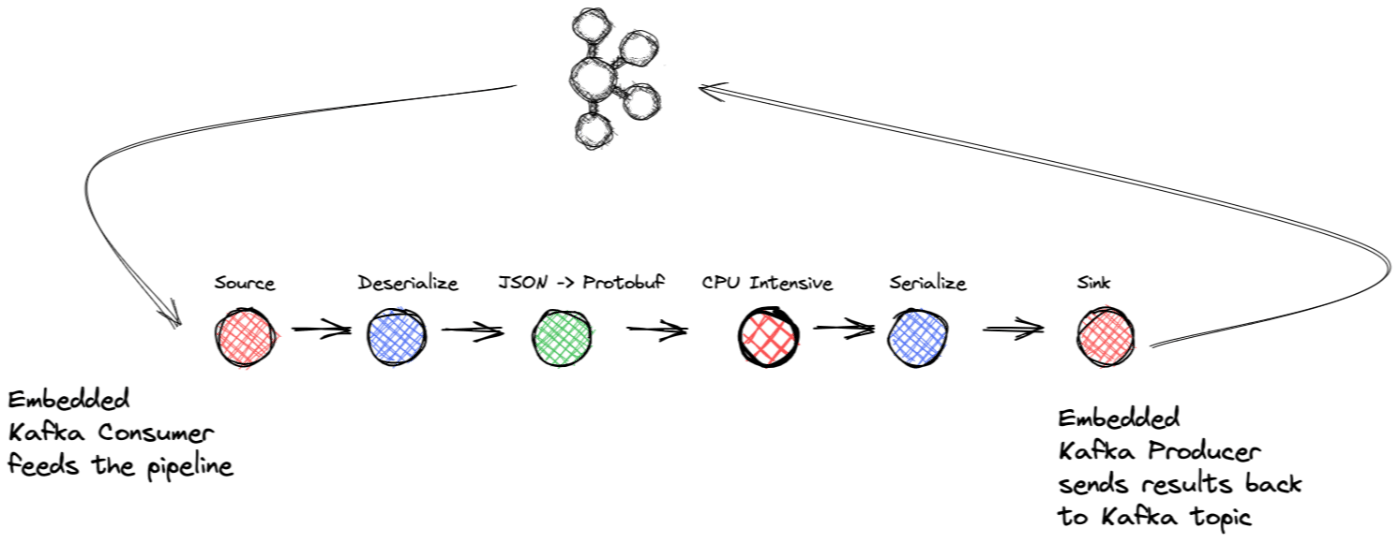
Khi bạn dừng lại và suy nghĩ về cuộc sống hàng ngày, bạn có thể dễ dàng xem mọi thứ như một sự kiện. Xét trình tự sau: Đèn báo "ít xăng" trên ô tô của bạn bật sáng Do đó, bạn dừng lại ở trạm nhiên liệu tiếp theo để đổ đầy Khi bạn bơm xăng vào xe, bạn sẽ được nhắc tham gia câu lạc bộ phần thưởng của công ty để được giảm giá Bạn vào trong và đăng ký và nhận tín dụng cho lần mua hàng tiếp theo của bạn Chúng ta có thể tiếp tục ở đây, nhưng tôi đã đưa ra quan điểm của mình: cuộc sống là một chuỗi các sự kiện. Trước thực tế đó, ngày nay bạn sẽ thiết kế một hệ thống phần mềm mới như thế nào? Bạn sẽ thu thập các kết quả khác nhau và xử lý chúng trong một khoảng thời gian tùy ý hay đợi đến cuối ngày để xử lý chúng? Không, bạn sẽ không; bạn muốn hành động theo từng sự kiện ngay khi nó xảy ra. Chắc chắn, có thể có những trường hợp bạn không thể phản ứng ngay lập tức với các trường hợp cá nhân… hãy nghĩ đến việc nhận được một lượng lớn các giao dịch có giá trị trong một ngày cùng một lúc. Tuy nhiên, bạn vẫn sẽ hành động ngay khi nhận được dữ liệu, một sự kiện gộp khá lớn nếu bạn muốn. Vì vậy, làm thế nào để bạn triển khai một hệ thống phần mềm để làm việc với các sự kiện? Câu trả lời là xử lý luồng. Xử lý luồng là gì? Trở thành công nghệ thực tế để xử lý dữ liệu sự kiện, xử lý luồng là một cách tiếp cận để phát triển phần mềm xem các sự kiện là đầu vào hoặc đầu ra chính của ứng dụng. Ví dụ: không có lý do gì phải chờ đợi để hành động dựa trên thông tin hoặc phản hồi về một giao dịch mua bằng thẻ tín dụng có khả năng gian lận. Đôi khi, nó có thể liên quan đến việc xử lý một luồng bản ghi đến trong một vi dịch vụ và việc xử lý chúng một cách hiệu quả nhất là điều tốt nhất cho ứng dụng của bạn. Dù trường hợp sử dụng là gì, có thể nói rằng phương pháp truyền phát sự kiện là phương pháp tốt nhất để xử lý sự kiện. Trong bài đăng trên blog này, chúng tôi sẽ xây dựng một ứng dụng phát trực tuyến sự kiện bằng cách sử dụng Apache Kafka®, ứng dụng khách tiêu dùng và nhà sản xuất .NET cũng như của Microsoft. Thoạt nhìn, bạn có thể không tự động đặt cả ba điều này lại với nhau như những ứng cử viên có khả năng làm việc cùng nhau. Chắc chắn, Kafka và các ứng dụng khách .NET là một cặp tuyệt vời, nhưng TPL phù hợp với bức tranh ở đâu? Thư viện song song tác vụ (TPL) Thông thường, thông lượng là một yêu cầu chính và để tránh tắc nghẽn do sự không phù hợp trở kháng giữa việc tiêu thụ từ Kafka và quá trình xử lý xuôi dòng, chúng tôi thường đề xuất song song hóa trong quá trình bất cứ khi nào có cơ hội. Đọc tiếp để xem cách cả ba thành phần phối hợp với nhau để xây dựng một ứng dụng truyền sự kiện mạnh mẽ và hiệu quả. Phần tốt nhất là ứng dụng khách Kafka và TPL đảm nhận hầu hết các công việc nặng nhọc; bạn chỉ cần tập trung vào logic kinh doanh của mình. Trước khi đi sâu vào ứng dụng, hãy mô tả ngắn gọn về từng thành phần. Apache Kafka Nếu xử lý luồng là tiêu chuẩn thực tế để xử lý luồng sự kiện, thì là tiêu chuẩn thực tế để xây dựng các ứng dụng truyền sự kiện. Apache Kafka là nhật ký phân tán được cung cấp theo cách có khả năng mở rộng cao, linh hoạt, chịu lỗi và an toàn. Tóm lại, Kafka sử dụng các nhà môi giới (máy chủ) và khách hàng. Các nhà môi giới tạo thành lớp lưu trữ phân tán của cụm Kafka, lớp này có thể bao trùm các trung tâm dữ liệu hoặc vùng đám mây. Khách hàng cung cấp khả năng đọc và ghi dữ liệu sự kiện từ cụm môi giới. Các cụm Kafka có khả năng chịu lỗi: nếu bất kỳ nhà môi giới nào bị lỗi, các nhà môi giới khác sẽ đảm nhận công việc để đảm bảo hoạt động liên tục. Apache Kafka Ứng dụng khách .NET hợp lưu Tôi đã đề cập trong đoạn trước rằng khách hàng viết hoặc đọc từ cụm nhà môi giới Kafka. Apache Kafka đi kèm với các máy khách Java, nhưng một số máy khách khác cũng có sẵn, cụ thể là nhà sản xuất và người tiêu dùng .NET Kafka, là trung tâm của ứng dụng trong bài đăng trên blog này. Nhà sản xuất và người tiêu dùng .NET mang đến sức mạnh truyền phát sự kiện với Kafka cho nhà phát triển .NET. Để biết thêm thông tin về các máy khách .NET, hãy tham khảo . tài liệu Thư viện song song nhiệm vụ Thư viện song song nhiệm vụ ( ) là "một tập hợp các loại và API công khai trong các không gian tên System.Threading và System.Threading.Tasks," đơn giản hóa công việc viết các ứng dụng đồng thời. TPL làm cho việc thêm đồng thời trở thành một tác vụ dễ quản lý hơn bằng cách xử lý các chi tiết sau: TPL 1. Xử lý phân vùng công việc 2. Lập lịch cho các luồng trên ThreadPool 3. Các chi tiết cấp thấp như hủy bỏ, quản lý trạng thái, v.v. Điểm mấu chốt là việc sử dụng TPL có thể tối đa hóa hiệu suất xử lý ứng dụng của bạn đồng thời cho phép bạn tập trung vào logic nghiệp vụ. Cụ thể, bạn sẽ sử dụng tập con của TPL. Thư viện Dataflow Thư viện Dataflow là một mô hình lập trình dựa trên diễn viên cho phép chuyển thông báo trong quá trình và thực hiện các tác vụ đường ống. Các thành phần Dataflow xây dựng trên các loại và cơ sở hạ tầng lập lịch trình của TPL và tích hợp liền mạch với ngôn ngữ C#. Việc đọc từ Kafka thường khá nhanh, nhưng quá trình xử lý (cuộc gọi DB hoặc cuộc gọi RPC) thường là một nút cổ chai. Bất kỳ cơ hội song song hóa nào mà chúng tôi có thể sử dụng sẽ đạt được thông lượng cao hơn trong khi không phải hy sinh đảm bảo đặt hàng đều đáng được xem xét. Trong bài đăng trên blog này, chúng tôi sẽ tận dụng các thành phần Dataflow này cùng với các máy khách .NET Kafka để xây dựng một ứng dụng xử lý luồng sẽ xử lý dữ liệu khi có sẵn. khối luồng dữ liệu Trước khi chúng tôi đi vào ứng dụng mà bạn sẽ xây dựng; chúng ta nên cung cấp một số thông tin cơ bản về những gì tạo nên Thư viện Luồng dữ liệu TPL. Cách tiếp cận chi tiết ở đây phù hợp nhất khi bạn có các tác vụ sử dụng nhiều CPU và I/O yêu cầu thông lượng cao. Thư viện Luồng dữ liệu TPL bao gồm các khối có thể đệm và xử lý dữ liệu hoặc bản ghi đến và các khối thuộc một trong ba loại: Khối nguồn – Hoạt động như một nguồn dữ liệu và các khối khác có thể đọc từ đó. Khối mục tiêu – Bộ thu dữ liệu hoặc phần chìm, có thể được ghi vào bởi các khối khác. Khối tuyên truyền – Hoạt động như một khối nguồn và đích. Bạn lấy các khối khác nhau và kết nối chúng để tạo thành một quy trình xử lý tuyến tính hoặc một biểu đồ xử lý phức tạp hơn. Hãy xem xét các minh họa sau: Thư viện Dataflow cung cấp một số loại khối được xác định trước thuộc ba loại: đệm, thực thi và nhóm. Chúng tôi đang sử dụng các loại thực thi và đệm cho dự án được phát triển cho bài đăng trên blog này. BufferBlock<T> là một cấu trúc có mục đích chung dùng để đệm dữ liệu và lý tưởng để sử dụng trong các ứng dụng của nhà sản xuất/người tiêu dùng. BufferBlock sử dụng hàng đợi vào trước, ra trước để xử lý dữ liệu đến. BufferBlock (và các lớp mở rộng nó) là loại khối duy nhất trong Thư viện luồng dữ liệu cung cấp khả năng viết và đọc thông báo trực tiếp; các loại khác muốn nhận tin nhắn từ hoặc gửi tin nhắn đến các khối. Vì lý do này, chúng tôi đã sử dụng làm đại biểu khi tạo khối nguồn và triển khai giao diện và khối chìm triển khai giao diện . BufferBlock ISourceBlock ITargetBlock Loại khối Dataflow khác được sử dụng trong ứng dụng của chúng tôi là . Giống như hầu hết các loại khối trong Thư viện luồng dữ liệu, bạn tạo một phiên bản của TransformBlock bằng cách cung cấp một để đóng vai trò là người đại diện khối chuyển đổi thực thi cho mỗi bản ghi đầu vào mà nó nhận được. TransformBlock <TInput, TOutput> Func<TInput, TOutput> Hai tính năng cơ bản của các khối Dataflow là bạn có thể kiểm soát số lượng bản ghi mà nó sẽ đệm và mức độ song song. Bằng cách đặt dung lượng bộ đệm tối đa, ứng dụng của bạn sẽ tự động áp dụng áp suất ngược khi ứng dụng gặp phải thời gian chờ kéo dài tại một số điểm trong quy trình xử lý. Áp suất ngược này là cần thiết để ngăn chặn sự tích lũy dữ liệu quá mức. Sau đó, khi sự cố giảm bớt và bộ đệm giảm kích thước, nó sẽ tiêu thụ lại dữ liệu. Khả năng đặt đồng thời cho một khối là rất quan trọng đối với hiệu suất. Nếu một khối thực hiện một tác vụ chuyên sâu về CPU hoặc I/O, thì sẽ có xu hướng tự nhiên là song song hóa công việc để tăng thông lượng. Nhưng việc thêm đồng thời có thể gây ra sự cố—đơn hàng xử lý. Nếu bạn thêm luồng vào tác vụ của khối, bạn không thể đảm bảo thứ tự đầu ra của dữ liệu. Trong một số trường hợp, thứ tự sẽ không thành vấn đề, nhưng khi nó quan trọng, đó là một sự đánh đổi nghiêm trọng cần xem xét: thông lượng cao hơn với đồng thời so với đầu ra của đơn đặt hàng xử lý. May mắn thay, bạn không phải đánh đổi điều này với Thư viện Dataflow. Khi bạn đặt tính song song của một khối thành nhiều khối, khung đảm bảo rằng nó sẽ duy trì thứ tự ban đầu của các bản ghi đầu vào (lưu ý rằng việc duy trì thứ tự với tính song song có thể định cấu hình được, với giá trị mặc định là đúng). Nếu thứ tự ban đầu của dữ liệu là A, B, C, thì thứ tự đầu ra sẽ là A, B, C. Hoài nghi? Tôi biết tôi đã như vậy, vì vậy tôi đã thử nó và phát hiện ra rằng nó hoạt động như quảng cáo. Chúng ta sẽ nói về bài kiểm tra này một lát sau trong bài đăng này. Lưu ý rằng việc tăng tính song song chỉ nên được thực hiện với các phép toán hoặc thái có , nghĩa là việc thay đổi thứ tự hoặc nhóm các phép toán sẽ không ảnh hưởng đến kết quả. không trạng thái trạng tính kết hợp và giao hoán Tại thời điểm này, bạn có thể thấy nơi này sẽ đi. Bạn có một chủ đề Kafka đại diện cho các sự kiện mà bạn cần xử lý theo cách nhanh nhất có thể. Vì vậy, bạn sẽ xây dựng một ứng dụng phát trực tuyến bao gồm một khối nguồn với .NET KafkaConsumer, các khối xử lý để thực hiện logic nghiệp vụ và một khối chìm chứa .NET KafkaProducer để ghi kết quả cuối cùng trở lại chủ đề Kafka. Dưới đây là minh họa về chế độ xem cấp cao của ứng dụng: Ứng dụng sẽ có cấu trúc như sau: Khối nguồn: Gói .NET KafkaConsumer và đại biểu BufferBlock Chuyển đổi khối: Deserialization Khối chuyển đổi: Ánh xạ dữ liệu JSON đến để mua đối tượng Khối chuyển đổi: tác vụ sử dụng nhiều CPU (mô phỏng) Chuyển đổi khối: Tuần tự hóa Khối mục tiêu: Bao bọc đại biểu .NET KafkaProducer và BufferBlock Tiếp theo là mô tả về luồng tổng thể của ứng dụng và một số điểm quan trọng về việc tận dụng Kafka và Thư viện luồng dữ liệu để xây dựng một ứng dụng truyền sự kiện mạnh mẽ. Một ứng dụng phát trực tuyến sự kiện Đây là tình huống của chúng tôi: Bạn có một chủ đề Kafka nhận hồ sơ mua hàng từ cửa hàng trực tuyến của bạn và định dạng dữ liệu đến là JSON. Bạn muốn xử lý các sự kiện mua hàng này bằng cách áp dụng suy luận ML cho các chi tiết mua hàng. Ngoài ra, bạn muốn chuyển đổi các bản ghi JSON sang định dạng Protobuf, vì đây là định dạng dữ liệu toàn công ty. Tất nhiên, thông lượng cho ứng dụng là điều cần thiết. Các hoạt động ML sử dụng nhiều CPU, vì vậy bạn cần một cách để tối đa hóa thông lượng của ứng dụng, vì vậy bạn sẽ tận dụng lợi thế của việc song song hóa phần đó của ứng dụng. Tiêu thụ dữ liệu vào đường ống Hãy xem xét các điểm quan trọng của ứng dụng phát trực tuyến, bắt đầu với khối nguồn. Tôi đã đề cập đến việc triển khai giao diện trước đó và vì cũng triển khai , nên chúng tôi sẽ sử dụng nó làm đại biểu để đáp ứng tất cả các phương thức giao diện. Vì vậy, việc triển khai khối nguồn sẽ bao bọc KafkaConsumer và BufferBlock. Bên trong khối nguồn của chúng tôi, chúng tôi sẽ có một chuỗi riêng biệt có trách nhiệm duy nhất là người tiêu dùng chuyển các bản ghi mà nó đã sử dụng vào bộ đệm. Từ đó, bộ đệm sẽ chuyển tiếp các bản ghi tới khối tiếp theo trong đường ống. ISourceBlock BufferBlock ISourceBlock Trước khi chuyển tiếp bản ghi vào bộ đệm, (được trả về bởi lệnh gọi ) được bao bọc bởi một bản trừu tượng, ngoài khóa và giá trị, còn ghi lại phân vùng và phần bù ban đầu, điều này rất quan trọng đối với ứng dụng—và Tôi sẽ giải thích tại sao ngay sau đây. Cũng cần lưu ý rằng toàn bộ quy trình hoạt động với bản tóm tắt , do đó, bất kỳ phép biến đổi nào cũng dẫn đến một đối tượng mới bao bọc khóa, giá trị và các trường thiết yếu khác như phần bù ban đầu bảo quản chúng trong toàn bộ quy trình. ConsumeRecord Consumer.consume Record Record Record khối xử lý Ứng dụng chia quá trình xử lý thành nhiều khối khác nhau. Mỗi khối liên kết với bước tiếp theo trong chuỗi xử lý, vì vậy khối nguồn liên kết với khối đầu tiên xử lý quá trình khử lưu huỳnh. Mặc dù .NET KafkaConsumer có thể xử lý quá trình giải tuần tự hóa các bản ghi, nhưng chúng tôi yêu cầu người tiêu dùng chuyển tải trọng được tuần tự hóa và giải tuần tự hóa trong một khối Chuyển đổi. Quá trình giải tuần tự hóa có thể tốn nhiều CPU, do đó, việc đưa phần này vào khối xử lý của nó cho phép chúng tôi song song hóa hoạt động nếu cần. Sau quá trình khử tuần tự hóa, các bản ghi chảy vào một khối Chuyển đổi khác để chuyển đổi tải trọng JSON thành một đối tượng mô hình dữ liệu Mua hàng ở định dạng Protobuf. Phần thú vị hơn xuất hiện khi dữ liệu đi vào khối tiếp theo, thể hiện một nhiệm vụ sử dụng nhiều CPU cần thiết để hoàn thành đầy đủ giao dịch mua hàng. Ứng dụng mô phỏng phần này và chức năng được cung cấp ở chế độ ngủ với thời gian ngẫu nhiên ở bất kỳ đâu trong khoảng từ một đến ba giây. Khối xử lý mô phỏng này là nơi chúng tôi tận dụng sức mạnh của khung khối Dataflow. Khi bạn khởi tạo một khối Dataflow, bạn cung cấp một phiên bản Func đại biểu mà nó áp dụng cho từng bản ghi mà nó gặp phải và một phiên bản . Trước đây tôi đã đề cập đến việc định cấu hình các khối Dataflow, nhưng chúng ta sẽ nhanh chóng xem lại chúng ở đây một lần nữa. chứa hai thuộc tính cơ bản: kích thước bộ đệm tối đa cho khối đó và mức độ song song hóa tối đa. ExecutionDataflowBlockOptions ExecutionDataflowBlockOptions Mặc dù chúng tôi đặt cấu hình kích thước bộ đệm cho tất cả các khối trong đường ống thành 10.000 bản ghi, chúng tôi vẫn giữ mức song song hóa mặc định là 1, ngoại trừ mức độ sử dụng nhiều CPU mô phỏng của chúng tôi, nơi chúng tôi đặt nó thành 4. Lưu ý rằng kích thước bộ đệm Dataflow mặc định là vô hạn. Chúng tôi sẽ thảo luận về ý nghĩa hiệu suất trong phần tiếp theo, nhưng bây giờ, chúng tôi sẽ hoàn thành tổng quan về ứng dụng. Khối xử lý chuyên sâu chuyển tiếp đến khối biến đổi tuần tự hóa cung cấp cho khối chìm, khối này sau đó bao bọc một .NET KafkaProducer và tạo ra kết quả cuối cùng cho một chủ đề Kafka. Khối chìm cũng sử dụng đại biểu và một luồng riêng để sản xuất. Chủ đề truy xuất bản ghi có sẵn tiếp theo từ bộ đệm. Sau đó, nó gọi phương thức truyền vào một đại biểu bao bọc — luồng I/O của nhà sản xuất sẽ thực thi đại biểu sau khi yêu cầu sản xuất hoàn tất. BufferBlock KafkaProducer.Produce Action DeliveryReport Action Điều đó hoàn thành hướng dẫn cấp cao của ứng dụng. Bây giờ, hãy thảo luận về một phần quan trọng trong quá trình thiết lập của chúng tôi—cách xử lý các khoản bù trừ cam kết—điều quan trọng là chúng tôi đang thu thập hồ sơ từ người tiêu dùng. Cam kết bù trừ Khi xử lý dữ liệu với Kafka, bạn sẽ thực hiện các giá trị bù định kỳ (giá trị bù là vị trí logic của bản ghi trong chủ đề Kafka) của các bản ghi mà ứng dụng của bạn đã xử lý thành công cho đến một điểm nhất định. Vậy tại sao một người cam kết bù đắp? Đó là một câu hỏi dễ trả lời: khi người tiêu dùng của bạn tắt theo cách được kiểm soát hoặc do lỗi, nó sẽ tiếp tục xử lý từ phần bù cam kết đã biết cuối cùng. Bằng cách cam kết bù đắp định kỳ, người tiêu dùng của bạn sẽ không xử lý lại các bản ghi hoặc ít nhất là một lượng tối thiểu nếu ứng dụng của bạn ngừng hoạt động sau khi xử lý một vài bản ghi nhưng cam kết. Cách tiếp cận này được gọi là xử lý ít nhất một lần, đảm bảo các bản ghi được xử lý ít nhất một lần và trong trường hợp có lỗi, một số trong số chúng có thể được xử lý lại, nhưng đó là một lựa chọn tuyệt vời khi giải pháp thay thế có nguy cơ mất dữ liệu. Kafka cũng cung cấp đảm bảo xử lý chính xác một lần và mặc dù chúng tôi sẽ không tham gia vào các giao dịch trong bài đăng trên blog này, nhưng bạn có thể đọc thêm về các giao dịch trong Kafka trong . trước khi bài đăng trên blog này Mặc dù có một số cách khác nhau để cam kết bù đắp, nhưng đơn giản và cơ bản nhất là phương pháp tự động cam kết. Người tiêu dùng đọc các bản ghi và ứng dụng xử lý chúng. Sau một khoảng thời gian có thể định cấu hình trôi qua (dựa trên dấu thời gian của bản ghi), người tiêu dùng sẽ cam kết phần bù của các bản ghi đã sử dụng. Thông thường, tự động cam kết là một cách tiếp cận hợp lý; trong vòng lặp quy trình tiêu thụ thông thường, bạn sẽ không quay lại ứng dụng tiêu dùng cho đến khi bạn xử lý thành công tất cả (các) bản ghi đã sử dụng trước đó. Nếu có lỗi hoặc tắt máy không mong muốn, mã sẽ không bao giờ trả lại cho người tiêu dùng, vì vậy không có cam kết nào xảy ra. Nhưng trong ứng dụng của chúng tôi ở đây, chúng tôi đang tạo đường ống—chúng tôi lấy các bản ghi đã tiêu thụ và đẩy chúng vào bộ đệm và quay lại tiêu thụ nhiều hơn—không cần chờ xử lý thành công. , phương thức này thực hiện một tham số duy nhất—một —và lưu trữ nó (cùng với các phần bù khác) cho lần xác nhận tiếp theo. Lưu ý rằng trái ngược với cách hoạt động của tính năng tự động cam kết với API Java. Với cách tiếp cận theo đường ống, làm cách nào để chúng tôi đảm bảo xử lý ít nhất một lần? Chúng ta sẽ tận dụng phương thức IConsumer.StoreOffset TopicPartitionOffset cách tiếp cận quản lý bù đắp này Vì vậy, quy trình cam kết hoạt động theo cách này: khi khối chìm truy xuất một bản ghi để tạo cho Kafka, nó cũng cung cấp bản ghi đó cho đại biểu Hành động. Khi nhà sản xuất thực hiện lệnh gọi lại, nó sẽ chuyển phần bù ban đầu cho người tiêu dùng (cùng một phiên bản trong khối nguồn) và người tiêu dùng sử dụng phương thức StoreOffset. Bạn vẫn bật tính năng tự động cam kết cho người tiêu dùng, nhưng bạn đang cung cấp các khoản bù đắp để cam kết thay vì yêu cầu người tiêu dùng cam kết một cách mù quáng các khoản bù đắp mới nhất mà nó đã sử dụng cho đến thời điểm này. Vì vậy, mặc dù ứng dụng sử dụng đường ống, nhưng nó chỉ cam kết sau khi nhận được xác nhận từ nhà môi giới, nghĩa là nhà môi giới và nhóm nhà môi giới bản sao tối thiểu đã lưu trữ bản ghi. Làm việc theo cách này cho phép ứng dụng tiến triển nhanh hơn vì người tiêu dùng có thể liên tục tìm nạp và cung cấp đường ống trong khi các khối thực hiện công việc của họ. Cách tiếp cận này có thể thực hiện được vì ứng dụng khách .NET là luồng an toàn (một số phương thức không và được ghi lại như vậy), vì vậy chúng tôi có thể để người tiêu dùng duy nhất của mình làm việc an toàn trong cả luồng khối nguồn và khối chìm. Đối với bất kỳ lỗi nào trong giai đoạn sản xuất, ứng dụng sẽ ghi lại lỗi và đưa bản ghi trở lại lồng nhau để nhà sản xuất sẽ thử gửi lại bản ghi cho nhà môi giới. Nhưng logic thử lại này được thực hiện một cách mù quáng và trong thực tế, có thể bạn sẽ muốn có một giải pháp mạnh mẽ hơn. BufferBlock Ý nghĩa hiệu suất Bây giờ chúng ta đã tìm hiểu về cách thức hoạt động của ứng dụng, hãy xem xét các con số về hiệu suất. Tất cả các thử nghiệm đều được thực hiện cục bộ trên máy tính xách tay chạy macOS Big Sur (11.6), vì vậy số dặm của bạn có thể thay đổi trong trường hợp này. Thiết lập kiểm tra hiệu suất rất đơn giản: Tạo 1 triệu bản ghi cho một chủ đề Kafka ở định dạng JSON. Bước này đã được thực hiện trước và không được bao gồm trong các phép đo kiểm tra. Khởi động ứng dụng hỗ trợ Kafka Dataflow và đặt song song hóa trên tất cả các khối thành 1 (mặc định) Ứng dụng chạy cho đến khi xử lý thành công 1 triệu bản ghi, sau đó ứng dụng sẽ tắt Ghi lại thời gian cần thiết để xử lý tất cả các bản ghi Sự khác biệt duy nhất cho vòng thứ hai là đặt MaxDegreeOfParallelism cho khối sử dụng nhiều CPU được mô phỏng thành bốn. Đây là kết quả: Số bản ghi Yếu tố đồng thời Thời gian (phút) 1M 1 38 1M 4 9 Vì vậy, chỉ bằng cách đặt cấu hình, chúng tôi đã cải thiện đáng kể thông lượng trong khi vẫn duy trì thứ tự sự kiện. Vì vậy, bằng cách cho phép mức độ song song tối đa lên bốn, chúng tôi sẽ tăng tốc dự kiến theo hệ số lớn hơn bốn. Nhưng phần quan trọng của cải tiến hiệu suất này là bạn không viết bất kỳ mã đồng thời nào, điều này sẽ khó thực hiện chính xác. Trước đó trong bài đăng trên blog, tôi đã đề cập đến một thử nghiệm để xác thực rằng sự tương tranh với các khối Dataflow sẽ duy trì thứ tự sự kiện, vì vậy bây giờ chúng ta hãy nói về điều đó. Thử nghiệm bao gồm các bước sau: Tạo số nguyên 1M (0-999,999) cho chủ đề Kafka Sửa đổi ứng dụng tham chiếu để hoạt động với các kiểu số nguyên Chạy ứng dụng với mức đồng thời là một cho khối quy trình từ xa được mô phỏng—tạo ra chủ đề Kafka Chạy lại ứng dụng với mức đồng thời là bốn và tạo các số cho một chủ đề Kafka khác Chạy chương trình để sử dụng các số nguyên từ cả hai chủ đề kết quả và lưu trữ chúng trong một mảng trong bộ nhớ So sánh cả hai mảng và xác nhận chúng theo thứ tự giống hệt nhau Kết quả của thử nghiệm này là cả hai mảng đều chứa các số nguyên theo thứ tự từ 0 đến 999.999, chứng tỏ rằng việc sử dụng khối Dataflow với mức độ song song nhiều hơn một đã duy trì thứ tự xử lý của dữ liệu đến. Bạn có thể tìm thêm thông tin chi tiết về tính song song của Dataflow trong . tài liệu Bản tóm tắt bài đăng này, chúng tôi đã giới thiệu cách sử dụng các ứng dụng khách .NET Kafka và Thư viện song song tác vụ để xây dựng một ứng dụng phát trực tuyến sự kiện mạnh mẽ, thông lượng cao. Kafka cung cấp khả năng phát trực tuyến sự kiện hiệu suất cao và Thư viện song song tác vụ cung cấp cho bạn các khối xây dựng để tạo các ứng dụng đồng thời với bộ đệm để xử lý tất cả các chi tiết, cho phép các nhà phát triển tập trung vào logic nghiệp vụ. Mặc dù kịch bản cho ứng dụng có một chút giả tạo, nhưng hy vọng bạn có thể thấy sự hữu ích của việc kết hợp hai công nghệ. Hãy thử một lần- . Trong đây là kho lưu trữ GitHub Cũng được xuất bản ở đây.