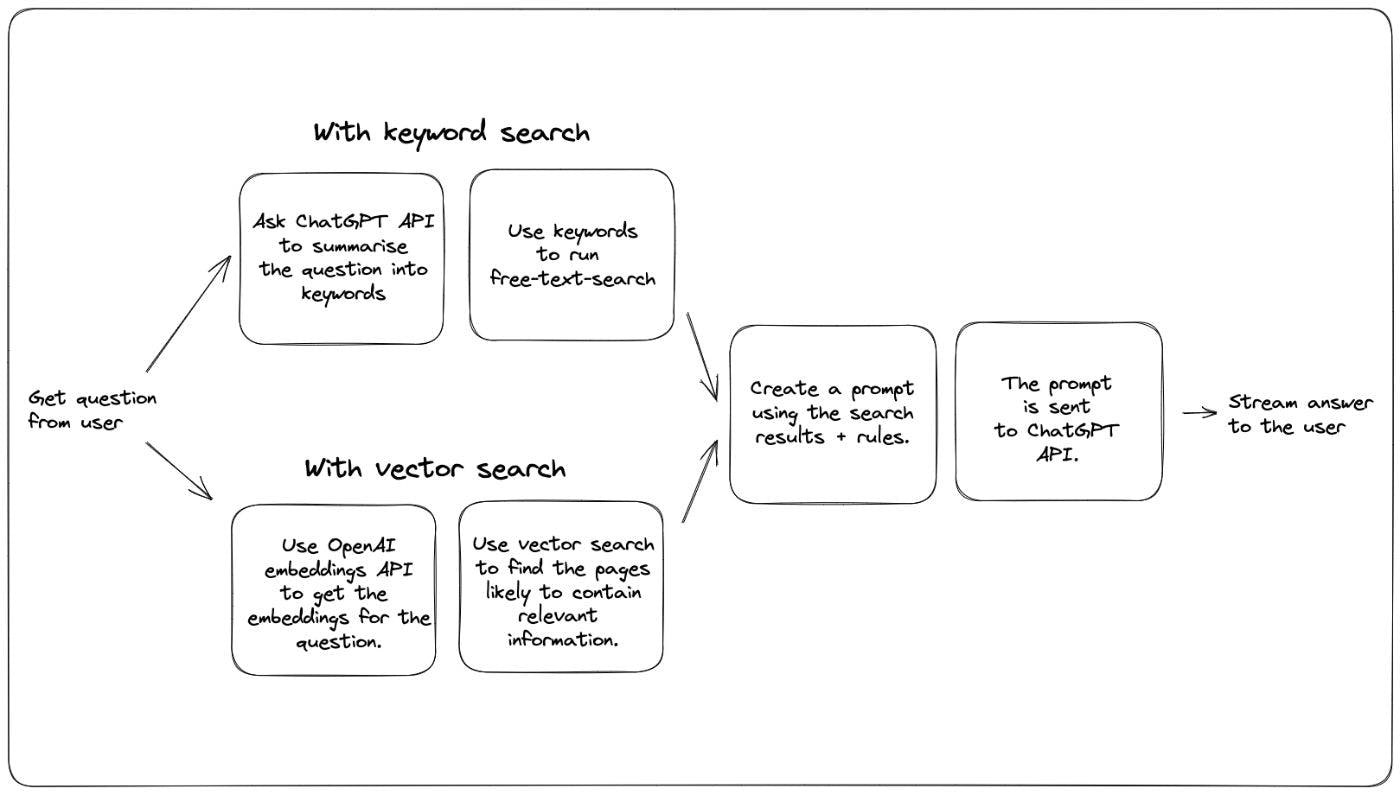
पिछले सप्ताह हमने एक क्यू एंड ए बॉट जोड़ा है जो से प्रश्नों का उत्तर देता है। यह Xata प्रलेखन से सवालों के जवाब देने के लिए ChatGPT तकनीक का लाभ उठाता है, भले ही OpenAI GPT मॉडल को Xata डॉक्स पर कभी प्रशिक्षित नहीं किया गया था। हमारे दस्तावेज़ीकरण इस में साइमन विलिसन द्वारा सुझाए गए दृष्टिकोण का उपयोग करके हम ऐसा करते हैं। यही दृष्टिकोण में भी पाया जा सकता है। विचार निम्नलिखित है: ब्लॉग पोस्ट OpenAI कुकबुक उपयोगकर्ता द्वारा पूछे गए प्रश्न के लिए सबसे अधिक प्रासंगिक सामग्री खोजने के लिए दस्तावेज़ीकरण के विरुद्ध एक पाठ खोज चलाएँ। इस सामान्य रूप के साथ एक संकेत उत्पन्न करें: With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: चैटजीपीटी एपीआई को संकेत भेजें और मॉडल को उत्तर पूरा करने दें। हमें पता चला कि यह काफी अच्छी तरह से काम करता है और अपेक्षाकृत कम मॉडल तापमान (तापमान की अवधारणा को इस में समझाया गया है) के साथ मिलकर, यह सही परिणाम और कोड स्निपेट का उत्पादन करता है, जब तक उत्तर में पाया जा सकता है प्रलेखन। ब्लॉग पोस्ट इस दृष्टिकोण की एक प्रमुख सीमा यह है कि आप ऊपर दिए गए दूसरे चरण में जो संकेत बनाते हैं, उसमें अधिकतम 4000 टोकन (~3000 शब्द) होने चाहिए। इसका मतलब यह है कि पहला चरण, सबसे अधिक प्रासंगिक दस्तावेज़ों का चयन करने के लिए पाठ खोज, वास्तव में महत्वपूर्ण हो जाता है। यदि खोज कदम अच्छा काम करता है और सही संदर्भ प्रदान करता है, तो चैटजीपीटी एक सही और सटीक परिणाम देने में भी अच्छा काम करता है। तो प्रलेखन में सामग्री के सबसे प्रासंगिक टुकड़े खोजने का सबसे अच्छा तरीका क्या है? OpenAI रसोई की किताब, साथ ही साइमन का ब्लॉग, शब्दार्थ खोज का उपयोग करता है। शब्दार्थ खोज प्रश्न और सामग्री दोनों के लिए एम्बेडिंग उत्पन्न करने के लिए भाषा मॉडल का लाभ उठाती है। एंबेडिंग संख्याओं की सरणियाँ हैं जो कई आयामों पर पाठ का प्रतिनिधित्व करती हैं। समान एम्बेडिंग वाले पाठ के अंशों का एक समान अर्थ होता है। इसका मतलब यह है कि एक अच्छी रणनीति सामग्री के उन हिस्सों को ढूंढना है जो प्रश्न एम्बेडिंग के सबसे समान हैं। एक और संभावित रणनीति, अधिक शास्त्रीय खोजशब्द खोज पर आधारित, इस तरह दिखती है: इस तरह के संकेत के साथ ChatGPT को प्रश्न से कीवर्ड निकालने के लिए कहें: Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. मुफ़्त-पाठ-खोज चलाने और शीर्ष परिणाम चुनने के लिए दिए गए कीवर्ड का उपयोग करें इसे एक आरेख में रखकर, दो विधियां इस तरह दिखती हैं: हमने अपने दस्तावेज़ीकरण पर दोनों का प्रयास किया है और कुछ पेशेवरों और विपक्षों पर ध्यान दिया है। आइए कुछ परिणामों की तुलना करके प्रारंभ करें। दोनों एक ही डेटाबेस के विरुद्ध चल रहे हैं, और वे दोनों ChatGPT मॉडल का उपयोग करते हैं। जैसा कि इसमें यादृच्छिकता शामिल है, मैंने प्रत्येक प्रश्न को 2-3 बार चलाया और जो मुझे सबसे अच्छा परिणाम लगा, उसे चुना। gpt-3.5-turbo प्रश्न: मैं Xata CLI कैसे स्थापित करूं? सदिश खोज के साथ उत्तर दें: कीवर्ड खोज के साथ उत्तर दें: : दोनों संस्करणों ने सही उत्तर प्रदान किया, हालांकि वेक्टर खोज थोड़ी अधिक पूर्ण है। उन दोनों को इसके लिए सही डॉक्स पेज मिला, लेकिन मुझे लगता है कि कीवर्ड रणनीति के मामले में हमारे हाइलाइट्स-आधारित ह्यूरिस्टिक ने टेक्स्ट का एक छोटा हिस्सा चुना है। फैसला विजेता: वेक्टर खोज। स्कोर: 1-0 सवाल: आप Xata को Deno के साथ कैसे इस्तेमाल करते हैं? सदिश खोज के साथ उत्तर दें: कीवर्ड खोज के साथ उत्तर दें: वेक्टर खोज के लिए निराशाजनक परिणाम, जो किसी तरह हमारे डॉक्स में समर्पित डेनो पेज से चूक गए। इसे कुछ अन्य डेनो प्रासंगिक सामग्री मिली, लेकिन वह पृष्ठ नहीं मिला जिसमें बहुत उपयोगी उदाहरण था। फैसला: विजेता: कीवर्ड खोज। स्कोर: 1-1 प्रश्न: मैं कस्टम कॉलम प्रकारों वाली CSV फ़ाइल कैसे आयात कर सकता हूँ? सदिश खोज के साथ: कीवर्ड खोज के साथ: दोनों को सही पृष्ठ मिला है ("एक CSV फ़ाइल आयात करें"), लेकिन कीवर्ड खोज संस्करण अधिक पूर्ण उत्तर प्राप्त करने में कामयाब रहा। मैंने यह सुनिश्चित करने के लिए इसे कई बार चलाया कि यह अस्थायी नहीं है। मुझे लगता है कि अंतर इस बात से आता है कि टेक्स्ट खंड का चयन कैसे किया जाता है (कीवर्ड खोज के मामले में पृष्ठ की शुरुआत से, कीवर्ड खोज के मामले में कीवर्ड पड़ोसी)। फैसला: विजेता: कीवर्ड खोज। स्कोर: 1-2 प्रश्न: मैं ईमेल कॉलम द्वारा उपयोगकर्ता नाम की तालिका को कैसे फ़िल्टर कर सकता हूँ? सदिश खोज के साथ: कीवर्ड खोज के साथ: सदिश खोज ने इस पर बेहतर प्रदर्शन किया, क्योंकि इसे "फ़िल्टरिंग" पृष्ठ मिला, जिस पर ऐसे और भी उदाहरण थे जिनका उपयोग ChatGPT उत्तर लिखने के लिए कर सकता था। कीवर्ड खोज उत्तर सूक्ष्म रूप से टूटा हुआ है, क्योंकि यह विधि नाम के लिए "फ़िल्टर" के बजाय "क्वेरी" का उपयोग करता है। निर्णय: विजेता: वेक्टर खोज। स्कोर: 2-2 प्रश्न: Xata क्या है? सदिश खोज के साथ: कीवर्ड खोज के साथ: यह एक ड्रॉ है, क्योंकि दोनों उत्तर काफी अच्छे हैं। दोनों ने एक उत्तर को सारांशित करने के लिए अलग-अलग पृष्ठ चुने, लेकिन दोनों ने अच्छा काम किया और मैं विजेता नहीं चुन सकता। फैसला: स्कोर: 3-3 विन्यास और ट्यूनिंग यह एक नमूना Xata अनुरोध है जिसका उपयोग कीवर्ड खोज के लिए किया गया है: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } और वेक्टर खोज के लिए हम इसका उपयोग करते हैं: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } जैसा कि आप देख सकते हैं, कीवर्ड खोज संस्करण में अधिक सेटिंग्स हैं, अस्पष्टता और बूस्टर और कॉलम वेट को कॉन्फ़िगर करना। वेक्टर खोज केवल फ़िल्टर का उपयोग करती है। मैं इसे कीवर्ड खोज के लिए एक प्लस कहूंगा: आपके पास खोज को ट्यून करने के लिए और अधिक डायल हैं और इसलिए बेहतर उत्तर प्राप्त करें। लेकिन यह और भी काम है, और इस ट्यूनिंग के बिना वेक्टर खोज के परिणाम काफी अच्छे हैं। हमारे मामले में, हमने अपने डॉक्स खोज कार्यक्षमता के लिए पहले से ही कीवर्ड खोज को ट्यून कर लिया है। इसलिए यह आवश्यक रूप से अतिरिक्त काम नहीं था, और चैटजीपीटी के साथ खेलते हुए हमने अपने डॉक्स और खोज में भी सुधार खोजे। इसके अलावा, Xata के पास आपकी कीवर्ड खोज को ट्यून करने के लिए एक बहुत अच्छा UI है, इसलिए काम शुरू करना कठिन नहीं था (उस बारे में एक अलग ब्लॉग पोस्ट की योजना बना रहा है)। ऐसा कोई कारण नहीं है जिसके लिए वेक्टर खोज में बूस्टर और कॉलम वेट और पसंद नहीं हो सकता है, लेकिन हमारे पास यह अभी तक Xata में नहीं है और मुझे किसी अन्य समाधान के बारे में नहीं पता है जो इसे उतना आसान बनाता है जितना हम कीवर्ड बनाते हैं खोज ट्यूनिंग। और, सामान्य तौर पर, खोजशब्द खोज के लिए अधिक पूर्व कला है, लेकिन यह बहुत संभव है कि सदिश खोज पकड़ लेगी। अभी के लिए, मैं कीवर्ड सर्च को विजेता कहूंगा स्कोर: 3-4 सुविधा हमारे प्रलेखन में पहले से ही एक खोज कार्य था, डॉग-फूडिंग Xata, इसलिए इसे चैट बॉट तक विस्तारित करना काफी सरल था। Xata अब मूल रूप से वेक्टर खोज का भी समर्थन करता है, लेकिन इसका उपयोग करने के लिए सभी दस्तावेज़ीकरण पृष्ठों के लिए एम्बेडिंग जोड़ना और एक अच्छी चंकिंग रणनीति का पता लगाना आवश्यक है। हमने टेक्स्ट एम्बेडिंग बनाने के लिए OpenAI एम्बेडिंग API का उपयोग किया है, जिसकी न्यूनतम लागत थी। विजेता: कीवर्ड खोज स्कोर 3-5 विलंब कीवर्ड खोज दृष्टिकोण को ChatGPT API के लिए अतिरिक्त राउंड-ट्रिप की आवश्यकता होती है। यह UI में स्ट्रीम किए जाने वाले परिणाम में विलंबता के संदर्भ में जोड़ता है। मेरे माप से, यह लगभग 1.8 अतिरिक्त समय जोड़ता है। सदिश खोज के साथ: कीवर्ड खोज के साथ: यहां कुल और सामग्री डाउनलोड समय प्रासंगिक नहीं हैं, क्योंकि वे ज्यादातर इस बात पर निर्भर करते हैं कि जनरेट की गई प्रतिक्रिया कितनी लंबी है। तुलना करने के लिए "सर्वर प्रतिक्रिया की प्रतीक्षा" बार (हरा वाला) देखें। नोट: विजेता: वेक्टर खोज स्कोर: 4-5 लागत कीवर्ड खोज संस्करण को ChatGPT API के लिए एक अतिरिक्त API कॉल करने की आवश्यकता है, दूसरी ओर, वेक्टर खोज संस्करण को डेटाबेस में सभी दस्तावेज़ों के लिए एम्बेडिंग और प्रश्न बनाने की आवश्यकता है। जब तक हम बहुत सारे दस्तावेज़ों के बारे में बात नहीं कर रहे हैं, मैं इसे टाई कहूंगा। स्कोर: 5-6 निष्कर्ष स्कोर कड़ा है! हमारे मामले में हम अभी के लिए कीवर्ड खोज का उपयोग करने के साथ चले गए हैं, अधिकतर क्योंकि हमारे पास इसे ट्यून करने के अधिक तरीके हैं और इसके परिणामस्वरूप यह हमारे परीक्षण प्रश्नों के सेट के लिए थोड़ा बेहतर उत्तर उत्पन्न करता है। साथ ही, हम खोज में जो भी सुधार करते हैं, वे स्वचालित रूप से खोज और चैट उपयोग मामलों दोनों को लाभान्वित करते हैं। जैसा कि हम अधिक ट्यूनिंग विकल्पों के साथ अपनी वेक्टर खोज क्षमताओं में सुधार कर रहे हैं, हम भविष्य में वेक्टर खोज, या हाइब्रिड दृष्टिकोण पर स्विच कर सकते हैं। यदि आप अपने स्वयं के दस्तावेज़ीकरण, या किसी भी प्रकार के ज्ञान के आधार के लिए एक समान चैट बॉट सेट अप करना चाहते हैं, तो आप Xata Ask समापन बिंदु का उपयोग करके उपरोक्त को आसानी से कार्यान्वित कर सकते हैं। फ्री में और पर हमसे जुड़ें। इसे शुरू करने और चलाने में आपकी व्यक्तिगत रूप से मदद करने में मुझे खुशी होगी! अकाउंट बनाएं डिस्कॉर्ड