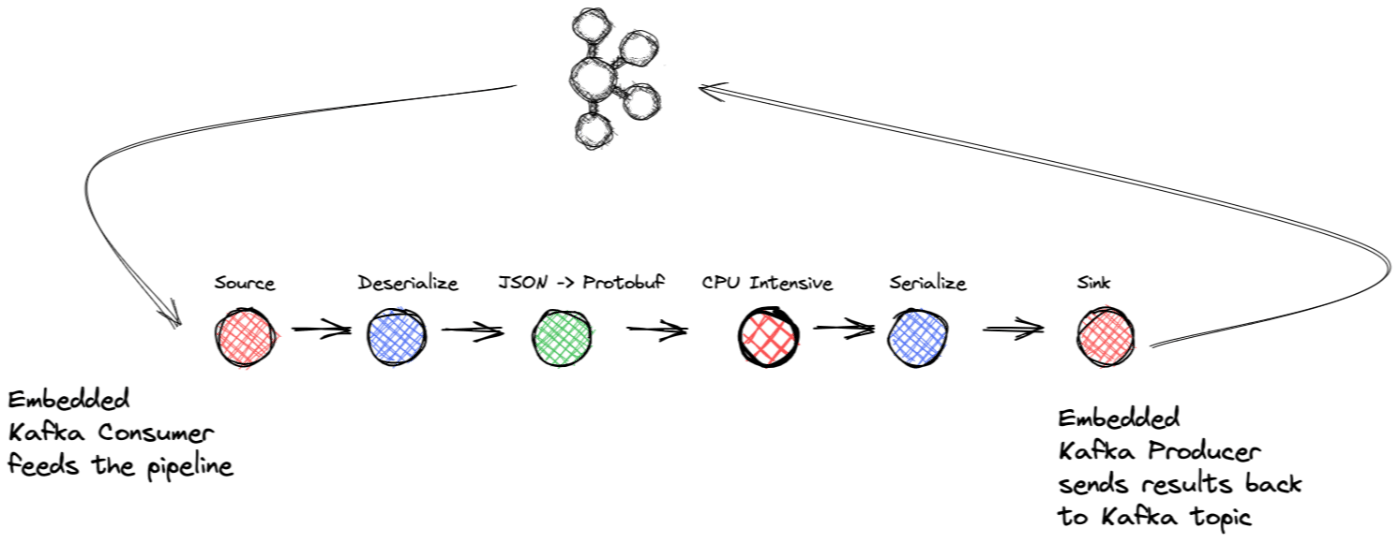
Quando você para e pensa na vida cotidiana, pode facilmente ver tudo como um evento. Considere a seguinte sequência: O indicador de "pouco combustível" do seu carro acende Como resultado, você para no próximo posto de combustível para abastecer Ao colocar gasolina no carro, você é solicitado a ingressar no clube de recompensas da empresa para obter um desconto Você entra e se inscreve e recebe um crédito para sua próxima compra Poderíamos continuar aqui, mas já fiz o que quero dizer: a vida é uma sequência de eventos. Dado esse fato, como você projetaria um novo sistema de software hoje? Você coletaria diferentes resultados e os processaria em algum intervalo arbitrário ou esperaria até o final do dia para processá-los? Não, você não faria; você gostaria de agir em cada evento assim que acontecesse. Claro, pode haver casos em que você não pode responder imediatamente a circunstâncias individuais... pense em obter um despejo de transações de um dia de uma só vez. Mesmo assim, você agiria assim que recebesse os dados, um evento considerável de valor fixo, se assim o desejar. Então, como você implementa um sistema de software para trabalhar com eventos? A resposta é o processamento de fluxo. O que é processamento de fluxo? Tornando-se a tecnologia de fato para lidar com dados de eventos, o processamento de fluxo é uma abordagem para o desenvolvimento de software que visualiza os eventos como entrada ou saída primária de um aplicativo. Por exemplo, não faz sentido esperar para agir com base nas informações ou responder a uma possível compra fraudulenta com cartão de crédito. Outras vezes, pode envolver a manipulação de um fluxo de entrada de registros em um microsserviço, e processá-los com mais eficiência é o melhor para seu aplicativo. Seja qual for o caso de uso, é seguro dizer que uma abordagem de streaming de evento é a melhor abordagem para lidar com eventos. Nesta postagem de blog, criaremos um aplicativo de streaming de eventos usando o Apache Kafka®, o produtor .NET e os clientes consumidores e a da Microsoft. À primeira vista, você pode não colocar automaticamente todos os três juntos como candidatos prováveis para trabalhar juntos. Claro, Kafka e os clientes .NET são um ótimo par, mas onde o TPL se encaixa na imagem? Task Parallel Library (TPL) Na maioria das vezes, a taxa de transferência é um requisito fundamental e, para evitar gargalos devido a incompatibilidades de impedância entre o consumo de Kafka e o processamento downstream, geralmente sugerimos a paralelização no processo sempre que surgir a oportunidade. Continue lendo para ver como todos os três componentes trabalham juntos para criar um aplicativo de streaming de eventos robusto e eficiente. A melhor parte é que o cliente Kafka e o TPL cuidam da maior parte do trabalho pesado; você só precisa se concentrar em sua lógica de negócios. Antes de mergulharmos no aplicativo, vamos dar uma breve descrição de cada componente. Apache Kafka Se o processamento de fluxo é o padrão de fato para lidar com fluxos de eventos, o é o padrão de fato para criar aplicativos de fluxo de eventos. O Apache Kafka é um log distribuído fornecido de maneira altamente escalável, elástica, tolerante a falhas e segura. Em poucas palavras, Kafka usa corretores (servidores) e clientes. Os agentes formam a camada de armazenamento distribuído do cluster Kafka, que pode abranger data centers ou regiões de nuvem. Os clientes fornecem a capacidade de ler e gravar dados de eventos de um cluster de agente. Os clusters Kafka são tolerantes a falhas: se algum agente falhar, outros agentes assumirão o trabalho para garantir operações contínuas. Apache Kafka Clientes .NET confluentes Mencionei no parágrafo anterior que os clientes gravam ou leem de um cluster de agente Kafka. Pacotes Apache Kafka com clientes Java, mas vários outros clientes estão disponíveis, ou seja, o produtor e consumidor .NET Kafka, que está no centro do aplicativo nesta postagem de blog. O produtor e consumidor .NET trazem o poder do streaming de eventos com Kafka para o desenvolvedor .NET. Para obter mais informações sobre os clientes .NET, consulte a . documentação Biblioteca Paralela de Tarefas A Task Parallel Library ( ) é "um conjunto de tipos públicos e APIs nos namespaces System.Threading e System.Threading.Tasks", simplificando o trabalho de escrever aplicativos simultâneos. O TPL torna a adição de simultaneidade uma tarefa mais gerenciável ao lidar com os seguintes detalhes: TPL 1. Manipulando o particionamento do trabalho 2. Agendando threads no ThreadPool 3. Detalhes de baixo nível, como cancelamento, gerenciamento de estado, etc. O resultado final é que usar o TPL pode maximizar o desempenho de processamento do seu aplicativo enquanto permite que você se concentre na lógica de negócios. Especificamente, você usará o subconjunto do TPL. Dataflow Library A biblioteca de fluxo de dados é um modelo de programação baseado em ator que permite a passagem de mensagens em processo e tarefas de pipelining. Os componentes do Dataflow se baseiam nos tipos e na infraestrutura de programação do TPL e se integram perfeitamente à linguagem C#. A leitura do Kafka geralmente é bastante rápida, mas o processamento (uma chamada de banco de dados ou RPC) geralmente é um gargalo. Vale a pena considerar quaisquer oportunidades de paralelização que possamos utilizar para obter maior rendimento sem sacrificar as garantias de pedido. Nesta postagem do blog, aproveitaremos esses componentes do Dataflow junto com os clientes .NET Kafka para criar um aplicativo de processamento de fluxo que processará os dados à medida que forem disponibilizados. blocos de fluxo de dados Antes de entrarmos no aplicativo que você vai construir; devemos fornecer algumas informações básicas sobre o que compõe a biblioteca TPL Dataflow. A abordagem detalhada aqui é mais aplicável quando você tem tarefas intensivas de CPU e E/S que exigem alto rendimento. A TPL Dataflow Library consiste em blocos que podem armazenar em buffer e processar dados ou registros de entrada, e os blocos se enquadram em uma das três categorias: Blocos de origem – atuam como uma fonte de dados e outros blocos podem ler a partir dele. Blocos de destino – Um receptor de dados ou um coletor, que pode ser gravado por outros blocos. Blocos propagadores – Comportam-se tanto como um bloco de origem quanto como um bloco de destino. Você pega os diferentes blocos e os conecta para formar um pipeline de processamento linear ou um gráfico de processamento mais complexo. Considere as seguintes ilustrações: A biblioteca de fluxo de dados fornece vários tipos de blocos predefinidos que se enquadram em três categorias: armazenamento em buffer, execução e agrupamento. Estamos usando os tipos de buffer e execução para o projeto desenvolvido para esta postagem no blog. O BufferBlock<T> é uma estrutura de uso geral que armazena dados em buffer e é ideal para uso em aplicativos de produtor/consumidor. O BufferBlock usa uma fila de primeiro a entrar, primeiro a sair para lidar com os dados recebidos. O BufferBlock (e as classes que o estendem) é o único tipo de bloco na biblioteca Dataflow que permite escrever e ler mensagens diretamente; outros tipos esperam receber ou enviar mensagens para blocos. Por esse motivo, usamos um como delegado ao criar o bloco de origem e implementar a interface e o bloco coletor implementando a interface . BufferBlock ISourceBlock ITargetBlock O outro tipo de bloco Dataflow usado em nosso aplicativo é um . Como a maioria dos tipos de bloco na Biblioteca de fluxo de dados, você cria uma instância do TransformBlock fornecendo um para atuar como um delegado que o bloco de transformação executa para cada registro de entrada que recebe. TransformBlock <TInput, TOutput> Func<TInput, TOutput> Dois recursos essenciais dos blocos do Dataflow são que você pode controlar o número de registros que ele armazenará em buffer e o nível de paralelismo. Ao definir uma capacidade máxima de buffer, seu aplicativo aplicará automaticamente pressão de retorno quando o aplicativo encontrar uma espera prolongada em algum ponto do pipeline de processamento. Essa contrapressão é necessária para evitar o acúmulo excessivo de dados. Então, quando o problema diminuir e o buffer diminuir de tamanho, ele consumirá dados novamente. A capacidade de definir a simultaneidade de um bloco é crítica para o desempenho. Se um bloco executa uma tarefa intensiva de CPU ou E/S, há uma tendência natural de paralelizar o trabalho para aumentar a taxa de transferência. Mas adicionar simultaneidade pode causar um problema - ordem de processamento. Se você adicionar threading à tarefa de um bloco, não poderá garantir a ordem de saída dos dados. Em alguns casos, a ordem não importa, mas quando importa, é um compromisso sério a ser considerado: maior rendimento com simultaneidade versus saída de ordem de processamento. Felizmente, você não precisa fazer essa troca com a biblioteca Dataflow. Ao definir o paralelismo de um bloco para mais de um, o framework garante que manterá a ordem original dos registros de entrada (observe que a manutenção da ordem com paralelismo é configurável, sendo o valor padrão true). Se a ordem original dos dados for A, B, C, então a ordem de saída será A, B, C. Cético? Eu sei que estava, então testei e descobri que funcionava como anunciado. Falaremos sobre esse teste um pouco mais adiante neste post. Observe que o aumento do paralelismo só deve ser feito com operações ou que sejam , ou seja, alterar a ordem ou agrupamento das operações não afetará o resultado. stateless stateful associativas e comutativas Neste ponto, você pode ver onde isso está indo. Você tem um tópico Kafka representando eventos que precisa tratar da maneira mais rápida possível. Portanto, você criará um aplicativo de streaming composto por um bloco de origem com um .NET KafkaConsumer, blocos de processamento para realizar a lógica de negócios e um bloco coletor contendo um .NET KafkaProducer para gravar os resultados finais de volta em um tópico Kafka. Aqui está uma ilustração de uma visão de alto nível do aplicativo: A candidatura terá a seguinte estrutura: Bloco de origem: encapsulando um .NET KafkaConsumer e um delegado BufferBlock Bloco de transformação: desserialização Bloco de transformação: mapeando dados JSON de entrada para comprar objeto Bloco de transformação: tarefa intensiva de CPU (simulada) Bloco de transformação: serialização Bloco de destino: encapsulando um delegado .NET KafkaProducer e BufferBlock A seguir, há uma descrição do fluxo geral do aplicativo e alguns pontos críticos sobre como aproveitar o Kafka e a Biblioteca de fluxo de dados para criar um poderoso aplicativo de streaming de eventos. Um aplicativo de streaming de eventos Este é o nosso cenário: você tem um tópico Kafka que recebe registros de compras de sua loja online e o formato de dados de entrada é JSON. Você deseja processar esses eventos de compra aplicando a inferência de ML aos detalhes da compra. Além disso, você gostaria de transformar os registros JSON no formato Protobuf, pois esse é o formato de dados de toda a empresa. Obviamente, o rendimento do aplicativo é essencial. As operações de ML consomem muita CPU, portanto, você precisa de uma maneira de maximizar a taxa de transferência do aplicativo, para aproveitar a paralelização dessa parte do aplicativo. Consumindo dados no pipeline Vamos percorrer os pontos críticos do aplicativo de streaming, começando pelo bloco de origem. Mencionei antes a implementação da interface e, como também implementa , vamos usá-la como um delegado para atender a todos os métodos de interface. Portanto, a implementação do bloco de origem envolverá um KafkaConsumer e o BufferBlock. Dentro do nosso bloco source, teremos uma thread separada cuja única responsabilidade é que o consumidor passe os registros que consumiu para o buffer. A partir daí, o buffer encaminhará os registros para o próximo bloco no pipeline. ISourceBlock BufferBlock ISourceBlock Antes de encaminhar o registro para o buffer, o (retornado pela chamada ) é agrupado por uma abstração que, além da chave e do valor, captura a partição original e o deslocamento, o que é crítico para o aplicativo — e Vou explicar o porquê em breve. Também vale a pena observar que todo o pipeline funciona com a abstração , portanto, qualquer transformação resulta em um novo objeto envolvendo a chave, o valor e outros campos essenciais, como o deslocamento original, preservando-os em todo o pipeline. ConsumeRecord Consumer.consume Record Record Record Blocos de processamento O aplicativo divide o processamento em vários blocos diferentes. Cada bloco é vinculado à próxima etapa na cadeia de processamento, de modo que o bloco de origem é vinculado ao primeiro bloco, que lida com a desserialização. Enquanto o .NET KafkaConsumer pode lidar com a desserialização de registros, temos o consumidor passando a carga serializada e desserializando em um bloco Transform. A desserialização pode consumir muita CPU, portanto, colocá-la em seu bloco de processamento nos permite paralelizar a operação, se necessário. Após a desserialização, os registros fluem para outro bloco Transform que converte a carga JSON em um objeto de modelo de dados Purchase no formato Protobuf. A parte mais interessante ocorre quando os dados vão para o próximo bloco, representando uma tarefa intensiva de CPU necessária para concluir totalmente a transação de compra. O aplicativo simula esta parte e a função fornecida é suspensa com um tempo aleatório de um a três segundos. Esse bloco de processamento simulado é onde aproveitamos o poder da estrutura de blocos do Dataflow. Ao instanciar um bloco Dataflow, você fornece uma instância Func delegada que ele aplica a cada registro encontrado e uma instância . Mencionei a configuração dos blocos do Dataflow antes, mas vamos analisá-los rapidamente aqui novamente. contém duas propriedades essenciais: o tamanho máximo do buffer para esse bloco e o grau máximo de paralelização. ExecutionDataflowBlockOptions ExecutionDataflowBlockOptions Embora definimos a configuração do tamanho do buffer para todos os blocos no pipeline para 10.000 registros, mantemos o nível de paralelização padrão de 1, exceto para nosso uso intensivo de CPU simulado, em que o definimos como 4. Observe que o tamanho padrão do buffer do Dataflow é ilimitado. Discutiremos as implicações de desempenho na próxima seção, mas, por enquanto, completaremos a visão geral do aplicativo. O bloco de processamento intensivo encaminha para um bloco de transformação de serialização que alimenta o bloco coletor, que então envolve um .NET KafkaProducer e produz os resultados finais para um tópico Kafka. O bloco coletor também usa um delegado e um thread separado para produção. O thread recupera o próximo registro disponível do buffer. Em seguida, ele chama o método passando em um delegado envolvendo o — o encadeamento de E/S do produtor executará o delegado de assim que a solicitação de produção for concluída. BufferBlock KafkaProducer.Produce Action DeliveryReport Action Isso conclui o passo a passo de alto nível do aplicativo. Agora, vamos discutir uma parte crucial de nossa configuração - como lidar com compensações de confirmação - que é vital, visto que estamos canalizando registros do consumidor. Compensar compensações Ao processar dados com Kafka, você confirmará deslocamentos periodicamente (um deslocamento é a posição lógica de um registro em um tópico Kafka) dos registros que seu aplicativo processou com êxito até um determinado ponto. Então, por que alguém comete as compensações? Essa é uma pergunta fácil de responder: quando seu consumidor desligar de maneira controlada ou por erro, ele retomará o processamento a partir do último deslocamento confirmado conhecido. Ao confirmar periodicamente as compensações, seu consumidor não reprocessará os registros ou pelo menos uma quantidade mínima caso seu aplicativo seja encerrado após o processamento de alguns registros, mas da confirmação. Essa abordagem é conhecida como processamento pelo menos uma vez, o que garante que os registros sejam processados pelo menos uma vez e, no caso de erros, talvez alguns deles sejam reprocessados, mas é uma ótima opção quando a alternativa é arriscar a perda de dados. O Kafka também fornece garantias de processamento exatamente uma vez e, embora não falemos sobre transações nesta postagem do blog, você pode ler mais sobre transações no Kafka em . antes esta postagem no blog Embora existam várias maneiras diferentes de confirmar compensações, a mais simples e básica é a abordagem de confirmação automática. O consumidor lê os registros e o aplicativo os processa. Após um período de tempo configurável (com base nos carimbos de data/hora do registro), o consumidor confirmará os deslocamentos dos registros já consumidos. Normalmente, a confirmação automática é uma abordagem razoável; em um loop de processo de consumo típico, você não retornará ao consumidor até que tenha processado com êxito todos os registros consumidos anteriormente. Se houvesse um erro inesperado ou desligamento, o código nunca retornaria ao consumidor e, portanto, não ocorreria nenhuma confirmação. Mas em nosso aplicativo aqui, estamos canalizando - pegamos os registros consumidos e os colocamos em um buffer e retornamos para consumir mais - não há espera pelo processamento bem-sucedido. , que executa um único parâmetro — um — e o armazena (junto com outros deslocamentos) para o próximo commit. Observe que contrasta como a confirmação automática funciona com a API Java. Com a abordagem de pipelining, como garantimos o processamento pelo menos uma vez? Aproveitaremos o método IConsumer.StoreOffset TopicPartitionOffset essa abordagem para o gerenciamento de compensação Portanto, o procedimento de confirmação funciona da seguinte maneira: quando o bloco coletor recupera um registro para produzir no Kafka, ele também o fornece ao delegado Action. Quando o produtor executa o retorno de chamada, ele passa o deslocamento original para o consumidor (a mesma instância no bloco de origem) e o consumidor usa o método StoreOffset. Você ainda tem a confirmação automática habilitada para o consumidor, mas está fornecendo as compensações para confirmação em vez de fazer com que o consumidor confirme cegamente as últimas compensações consumidas até este ponto. Portanto, mesmo que o aplicativo use pipelining, ele confirma somente após receber um ACK do broker, o que significa que o broker e o conjunto mínimo de brokers de réplica armazenaram o registro. Trabalhar dessa maneira permite que o aplicativo progrida mais rapidamente, pois o consumidor pode buscar e alimentar continuamente o pipeline enquanto os blocos executam seu trabalho. Essa abordagem é possível porque o cliente consumidor .NET é thread-safe (alguns métodos não são e estão documentados como tal), portanto, podemos ter nosso único consumidor trabalhando com segurança nos threads do bloco de origem e do coletor. Para qualquer erro durante o estágio de produção, o aplicativo registra o erro e coloca o registro de volta no aninhado para que o produtor tente novamente enviar o registro ao intermediário. Mas essa lógica de repetição é feita cegamente e, na prática, você provavelmente desejará uma solução mais robusta. BufferBlock Implicações de desempenho Agora que abordamos como o aplicativo funciona, vamos ver os números de desempenho. Todos os testes foram executados localmente em um laptop macOS Big Sur (11.6), portanto, sua milhagem pode variar neste cenário. A configuração do teste de desempenho é simples: Produza 1 milhão de registros para um tópico Kafka no formato JSON. Esta etapa foi realizada com antecedência e não foi incluída nas medições do teste. Inicie o aplicativo habilitado para Kafka Dataflow e defina a paralelização em todos os blocos como 1 (o padrão) O aplicativo é executado até processar com êxito 1 milhão de registros e, em seguida, é encerrado Registre o tempo que levou para processar todos os registros A única diferença para a segunda rodada foi definir o MaxDegreeOfParallelism para o bloco de uso intensivo de CPU simulado para quatro. Aqui estão os resultados: Número de registros Fator de simultaneidade Tempo (minutos) 1M 1 38 1M 4 9 Portanto, simplesmente definindo uma configuração, melhoramos significativamente a taxa de transferência enquanto mantemos a ordem do evento. Portanto, habilitando um grau máximo de paralelismo para quatro, obtemos a aceleração esperada por um fator maior que quatro. Mas a parte crítica dessa melhoria de desempenho é que você não escreveu nenhum código simultâneo, o que seria difícil de fazer corretamente. Anteriormente na postagem do blog, mencionei um teste para validar que a simultaneidade com blocos do Dataflow preserva a ordem do evento, então vamos falar sobre isso agora. O julgamento envolveu as seguintes etapas: Produzir inteiros de 1M (0-999.999) para um tópico Kafka Modifique o aplicativo de referência para trabalhar com tipos inteiros Execute o aplicativo com um nível de simultaneidade de um para o bloco de processo remoto simulado — produzir para um tópico Kafka Execute novamente o aplicativo com um nível de simultaneidade de quatro e produza os números para outro tópico Kafka Execute um programa para consumir os números inteiros de ambos os tópicos de resultado e armazene-os em uma matriz na memória Compare os dois arrays e confirme se eles estão em ordem idêntica O resultado desse teste foi que ambos os arrays continham os inteiros na ordem de 0 a 999.999, provando que o uso de um bloco Dataflow com um nível de paralelismo maior que um manteve a ordem de processamento dos dados recebidos. Você pode encontrar informações mais detalhadas sobre o paralelismo do Dataflow na . documentação Resumo postagem, apresentamos como usar os clientes .NET Kafka e a Task Parallel Library para criar um aplicativo de streaming de eventos robusto e de alto rendimento. O Kafka fornece streaming de eventos de alto desempenho, e a Task Parallel Library fornece os blocos de construção para criar aplicativos simultâneos com buffer para lidar com todos os detalhes, permitindo que os desenvolvedores se concentrem na lógica de negócios. Embora o cenário do aplicativo seja um pouco artificial, esperamos que você possa ver a utilidade de combinar as duas tecnologias. De uma chance- . Nesta aqui está o repositório do GitHub Também publicado aqui.