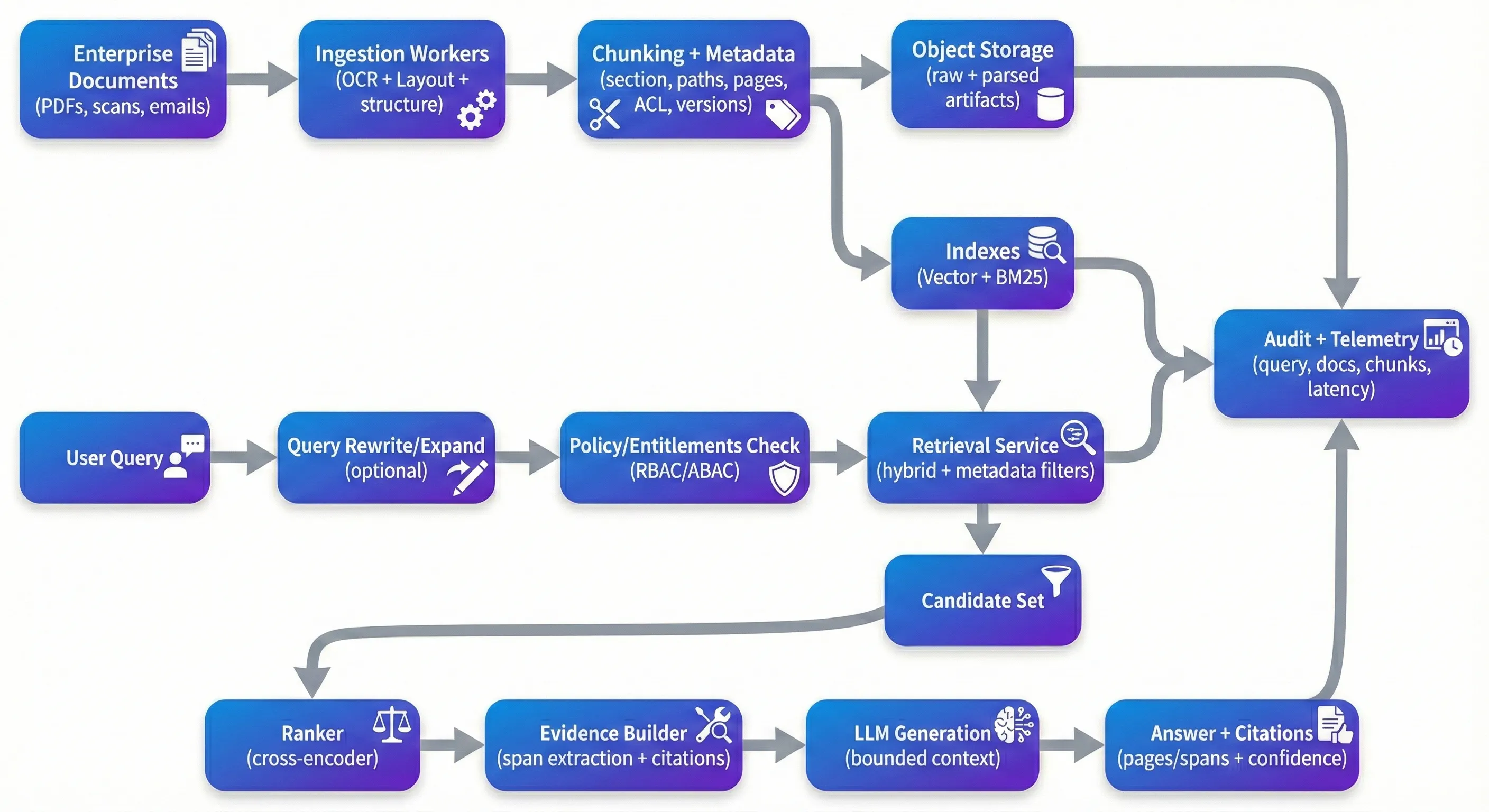
RAG är överallt – och det är inte förvånande. Det är ett av de mest praktiska sätten att göra stora dokumentsamlingar sökbara utan att bygga bräckliga, domänspecifika analyser för varje typ av fråga. Fångsten är att det som fungerar i en kontrollerad demo ofta försämras snabbt när du lägger den framför riktiga företags PDF-filer: skannade kontrakt, överensstämmelse filer, medicinska register, policyer, och den långa svansen av layout och kvalitetsproblem som följer med dem. I produktion handlar "RAG-problemet" mindre om smart uppmaning och mer om repeterbarhet: spårbarhet, säkerhet, kvalitetskontroller och förmågan att förklara varför ett svar är korrekt (eller varför systemet vägrade). Det beror på att systemet inte konsekvent kan grunda svar på rätt bevis, inte kan verkställa rättigheter på ett tillförlitligt sätt eller inte kan utvärderas och förbättras utan att bryta saker.Om du inte kan berätta för en intressent vilken version av vilket dokument som stödde ett påstående - eller bevisa att användaren var behörig att se det - har du inte en produkt ännu. The Demo Trap Demo Fällan De flesta prototyper följer samma väg: droppa dokument till en vektorbutik, hämta topp-k-bitar och be en LLM att syntetisera. På ren, välstrukturerad text kan det se bra ut. Problemet är vad som händer nästa. Skannade PDF-filer kommer i roterande eller förvrängda. Flera kolumner läser ordning blir skrämmande. Tabeller förlorar struktur under utvinning. Chunking splittrar mitten av argumentet. Retrieval returnerar "tillräckligt nära" sammanhang som läser trovärdigt men stöder inte faktiskt påståendet. Och modellen, som gör vad den är optimerad för att göra, svarar flytande ändå. I produktionen optimerar du för olika egenskaper än en demo. Du vill att systemet ska vara tillförlitligt över rörliga inmatningar, reproducerbart över rörledningsändringar och försvarbart under granskning. Det betyder att kunna spåra ett svar tillbaka till specifika bevis och ha starka standard när bevisen är svaga: klargörande frågor, vägran beteende, eller presenterar "bästa tillgängliga bevis" med explicit osäkerhet. Ingestion: Where Quality Is Won or Lost Intag: där kvaliteten vinner eller förlorar Om du har byggt några av dessa system lär du dig snabbt att intag bestämmer återvinningskvaliteten mer än de flesta nedströmstricks. Dokument AI-förbearbetning är inte glamorös, men det är där du antingen bevarar strukturen – eller förlorar den permanent. För företagsdokument är OCR ensam inte tillräckligt; du behöver vanligtvis OCR med layoutdetektering, läsordskonstruktion och strukturutvinning som håller rubriker, avsnitt och tabeller meningsfulla. Hanterade verktyg som Google Document AI, Azure Document Intelligence och Amazon Textract kan täcka en hel del mark. Open-source-rörledningar som Unstructured och GROBID är vanliga när du behöver transparens eller stramare kontroll över parande beslut. Chunking är där team ofta underskattar komplexiteten. En enkel karaktärsdelning eller tokendelning är snabb, men den tenderar att skära över semantiska gränser – exakt de gränser som användarna bryr sig om i kontrakt och policyer. Adaptiv chunking som följer rubriker, sektionsgränser och tabellgränser förbättrar vanligtvis både hämtning och nedströmsjordning. Det gör också att ursprunget känns naturligt för slutanvändaren: i stället för att visa en opac intern ID som chunk_4892, kan du peka på något som en granskare kan genast verifiera – ”MSA v3.2 → Avsnitt 9 (Slut) → 9.2 (Slut för Orsak), sida 12, raderna 14–22.” Metadata är ett annat område som tenderar att se valfritt tills du behöver det. I praktiken är metadata det som gör filtrering, spårbarhet och reproducerbarhet möjligt. Användbara metadata på bråknivå inkluderar vanligtvis dokument-ID: er, avsnittsvägar, sidnummer, tidsstämplar (effektivt datum, senast modifierat, intagit vid), utvinningssäkerhetssignaler och versionskoder (dokumenthash, chunking version, inbäddad modellversion). I företagssammanhang måste tillgångskontrollattribut (hyresgäst, avdelning, sekretess, rolltaggar) vara förstklassiga, eftersom de direkt begränsar hämtning och revisioner. The Retrieval Stack That Actually Works Retrieval Stack som faktiskt fungerar Vektorlikhetssökning är en bra baslinje, men det är sällan tillräckligt på egen hand för företagsdokument. I praktiken, hybrid retrieval - täta inbäddningar plus sparsam lexikal retrieval som BM25 - tenderar att vara mer robust, särskilt när användare frågar med klausulnummer, identifierare, akronymer eller exakt frasning. Omklassificering är ofta där system gör det största språnget i uppfattad kvalitet, inte för att det är magiskt, utan för att det fixar ett vanligt felläge: den inledande sökningen innehåller "kinda relevanta" bitar, och du behöver främja de riktigt relevanta till toppen. Cross-encoder-omklassificeringar (öppna modeller som bge-reranker eller hanterade API: er som Cohere ranker) omklassificerar kandidatdelar med hjälp av djupare fråge-passage-interaktion. Teams ser vanligtvis en märkbar höjning i kontextprecision när omklassificering mäts korrekt (till exempel på en gyllene uppsättning med förväntade källor). Om du håller ett kvantitativt påstående här, är det bäst att binda det till en metrik ("kontext Frågeöversättning och expansion är en annan hävstång som är lätt att hoppa över tidigt och sedan återupptäcka senare. Användare uttrycker inte naturligt frågor på det sätt som dokument skrivs. Ett omskrivningssteg kan utöka akronymer, normalisera enheter och dela upp flerdelade frågor i sökvänliga underfrågor. Det behöver inte vara snyggt - men det behöver observerbarhet, eftersom okontrollerad omskrivning kan driva bort från användarens avsikt. Security: The Layer Everyone Forgets Säkerhet: Lagret alla glömmer De flesta RAG-demon ignorerar åtkomstkontroll eftersom det saktar ner prototypen. I produktionen är det en primär begränsning. Om ditt system indexerar HR-dokument, juridiska avtal och tekniska specifikationer tillsammans, behöver du en deterministisk rättighetsväg från användaren → tillåtna bitar, och hämta måste begränsas av den vägen innan något innehåll når en LLM. Det mönster som tenderar att skala är förfiltrerad upptäckt: beräkningsrättigheter (RBAC/ABAC), hämta endast från bitar med kompatibla ACL-attribut, omarkera inom den auktoriserade kandidatuppsättningen och logga vilket bevis som nåddes. Bortsett från ACL, behöver företagsutplaceringar vanligtvis en kombination av PII-detektering / maskering, kryptering vid vila, kortlivade tokens för källåtkomst och auditloggning som fångar frågor, hämtade delade ID: er, citat och dokumentversioner. En mer modern oro värt att ta på allvar är omedelbar injektion av innehåll inuti dokument. Du behöver inte behandla varje dokument som fientligt, men du behöver grundläggande skyddsfält så att instruktioner inbäddade i källtext inte kan ersätta ditt systems regler - särskilt kring åtkomst, kontroll och hur modellen får bete sig. Monitoring: Closing the Loop Övervakning: Stängning av loop Om du har använt ett av dessa system i mer än några veckor kommer du att se drift. Dokument ändras, frågans distribution ändras, intagsröret ändras och modellkomponenterna uppdateras.Utan övervakning och utvärdering försämras kvaliteten tyst tills användarna slutar lita på verktyget. I grund och botten vill du spåra återhämtningshälsa (recall@k mot en gyllene uppsättning, kontextprecision, rangerare lyft), generationshälsa (citatprecision, grundlighet / trohetskontroller, avvisningsfrekvenser) och operativa hälsa (p50 / p95 latens, kostnad per fråga, intag fördröjd från dokumentuppdatering till sökbar index). De mest effektiva team jag har sett upprätthålla en gyllene utvärderingsdataset - utvärderade frågor med förväntade källdokument - och köra den på ett schema och på förändringsevenemang (nya inbäddningar, ny chunking logik, nya dokumentpartier). Verktyg som Phoenix, TruLens eller kommersiella plattformar kan hjälpa, men den Ett område som ofta underskattas är versionering och reproducerbarhet.När du ändrar OCR-modeller, chunking logik, inbäddade modeller, omrankare eller genereringspåminnelser behöver du ett sätt att spåra vilka versioner som producerats vilka svar. Choosing Your Stack Välj din stack Stackbeslut spelar roll, men förmågor spelar mer roll. För många team är en hanterad inställning attraktiv: intag via ett hanterat dokument AI-verktyg eller en strukturerad pipeline, en värdvektordatabas, ett orkestreringslag som LlamaIndex eller LangChain och en omrankare (öppen eller hanterad). Andra föredrar öppen källkodsutplaceringar med Qdrant/Weaviate/OpenSearch, Haystack eller liknande orkestrering och självhostade modeller för kontroll och kostnadsprognoser. Båda metoderna kan fungera om de stöder grunderna: dokumentmedveten intag, hybridåtervinning, rättstillämpning, källvänliga citat, utvärderingsrör och versionering. På arkitekturens sida tenderar system att bli lättare att arbeta när de är uppdelade rent: intagsarbetare som körs asynkront och kan återställas säkert; en stateless retrieval-tjänst som verkställer policyer och returnerar bevis; och en genereringstjänst som fungerar med begränsad kontext och tydlig ursprung. en typisk referensutplacering inkluderar en API-gateway, en jobbskede (Kafka/RabbitMQ), objektlagring för rådokument och parserade artefakter, indexskiktet ( +dense sparse), plus centraliserad loggning/metrik och en auditspår.