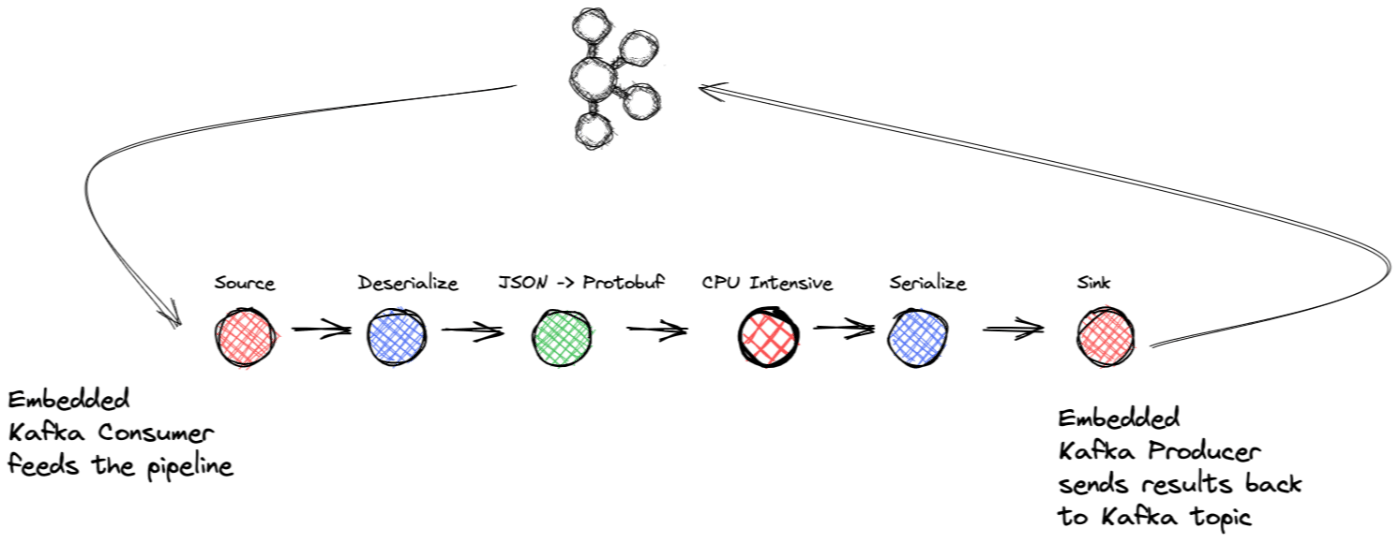
When you stop and think about everyday life, you can easily view everything as an event. Consider the following sequence: Your car's "low fuel" indicator comes on As a result, you stop at the next fuel station to fill up When you pump gas into the car, you get prompted to join the company’s rewards club to get a discount You go inside and sign up and get a credit toward your next purchase We could go on and on here, but I've made my point: life is a sequence of events. Given that fact, how would you design a new software system today? Would you collect different results and process them at some arbitrary interval or wait until the end of the day to process them? No, you wouldn't; you'd want to act on each event as soon as it happens. Sure, there may be cases where you can't respond immediately to individual circumstances… think of getting a dump of a day’s worth of transactions at one time. But still, you would act as soon as you received the data, a sizeable lump-sum event if you will. So, how do you implement a software system for working with events? The answer is stream processing. What is Stream Processing? Becoming the de facto technology for dealing with event data, stream processing is an approach to software development that views events as an application's primary input or output. For example, there's no sense in waiting to act on information or respond to a potential fraudulent credit card purchase. Other times it might involve handling an incoming flow of records in a microservice, and processing them most efficiently is best for your application. Whatever the use case, it's safe to say that an event streaming approach is the best approach for handling events. In this blog post, we will build an event streaming application using Apache Kafka®, the .NET producer and consumer clients, and the from Microsoft. At first glance, you might not automatically put all three of these together as likely candidates to work together. Sure, Kafka and the .NET clients are a great pair, but where does TPL fit into the picture? Task Parallel Library (TPL) More often than not, throughput is a key requirement and in order to avoid bottlenecks due to impedance mismatches between consuming from Kafka and downstream processing, we generally suggest in-process parallelization wherever the opportunity arises. Read on to see how all three components work together to build a robust and efficient event-streaming application. The best part is that the Kafka client and TPL take care of most of the heavy lifting; you only need to focus on your business logic. Before we dive into the application, let's give a brief description of each component. Apache Kafka If stream processing is the de facto standard for handling event streams, then is the de facto standard for building event streaming applications. Apache Kafka is a distributed log provided in a highly scalable, elastic, fault-tolerant, and secure manner. In a nutshell, Kafka uses brokers (servers) and clients. The brokers form the Kafka cluster's distributed storage layer, which can span data centers or cloud regions. Clients provide the ability to read and write event data from a broker cluster. Kafka clusters are fault-tolerant: if any broker fails, other brokers will take up the work to ensure continuous operations. Apache Kafka Confluent .NET clients I mentioned in the previous paragraph that clients either write to or read from a Kafka broker cluster. Apache Kafka bundles with Java clients, but several other clients are available, namely the .NET Kafka producer and consumer, which is at the heart of the application in this blog post. The .NET producer and consumer bring the power of event streaming with Kafka to the .NET developer. For more information on the .NET clients, consult the . documentation Task Parallel Library The Task Parallel Library( ) is "a set of public types and APIs in the System.Threading and System.Threading.Tasks namespaces," simplifying the job of writing concurrent applications. The TPL makes adding concurrency a more manageable task by handling the following details: TPL 1. Handling the partitioning of work 2. Scheduling threads on the ThreadPool 3. Low-level details such as cancellation, state management, etc. The bottom line is that using the TPL can maximize your application's processing performance while allowing you to focus on the business logic. Specifically, you'll use the subset of the TPL. Dataflow Library The Dataflow Library is an actor-based programming model that allows in-process message passing and pipelining tasks. The Dataflow components build on the types and scheduling infrastructure of the TPL and integrate seamlessly with the C# language. Reading from Kafka is usually quite fast, but processing (a DB call or RPC call) is typically a bottleneck. Any parallelization opportunities we can utilize that would achieve higher throughput while not sacrificing ordering guarantees are worth consideration. In this blog post, we'll leverage these Dataflow components along with the .NET Kafka clients to build a stream processing application that will process data as it becomes available. Dataflow blocks Before we get into the application you're going to build; we should give some background information on what makes up the TPL Dataflow Library. The approach detailed here is most applicable when you have CPU and I/O-intensive tasks that require high throughput. The TPL Dataflow Library consists of blocks that can buffer and process incoming data or records, and the blocks fall into one of three categories: Source blocks – Act as a source of data, and other blocks can read from it. Target blocks – A receiver of data or a sink, which can be written to by other blocks. Propagator blocks – Behave as both a source and target block. You take the different blocks and connect them to form either a linear processing pipeline or a more complex graph of processing. Consider the following illustrations: The Dataflow Library provides several predefined block types which fall into three categories: buffering, execution, and grouping. We're using the buffering and execution types for the project developed for this blog post. The BufferBlock<T> is a general-purpose structure that buffers data and is ideal for use in producer/consumer applications. The BufferBlock uses a first-in, first-out queue for handling incoming data. The BufferBlock (and the classes that extend it) is the only block type in the Dataflow Library that provides for directly writing and reading messages; other types expect to receive messages from or send messages to blocks. For this reason, we used a as a delegate when creating the source block and implementing the interface and the sink block implementing the interface. BufferBlock ISourceBlock ITargetBlock The other Dataflow block type used in our application is a . Like most of the block types in the Dataflow Library, you create an instance of the TransformBlock by providing a to act as a delegate that the transform block executes for each input record it receives. TransformBlock <TInput, TOutput> Func<TInput, TOutput> Two essential features of Dataflow blocks are that you can control the number of records it will buffer and the level of parallelism. By setting a maximum buffer capacity, your application will automatically apply back pressure when the application encounters a prolonged wait at some point in the processing pipeline. This back pressure is necessary to prevent an over-accumulation of data. Then once the problem subsides and the buffer decreases in size, it will consume data again. The ability to set the concurrency for a block is critical for performance. If one block performs a CPU or I/O intensive task, there’s a natural tendency to parallelize work to increase the throughput. But adding concurrency can cause a problem—processing order. If you add threading to a block's task, you can't guarantee the output order of the data. In some cases, the order won't matter, but when it does matter, it's a severe trade-off to consider: higher throughput with concurrency versus processing order output. Fortunately, you don't have to make this trade-off with the Dataflow Library. When you set the parallelism of a block to more than one, the framework guarantees that it will maintain the original order of the input records (note that maintaining order with parallelism is configurable, with the default value being true). If the original order of data is A, B, C, then the output order will be A, B, C. Skeptical? I know I was, so I tested it and discovered that it worked as advertised. We'll talk about this test a little later in this post. Note that increasing the parallelism should only be done with operations or ones that are , meaning that changing the order or grouping of operations won’t affect the result. stateless stateful associative and commutative At this point, you can see where this is going. You have a Kafka topic representing events you need to handle in the fastest way possible. So you're going to build a streaming application comprised of a source block with a .NET KafkaConsumer, processing blocks to accomplish the business logic, and a sink block containing a .NET KafkaProducer to write the final results back to a Kafka topic. Here's an illustration of a high-level view of the application: The application will have the following structure: Source block: Wrapping a .NET KafkaConsumer and a delegate BufferBlock Transform block: Deserialization Transform block: Mapping incoming JSON data to purchase object Transform block: CPU-intensive task (simulated) Transform block: Serialization Target block: Wrapping a .NET KafkaProducer and delegate BufferBlock Next is a description of the overall flow of the application and some critical points about leveraging Kafka and the Dataflow Library for building a powerful event-streaming application. An event streaming application Here's our scenario: You have a Kafka topic that receives records of purchases from your online store, and the incoming data format is JSON. You want to process these purchase events by applying ML inferencing to the purchase details. Additionally, you'd like to transform the JSON records into Protobuf format, as this is the company-wide format for data. Of course, throughput for the application is essential. The ML operations are CPU intensive, so you need a way to maximize the application throughput, so you'll take advantage of parallelizing that portion of the application. Consuming data into the pipeline Let's tour the critical points of the streaming application, starting with the source block. I mentioned implementing the interface before, and since the also implements , we'll use it as a delegate to satisfy all the interface methods. So the source block implementation will wrap a KafkaConsumer and the BufferBlock. Inside our source block, we'll have a separate thread whose sole responsibility is for the consumer to pass the records it has consumed into the buffer. From there, the buffer will forward records to the next block in the pipeline. ISourceBlock BufferBlock ISourceBlock Before forwarding the record into the buffer, the (returned by the call) is wrapped by a abstraction that, in addition to the key and value, captures the original partition and offset, which is critical for the application—and I'll explain why shortly. It's also worth noting the entire pipeline works with the abstraction, so any transformations result in a new object wrapping the key, value, and other essential fields like the original offset preserving them through the entire pipeline. ConsumeRecord Consumer.consume Record Record Record Processing blocks The application breaks down processing into several different blocks. Each block links to the next step in the processing chain, so the source block links to the first block, which handles deserialization. While the .NET KafkaConsumer can handle the deserialization of records, we have the consumer pass on the serialized payload and deserialize in a Transform block. Deserialization can be CPU intensive, so putting this into its processing block allows us to parallelize the operation if necessary. After the deserialization, the records flow into another Transform block that converts the JSON payload into a Purchase data model object in Protobuf format. The more interesting part comes when the data goes into the next block, representing a CPU-intensive task required to fully complete the purchase transaction. The application simulates this part, and the supplied function sleeps with a random time of anywhere between one to three seconds. This simulated processing block is where we leverage the Dataflow block framework's power. When you instantiate a Dataflow block, you provide a delegate Func instance it applies to each record it encounters and an instance. I mentioned configuring the Dataflow blocks before, but we'll review them quickly here again. contains two essential properties: the max buffer size for that block and the max degree of parallelization. ExecutionDataflowBlockOptions ExecutionDataflowBlockOptions While we set the buffer size configuration for all the blocks in the pipeline to 10,000 records, we stick with the default parallelization level of 1, except for our simulated CPU intensive, where we set it to 4. Note that the default Dataflow buffer size is unlimited. We'll discuss the performance implications in the next section, but for now, we'll complete the application overview. The intensive processing block forwards to a serializing transform block which feeds the sink block, which then wraps a .NET KafkaProducer and produces the final results to a Kafka topic. The sink block also uses a delegate and a separate thread for producing. The thread retrieves the next available record from the buffer. Then it calls the method passing in an delegate wrapping the —the producer I/O thread will execute the delegate once the produce request completes. BufferBlock KafkaProducer.Produce Action DeliveryReport Action That completes the high-level walkthrough of the application. Now, let's discuss a crucial part of our setup—how to handle committing offsets—which is vital given that we are pipelining records from the consumer. Committing offsets When processing data with Kafka, you'll periodically commit offsets (an offset is the logical position of a record in a Kafka topic) of the records your application has successfully processed up to a given point. So why does one commit the offsets? That's an easy question to answer: when your consumer shuts down either in a controlled manner or from error, it will resume processing from the last known committed offset. By periodically committing the offsets, your consumer won't reprocess records or at least a minimal amount should your application shut down after processing a few records but committing. This approach is known as at least once processing, which guarantees records are processed at least once, and in the case of errors, maybe some of them get reprocessed, but that is a great option when the alternative is to risk data loss. Kafka also provides exactly-once processing guarantees, and while we won't get into transactions in this blog post, you can read more about transactions in Kafka in . before this blog post While there are several different ways to commit offsets, the simplest and most basic is the auto-commit approach. The consumer reads records, and the application processes them. After a configurable amount of time passes (based on record timestamps), the consumer will commit the offsets of the already consumed records. Usually, auto-committing is a reasonable approach; in a typical consume-process loop, you won't return to the consumer until you've successfully processed all the record(s) previously consumed. Had there been an unexpected error or shutdown, the code never returns to the consumer, so no commit occurs. But in our application here, we're pipelining—we take consumed records and push them into a buffer and return to consume more—there's no waiting for successful processing. , which tasks a single parameter—a —and stores it (along with other offsets) for the next commit. Note that contrasts how auto-committing works with the Java API. With the pipelining approach, how do we guarantee at-least-once processing? We'll leverage the method IConsumer.StoreOffset TopicPartitionOffset this approach to offset management So the commit procedure operates this way: when the sink block retrieves a record for producing to Kafka, it also provides it to the Action delegate. When the producer executes the callback, it passes the original offset to the consumer (the same instance in the source block), and the consumer uses the StoreOffset method. You still have auto-commit enabled for the consumer, but you're providing the offsets to commit versus having the consumer blindly commit the latest offsets it's consumed up to this point. So even though the application uses pipelining, it commits only after receiving an ack from the broker, meaning the broker and the minimum set of replica brokers have stored the record. Working this way allows the application to progress faster as the consumer can continually fetch and feed the pipeline while the blocks perform their work. This approach is possible because the .NET consumer client is thread-safe (some methods aren't and are documented as such), so we can have our single consumer safely working in both the source and sink block threads. For any error during the producing stage, the application logs the error and puts the record back into the nested so the producer will retry sending the record to the broker. But this retry logic is done blindly, and in practice, you’ll probably want a more robust solution. BufferBlock Performance implications Now that we've covered how the application works, let's look at performance numbers. All tests were executed locally on a macOS Big Sur (11.6) laptop, so your mileage may vary in this scenario. The performance test setup is straightforward: Produce 1M records to a Kafka topic in JSON format. This step was done ahead of time and was not included in the test measurements. Start the Kafka Dataflow-enabled application and set parallelization across all the blocks to 1 (the default) The application runs until it has successfully processed 1M records, then it shuts down Record the time it took to process all records The only difference for the second round was setting the MaxDegreeOfParallelism for the simulated CPU-intensive block to four. Here are the results: Number of Records Concurrency Factor Time (minutes) 1M 1 38 1M 4 9 So by simply setting a configuration, we significantly improved throughput while maintaining event order. So by enabling a max degree of parallelism to four, we get the expected speed-up by a factor greater than four. But the critical part of this performance improvement is that you didn't write any concurrent code, which would be difficult to do correctly. Earlier in the blog post, I mentioned a test to validate that concurrency with Dataflow blocks preserves event order, so let's talk about that now. The trial involved the following steps: Produce 1M integers (0-999,999) to a Kafka topic Modify the reference application to work with integer types Run the application with a concurrency level of one for the simulated remote process block—produce to a Kafka topic Rerun the application with a concurrency level of four and produce the numbers to another Kafka topic Run a program to consume the integers from both result topics and store them in an array in memory Compare both arrays and confirm they are in identical order The result of this test was that both arrays contained the integers in order from 0 to 999,999, proving that using a Dataflow block with a level of parallelism of more than one did maintain the processing order of the incoming data. You can find more detailed information on Dataflow parallelism in the . documentation Summary n this post, we introduced how to use .NET Kafka clients and the Task Parallel Library to build a robust, high-throughput event streaming application. Kafka provides high-performance event streaming, and the Task Parallel Library gives you the building blocks for creating concurrent applications with buffering to handle all the details, allowing developers to focus on the business logic. While the scenario for the application is a bit contrived, hopefully, you can see the usefulness of combining the two technologies. Give it a try— . I here’s the GitHub repository Also published here.