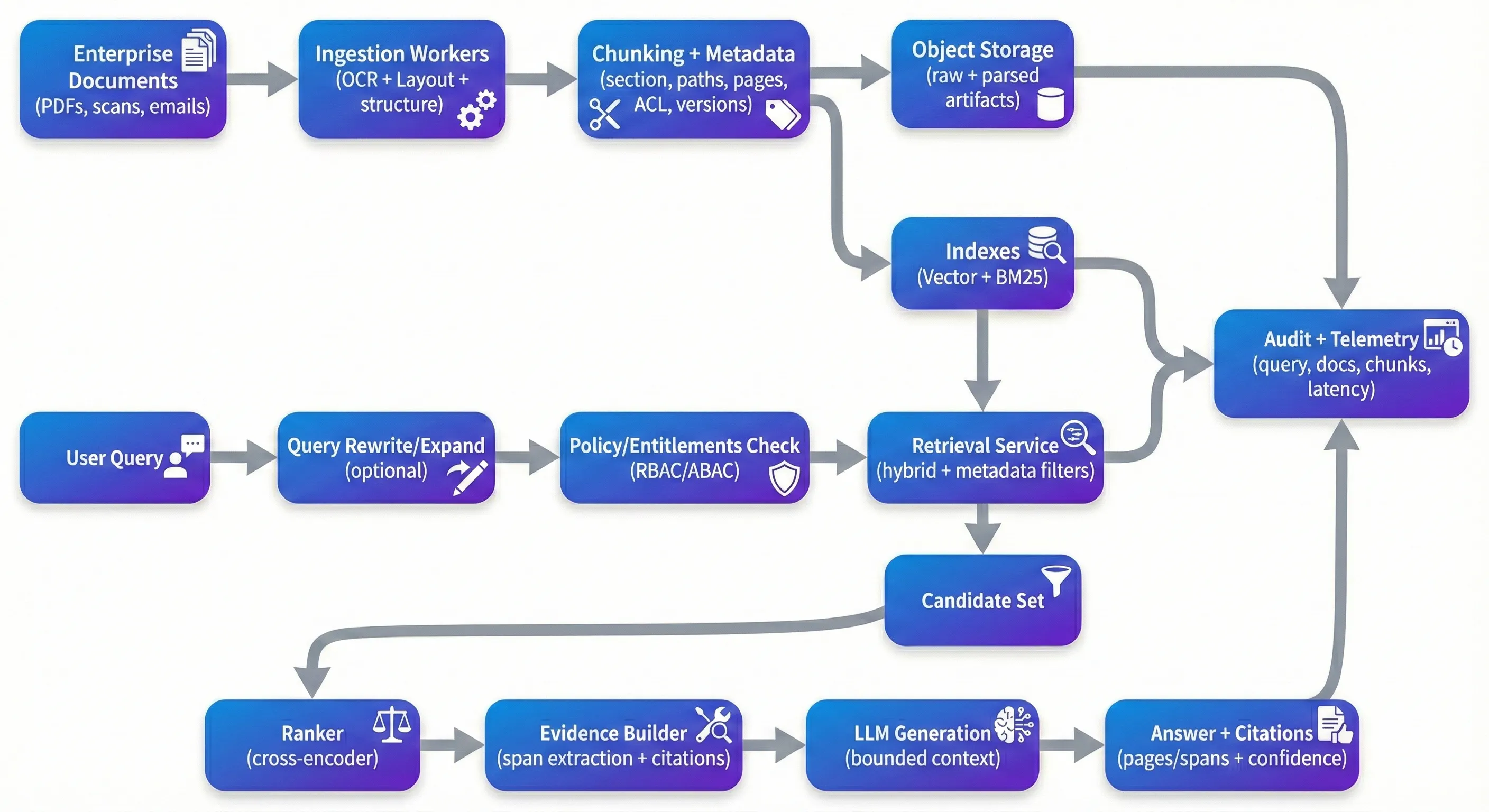
RAG є скрізь — і це не дивно. Це один з найбільш практичних способів зробити великі колекції документів доступними для пошуку, не будуючи крихких, доменних аналітиків для кожного типу запитання. Зловживання полягає в тому, що те, що працює в контрольованому демо, часто швидко деградується, коли ви ставите його перед реальними корпоративними PDF-файлами: скановані контракти, файли відповідності, медичні записи, політики та довгий хвіст проблем з оформленням та якістю, які приходять з ними. Коли команди застрягають, це рідко відбувається через те, що пошук векторів «не працює». Це тому, що система не може послідовно обгрунтувати відповіді на правильні докази, не може надійно здійснити права, або не може бути оцінено і поліпшено, не порушуючи речі. Якщо ви не можете сказати зацікавленим особам, яка версія документа підтримувала заяву — або довести, що користувач був уповноважений переглядати її — у вас ще немає продукту. The Demo Trap Створення Demo Trap Більшість прототипів слідують тому ж шляху: викидають документи в векторний магазин, отримують топ-к шматочки і просять LLM синтезувати. На чистому, добре структурованому тексті, що може виглядати чудово. Проблема полягає в тому, що відбувається далі. Скановані PDF-файли приходять в повороті або зіпсованому порядку. Порядок читання в декількох стовпцях стає незмінним. Таблиці втрачають структуру під час вилучення. Чункінг розділяє середину аргументу. Вилучення повертає "досить близько" контекст, який читає правдоподібно, але насправді не підтримує твердження. І модель, роблячи те, що оптимізовано для цього, відповідає рівномірно У виробництві ви оптимізуєте для різних властивостей, ніж демонстрація.Ви хочете, щоб система була надійною над безладними входами, відтворюваною через зміни трубопроводу і захищеною під контролем.Це означає, що ви можете відстежувати відповідь назад до конкретних доказів, і мати сильні недоліки, коли докази слабкі: уточнюючи питання, відмову поведінку, або представляючи "кращі доступні докази" з явною невизначеністю. Ingestion: Where Quality Is Won or Lost Вживання: де якість виграна або втрачена Якщо ви побудували кілька з цих систем, ви швидко дізнаєтеся, що поглинання визначає якість відновлення більше, ніж більшість наступних хитрощів. Передобробка документа AI не є чарівною, але це те, де ви або зберігаєте структуру, або втрачаєте її назавжди. Для корпоративних документів, OCR наодинці не достатньо; ви зазвичай потребуєте OCR з виявленням розташування, реконструкцією порядку читання та вилученням структури, що тримає заголовки, розділи та таблиці значущими. Управлінні інструменти, такі як Google Document AI, Azure Document Intelligence та Amazon Textract, можуть охоплювати багато землі. Чункінг - це місце, де команди часто недооцінюють складність. Просте поділ символів або токенів відбувається швидко, але він має тенденцію перетинати семантичні межі - саме межі, про які користувачі дбають у контрактах та політиках. Адаптивне чункінг, що слідує за заголовками, межами розділу та межами таблиці, зазвичай покращує як пошук, так і заземлення внизу. Це також робить походження природним для кінцевого користувача: замість того, щоб виставляти непростий внутрішній ID, як chunk_4892, ви можете вказувати на те, що рецензент може негайно перевірити - "MSA v3.2 → Розділ 9 (закінчення) → 9.2 (закінчення причини), сторінка Метадані є ще однією областю, яка, як правило, виглядає опціональною, поки вам не знадобиться. На практиці метадані є тим, що дозволяє фільтрувати, відстежувати та відтворювати. Корисні метадані на рівні дрібниці зазвичай включають ідентифікатори документів, шляхи розділів, номери сторінок, часові штампи (ефективна дата, остання модифікована, введена), сигнали довіри до вилучення та ідентифікатори версій (хеш-документ, версія шункірування, версія моделі вбудови). У корпоративних контекстах атрибути управління доступом (орендар, відділ, конфіденційність, теги ролей) повинні бути першокласними, тому що вони безпосередньо The Retrieval Stack That Actually Works Стіл відновлення, який насправді працює Пошук схожості векторів є хорошим початком, але він рідко достатньо сам по собі для корпоративних документів. На практиці гібридне пошук - щільні вбудовані та рідкісні лексичні пошуки, такі як BM25 - як правило, більш міцні, особливо коли користувачі запитують з номерами пунктів, ідентифікаторами, абревіатурами або точними фразами. Переоцінка часто є місцем, де системи роблять найбільший стрибок у сприйнятій якості, не тому, що це магічно, а тому, що воно виправляє загальний режим невдачі: початковий набір пошуку містить "кінда-релевантні" шматочки, і вам потрібно просувати справді релевантні до вершини. Переоцінки крос-кодерів (відкриті моделі, такі як bge-reranker або керовані API, такі як Cohere ranker) переоцінюють шматочки кандидатів за допомогою більш глибокої взаємодії запит-перехід. Команди зазвичай бачать помітний підйом в точності контексту, коли переоцінка вимірюється належним чином (наприклад, на золотому наборі з очікуваними джере Перезаписування запитів і розширення є ще одним важелем, який легко пропустити рано, а потім знову відкрити пізніше. Користувачі природно не висловлюють запитання так, як пишуться документи. Крок перезапису може розширити абревіатури, нормалізувати суб'єкти та розділити багаточасові запитання на дружні для пошуку підпошуки. Він не повинен бути фантастичним - але він потребує спостережуваності, тому що неконтрольоване перезаписування може відволікати від наміру користувача. Security: The Layer Everyone Forgets Безпека: шар, про який всі забувають Більшість демонстрацій RAG ігнорують контроль доступу, тому що він сповільнює прототип.У виробництві це є основним обмеженням.Якщо ваша система індексує документи HR, юридичні контракти та інженерні специфікації разом, вам потрібен детерміністичний шлях права від користувача → дозволені шматочки, а відновлення має бути обмеженим цим шляхом, перш ніж будь-який вміст досягне LLM. Модель, яка має тенденцію до масштабування, є попередньо фільтрованим пошуком: обчислювальні права (RBAC / ABAC), завантажуйте тільки з шматків з сумісними атрибутами ACL, перев'яжіть в рамках набору авторизованих кандидатів і реєструйте, які докази були доступні.Це також місце, де в практиці з'являється точка "метадані не є факультативними" - без маркування на рівні шматків, ви закінчуєте з витоковими межами або дорогими, крихкими пост-фільтрами. Крім ACL, корпоративні розгортання, як правило, потребують деякої комбінації виявлення / маскування PII, шифрування в режимі відпочинку, короткочасних токенів для доступу до джерела та аудитного журналу, який захоплює запити, вилучені частинки ідентифікаторів, цитати та версії документів. Ще однією сучасною проблемою, яку варто серйозно взяти, є швидке введення вмісту всередині документів. Monitoring: Closing the Loop Моніторинг: закриття ланцюга Якщо ви експлуатуєте одну з цих систем більше декількох тижнів, ви побачите дрейф. Документи змінюються, розподіл запитів змінюється, змінюється трубопровід поглинання, а компоненти моделі оновлюються. Практично, ви хочете відслідковувати стан здоров'я (recall@k проти золотого набору, точність контексту, реранкер), стан здоров'я (точність цитування, перевірки наземності / вірності, показники відмови) та стан здоров'я операцій (p50 / p95 затримка, вартість за запит, затримка вживання від оновлення документів до пошукового індексу). Найефективніші команди, які я бачив, підтримують золотий набір даних оцінки - виправлені питання з очікуваними джерельними документами - і запускають його за графіком і на події зміни (нові вбудовані, нова логіка розбивання, нові партії документів). Інструменти, такі як Phoenix, TruLens або комерційні платформи можуть допомогти, Однією з областей, яка часто недооцінюється, є версії та відтворення. Коли ви змінюєте моделі OCR, хронізуєте логіку, вбудовуєте моделі, реранкеруєте або генеруєте вказівки, вам потрібен спосіб відстежити, які версії виробляються, які відповіді. Choosing Your Stack Вибираємо свій стек Для багатьох команд налаштування з керуванням є привабливим: поглинання через інструмент з керованим інтелектуальним інтелектом Document AI або трубопровід на основі Unstructured, базу даних векторів, шар оркестрування, такий як LlamaIndex або LangChain, і реранкер (відкритий або керований). Інші вважають за краще розгортання з відкритим кодом за допомогою Qdrant/Weaviate/OpenSearch, Haystack або аналогічної оркестрування, а також самохостингові моделі для контролю та прогнозування витрат. Будь-який підхід може працювати, якщо він підтримує основи: поглинання документів, гібридне відновлення, правоздаткове застосування, дружні з походженням цитати, оцінкові трубопроводи З архітектурної сторони, системи, як правило, стають легше працювати, коли вони розділені чисто: поглинаючі працівники, які працюють асинхронно і можуть бути безпечно перезавантажені; служба бездержавного пошуку, яка здійснює політики і повертає докази; і служба генерації, яка працює з обмеженим контекстом і чітким походженням. Типовий розгортання посилання включає API gateway, черга роботи (Kafka / RabbitMQ), об'єкт зберігання для сирових документів і парсованих артефактів, індексний шар ( +dense sparse), плюс централізований logging / metrics і аудиторський трек.