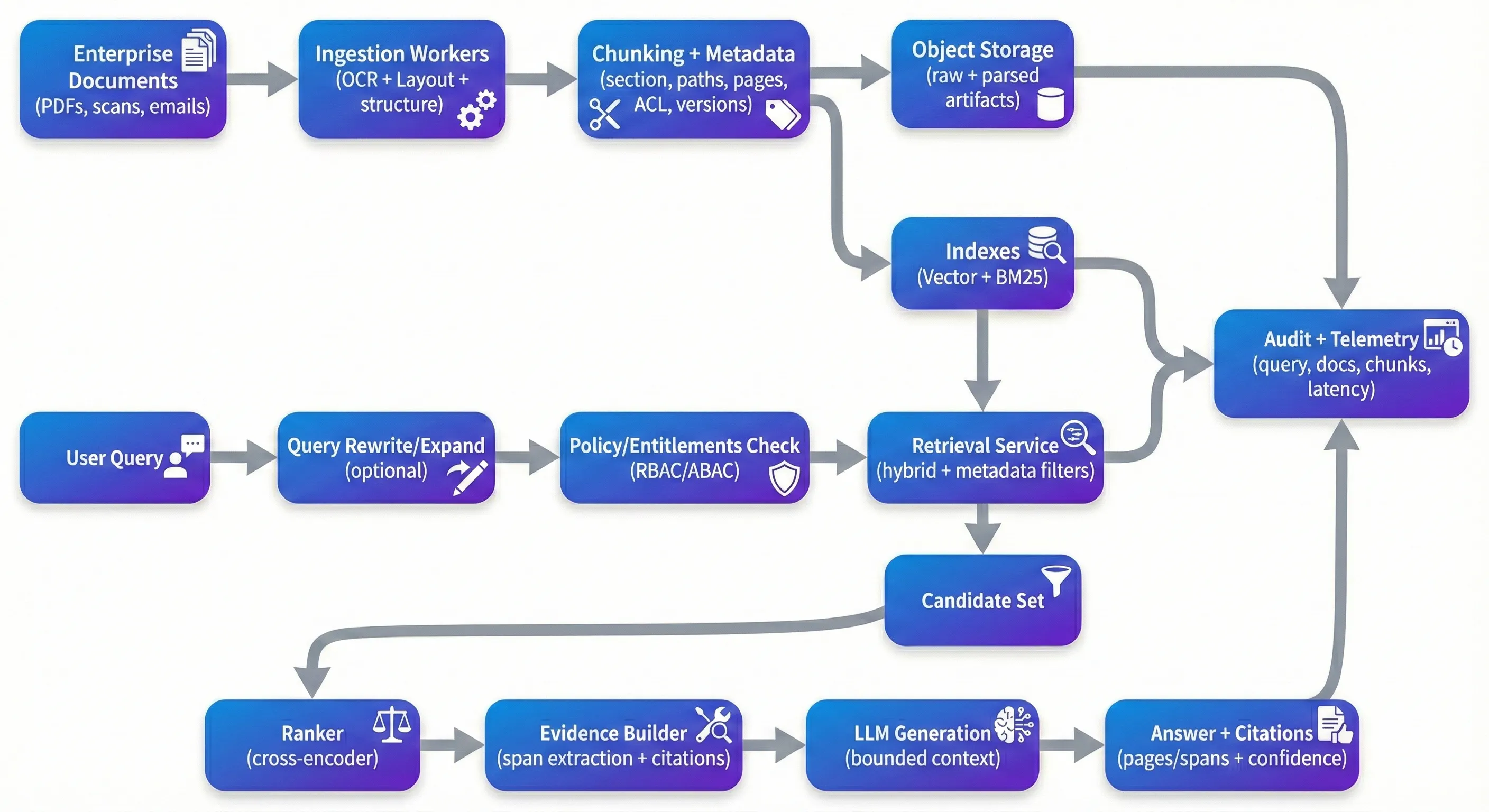
RAG her yerde - ve bu şaşırtıcı değil. Büyük belge koleksiyonlarını, her soru türü için kırılgan, alan adli analizörler oluşturmadan arama yapmanın en pratik yollarından biridir. Çekim, kontrol edilen bir demo'da çalıştığınız şeyin, gerçek kurumsal PDF'lerin önüne koyduğunuzda genellikle hızlı bir şekilde bozulduğudur: tarama sözleşmeleri, uyumluluk dosyaları, tıbbi kayıtlar, politikalar ve bunlarla birlikte gelen boyama ve kalite sorunlarının uzun sırrı. Üretimde, "RAG sorunu" zeki çağrı hakkında daha az ve daha fazla: izlenebilirlik, güvenlik, kalite kontrolleri ve neden bir cevap doğru (veya sistemin neden reddedildiğini) açıklamak için yeteneği. Ekiplerin sıkıştığı zaman, nadiren vektor arama “işe yaramıyor” çünkü sistem sürekli olarak doğru kanıtlara yanıt veremiyor, hakları güvenilir bir şekilde yürütemiyor ya da işleri kırmadan değerlendirip iyileştirilemiyor. eğer bir ilgiliye hangi belgenin hangi sürümünü desteklediğini söyleyemiyorsanız – ya da kullanıcının bunu görmeye yetkili olduğunu kanıtlamıyorsanız – henüz bir ürüne sahip değilsiniz. The Demo Trap Demo Tuzağı Çoğu prototip aynı yoldan gidiyor: belgeleri bir vektör mağazasına atın, üst düzey parçaları alın ve bir LLM'yi sentezlemek için isteyin. Temiz, iyi yapılandırılmış metinde, bu mükemmel görünebilir. Sorun bir sonraki olaydır. Tarama PDF'ler döndürülmüş veya sapmış olarak gelir. Çok sütunlu okuma sırası karışık olur. Tablolar ekstraksiyon sırasında yapıyı kaybeder. Chunking argümanın ortasına bölünür. Retrieval, iddiayı gerçekte desteklemeyen ancak "yeterince yakın" bağlamı geri verir. Ve model, yapılması için optimize edilmiş olanı yaparken, her durumda akıcı bir şekilde yanıt verir. Üretimde, bir demo'dan farklı özellikler için optimizasyon yapıyorsunuz. sistemin karmaşık girişler üzerinde güvenilir, boru hattı değişiklikleri boyunca tekrarlanabilir ve muayene altında savunabilir olmasını istiyorsunuz. Bu, belirli kanıtlara bir yanıt izleyebilmek ve kanıtların zayıf olduğunda güçlü varsayımlara sahip olmak anlamına gelir: soruların açıklanması, reddetme davranışları veya açıkça belirsiz "en iyi mevcut kanıtlar" sunmak. Ingestion: Where Quality Is Won or Lost Giriş: Nerede kalite kazanılır veya kaybedilir Bu sistemlerden birkaçını oluşturduğunuzda, çoğu aşağıdaki ipuçlarından daha fazla alım kalitesini belirlediğini hızlıca öğreneceksiniz. Belge AI ön işleme şaşırtıcı değildir, ancak yapıyı muhafaza edebileceğiniz ya da kalıcı olarak kaybedeceğiniz yer burasıdır. Kurumsal belgeler için, OCR tek başına yeterli değildir; genellikle düzen algılaması, okumaya göre yeniden yapılandırma ve başlıkları, bölümleri ve tabloları anlamlı tutan yapısal çıkarma olan OCR'ye ihtiyacınız vardır. Google Document AI, Azure Document Intelligence ve Amazon Textract gibi yönetilen araçlar çok fazla yer kaplayabilir. Unstructured ve GROBID gibi açık kaynaklı boru hattı, kararların karşılaştırılması üzerinde şeffaflık veya daha sıkı kontrol gerektirdiğinde yaygındır. Chunking, ekiplerin sık sık karmaşıklığı küçümsediği yerdir. Basit bir karakter veya token bölünmesi hızlıdır, ancak semantik sınırları aşma eğilimindedir – kullanıcıların sözleşmelerde ve politikalarda ilgilendiği sınırlar tam olarak budur. Başlıklar, bölüm sınırları ve tablo sınırlarını takip eden adaptatif chunking, genellikle hem arama hem de aşağıdaki yerleştirmeyi iyileştirir. Ayrıca, son kullanıcı için doğallığı doğal hissettirir: chunk_4892 gibi belirsiz bir iç kimliğin yüzeyine yerleştirmek yerine, bir yorumcu tarafından derhal doğrulanabilecek bir şeye işaret edebilirsiniz – “MSA v3.2 → Bölüm 9 (Sonlandırma) → 9.2 (Söz için Sonlandırma), sayfa 12, satırlar 14-22.” Metadata, pratikte, filtreleme, izlenebilirlik ve tekrarlanabilirliği mümkün kılan şeydir. Faydalı parçalı düzeyde metadata genellikle belge kimlikleri, bölüm yolları, sayfa numaraları, zaman etiketleri (etkili tarih, son değiştirilmiş, enjekte edilmiş), çıkarma güven sinyalleri ve sürüm tanımlayıcıları (doküman hash, çakma sürümü, entegre model sürümü) içerir. Kurumsal bağlamlarda, erişim kontrol özellikleri (düzen, departman, gizlilik, rol etiketleri) doğrudan arama ve denetimleri kısıtlar çünkü birinci sınıf olmalıdır. The Retrieval Stack That Actually Works Gerçekten Çalışan Retrieval Stack Vektör benzerlik arama iyi bir başlangıç noktasıdır, ancak şirket belgeleri için tek başına nadiren yeterlidir. Uygulamada, hibrit arama - sıkı yerleştirmeler ve BM25 gibi az sayıda leksik arama - özellikle kullanıcılar paragraf numaraları, tanımlayıcılar, kısaltmalar veya doğru cümlelerle sorgularken daha güçlü olmaya eğilimlidir. Yeniden sıralanma genellikle sistemlerin algılanan kalitede en büyük sıçramayı yaptığı yerdir, çünkü sihirli değil, ama yaygın bir başarısızlık modunu düzelttiği için: başlangıç arama setinde “kinda ilgili” parçalar bulunur ve gerçekten ilgili parçaları üstüne tanıtmanız gerekir. Cross-encoder re-rankerler (bge-reranker veya Cohere ranker gibi yönetilen API'ler gibi açık modeller) daha derin bir soru-gelişme etkileşimini kullanarak aday parçaları yeniden sıralanır. Takımlar genellikle yeniden sıralanma doğru ölçüldüğünde (örneğin, beklenen kaynaklarla altın bir set üzerinde). Burada bir miktarlı iddiayı tutarsanız, onu bir metrik (“kontekst hassasiyeti” veya “saygı hassasiyeti”) ve bir değerlendirme ay Soru yeniden yazma ve genişleme, daha önce atlamak ve daha sonra yeniden keşfetmek için kolay bir başka güdümdür. Kullanıcılar, belgelerin yazıldığı şekilde soruları doğal olarak ifade etmez. Yeniden yazma adımları kısayolları genişletebilir, varlıkları normalleştirebilir ve çok bölümlü soruları arama için uygun alt sorular olarak bölünebilir. Fantezi olmak zorunda değildir - ancak gözlemlenebilirlik gerektirir, çünkü kontrolsüz yeniden yazma, kullanıcının niyetinden uzaklaşabilir. Security: The Layer Everyone Forgets Etiket: herkesin unuttuğu Çoğu RAG demo erişim kontrolünü görmezden gelmez, çünkü prototipi yavaşlatır. Üretimde, bu birincil bir kısıtlamadır. Sisteminiz HR belgeleri, yasal sözleşmeler ve mühendislik özellikleri birlikte indekslerse, bir kullanıcıdan → izin verilen parçalardan belirgin bir hakaret yolu gerekir ve herhangi bir içerik bir LLM'ye ulaşmadan önce arama bu yoldan kısıtlanmalıdır. Ölçme eğiliminde olan model, önceden filtrelenmiş arama: hesaplama hakları (RBAC/ABAC), uyumlu ACL özellikleri olan parçalardan yalnızca alın, yetkili aday setinin içinde yeniden kaydedin ve hangi kanıtlara erişildiğini kaydedin. ACL'nin ötesinde, kurumsal dağıtımlar genellikle PII algılama / maskeleme, dinlenme sırasındaki şifreleme, kaynak erişimi için kısa ömürlü tokenler ve sorguları, alınan parçalı kimlikleri, referansları ve belge sürümlerini yakalayan denetim günlükleri bir kombinasyonuna ihtiyaç duyar. Daha ciddiye alınması gereken bir modern endişe, belgelerin içindeki hızlı enjeksiyon içeriğidir. Her belgeyi düşmanca olarak ele almanıza gerek yok, ancak kaynak metinde yerleştirilen talimatlar sisteminizin kurallarını - özellikle erişim, kontrol ve modelin nasıl davranılmasına izin verildiği hakkında. Monitoring: Closing the Loop Etiket: çember kapatmak Bu sistemlerden birini birkaç haftadan uzun bir süre çalıştırırsanız, drift görürsünüz. belgeler değişir, sorgu dağılımı değişir, alım boru hattı değişir ve model bileşenleri güncellenir. izleme ve değerlendirme olmadan, kullanıcılar aracı güvenmemekten vazgeçene kadar kalite sessizce bozulur. Pratik olarak, arama sağlığını (gold set, context precision, reranker lift) izlemek istiyorsunuz, üretim sağlığını (citation precision, groundedness/faithfulness check, refusal rates) ve işletme sağlığını (p50/p95 latency, per query, ingestion lag) izlemek istiyorsunuz. Gördüğüm en etkili takımlar, altın bir değerlendirme veritabanını – beklenen kaynak belgeleriyle kesilmiş sorular – tutuyor ve bir programda ve değişim olaylarında çalışıyor (yeni embeddings, yeni chunking mantık, yeni belge seri). Phoenix, TruLens veya ticari platformlar gibi araçlar yardımcı olabilir, ancak daha büyük farklılık, değerlendirmeyi güncel tutmak ve gerçek üretim olayları gibi regresyonları tedavi etmektir. Sıklıkla küçümsenen bir alan, versiyonlama ve tekrarlanabilirliktir. OCR modellerini değiştirdiğinizde, mantığı kırdığınızda, modellerini yerleştirdiğinizde, yeniden yerleştiriciler veya jenerasyon talimatlarını oluşturduğunuzda, hangi sürümlerin hangi cevapların üretildiğini takip etmenin bir yoluna ihtiyacınız vardır. Choosing Your Stack Stack’inizi seçin Stack kararlar önemlidir, ancak yetenekler daha önemlidir. Birçok ekip için, yönetilen yönlü kurulum caziptir: yönetilen bir Document AI aracı veya Yapısız tabanlı boru hattı, barındırılan bir vektor veritabanı, LlamaIndex veya LangChain gibi bir orkestrasyon katmanı ve bir yeniden sıralama (açık veya yönetilen). Diğerleri Qdrant/Weaviate/OpenSearch, Haystack veya benzer orkestrasyon kullanılarak açık kaynak dağıtımlarını ve kontrol ve maliyet tahmin edilebilirliği için kendiliğinden barındırılan modeller tercih eder. Her iki yaklaşım da temelleri desteklediği takdirde işe yarayabilir: belge bilinçli ingest, hibrit arama, hak uygulama, kaynak dostu siteleri, değerlendirme boru hattı Mimarlık tarafında, sistemler temiz bir şekilde bölünürken daha kolay çalışabilme eğilimindedir: eşzamanlı olarak çalışabilen ve güvenli bir şekilde yeniden düzenlenebilen alım işçileri; politikaları uygulayan ve kanıtları iade eden devletsiz bir arama hizmeti; ve sınırlı bağlamda ve net kaynaklarla çalışan bir jenerasyon hizmeti. tipik bir referans dağıtımı bir API kapısı, bir iş sırası (Kafka/RabbitMQ), ham belgeler ve analiz edilen eserler için nesne depolama, indeks tabakası ( +dense sparse), artı merkezli logging/metrik ve bir denetim izi içerir.