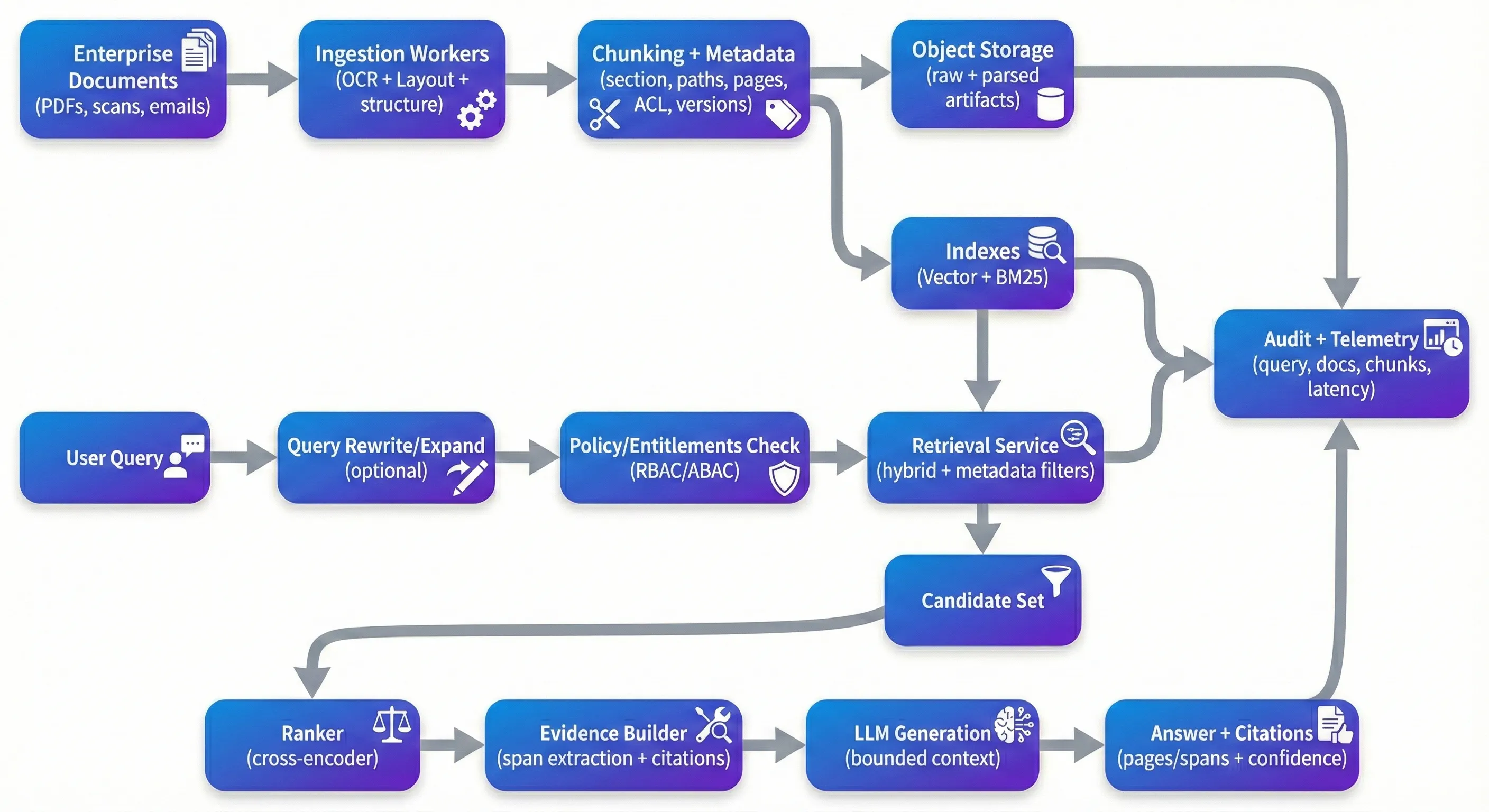
Ito ay isa sa mga pinaka-praktisyo na paraan upang lumikha ng mga malaking mga koleksyon ng dokumento kung hindi mo bumuo ng brittle, domain-specific parsers para sa bawat uri ng tanong. Ang pagkuha ay na ang kung ano ang gumagana sa isang kontrolado na demo ay karaniwang mababago nang mabilis kapag inilagay ito sa harap ng mga tunay na enterprise PDFs: scanned contracts, compliance filings, medical records, policies, at ang long tail ng layout at kalidad na mga isyu na kasama ang mga ito. Sa produksyon, ang "RAG problem" ay hindi tungkol sa smart prompting at higit pa tungkol sa repetitiveness: traceability, security, quality controls, at ang kakayahan upang ilarawan kung bakit ang isang solusyon ay sahig (o kung bakit ang sistema ay pinags Kapag ang mga team ay nakaupo, ito ay karaniwang dahil ang vector search ay "hindi gumagana." Ito ay dahil ang sistema ay hindi maaaring consistently mag-alok ng mga solusyon sa mga katotohanan, hindi maaaring ipatupad ang mga hakbang na reliably, o hindi maaaring i-evaluate at i-improve nang hindi lumaki ang mga bagay. Kung hindi mo maaari mong sabihin sa isang stakeholder kung ano ang bersyon ng dokumento na sumusuporta sa isang claim - o i-prove ang user ay nakatuon upang makita ito - hindi mo mayroong isang produkto kahit na. The Demo Trap ang demo trap Ang karamihan ng mga prototype ay sumusunod sa parehong path: i-drop ang mga dokumento sa isang vector store, i-recover top-k chunks, at i-synthetize ang isang LLM. Sa isang malusog, malusog na teksto, na maaaring makita ang mahusay na. Ang problema ay kung ano ang nangyari sa susunod. Ang mga scanned PDF ay dumating sa rotated o distorted. Multi-column reading order ay bumabalik. Tables ay humaba ng struktural sa panahon ng extraction. Chunking split sa mid-argument. Retrieval ay nagpapakita ng "kakaibang-kakaibang" kontekstong na mag-read plausibly ngunit hindi gumagamit ng claim. At ang modelo, nagtatagumpay sa kung ano ito ay optimized upang gawin, ay tumutulong sa lahat. Sa produksyon, ikaw ay optimize para sa iba't ibang mga katangian kaysa sa isang demo. Gusto mo na ang sistema ay matatagpuan sa pag-aari ng mga input, i-replicate sa paglipas ng pipeline, at i-defendable sa ilalim ng pagsusuri. Ito ay nangangahulugan na magkaroon ng kakayahan upang i-trace ang isang solusyon sa anumang mga katangian, at may malakas na mga default kapag ang mga katangian ay mababa: paglalarawan ng mga tanong, rejection behavior, o magbigay ng "ang pinakamahusay na magagamit na katangian" na may eksplicit na katangian. Ito ay din ay nangangahulugan na magtatrabaho ang access control bilang bahagi ng pagkuha - hindi bilang isang afterthought na naka-layer sa UI. Ingestion: Where Quality Is Won or Lost Ang pag-iisip: kung saan ang kalidad ay nabawasan o nawala Kung binubuo mo ang ilang ng mga sistema na ito, malaman mo na ang pag-iisip ay nagkakaiba sa kalidad ng pag-recovery higit pa sa karamihan ng mga downstream tricks. Ang preprocessing ng Document AI ay hindi magagandang, ngunit ito ay kung saan ikaw ay nagbibigay-daan ng strukturong - o humihingi ito permanentemente. Para sa mga dokumento ng enterprise, ang OCR lamang ay hindi kailangang; kailangan mo ng OCR na may pag-detection ng layout, read-order reconstruction, at pag-extraction ng strukturong na nagbibigay-daan ang mga headings, mga seksyon, at mga tables. Managed tools tulad ng Google Document AI, Azure Document Intelligence, at Amazon Textract ay maaaring lumikha ng maraming lugar. Open-source pipelines tulad ng Unstructured at Ang Chunking ay kung saan ang mga team ay karaniwang subestimates ang kompleksidad. Ang isang simpleng character o token split ay mabilis, ngunit ito ay nagtatagumpay sa mga semantic boundaries — totoo ang mga boundaries na nag-aalok ng mga gumagamit sa mga kontrata at mga patakaran. Ang adaptive chunking na sumusunod sa mga headings, section boundaries, at table boundaries ay karaniwang mapabuti sa parehong retrieval at downstream grounding. Ito ay din ay nagpapahiwatig na ang provenance ay natutunan para sa end user: sa halip ng pag-upload ng isang opacous internal ID tulad ng chunk_4892, maaari mong ipakita sa isang bagay na ang isang reviewer ay maaaring i-verify ngayong araw—"MSA v3.2 → Section 9 ( Ang metadata ay isang iba pang lugar na tinutukoy na maging optional hanggang kailangan mo ito. Sa pangkalahatan, ang metadata ay kung ano ang gumagawa ng filtration, traceability, at reproductibility. Ang useful chunk-level metadata ay karaniwang naglalaman ng mga ID ng dokumento, mga pathway ng seksyon, mga numero ng pahina, timestamps (effective date, last modified, ingested at), extraction confidence signals, at version identifiers (document hash, chunking version, embedding model version). Sa mga konteksto ng enterprise, ang mga attributo ng access-control (mga tag, department, confidentiality, role tags) ay kailangang maging first-class, dahil sila ay direkta na mapagkukunan ang retrieval at audits. The Retrieval Stack That Actually Works Ang Retrieval Stack na Nagtatrabaho Sa Kanya ay Nagtatrabaho Ang paghahanap ng vector similarity ay isang mahusay na baseline, ngunit ito ay karaniwang sapat lamang para sa mga dokumento ng enterprise. Sa pangkalahatan, ang hybrid retrieval - dense embeddings plus sparse lexical retrieval tulad ng BM25 - ay may karaniwang mas malakas, lalo na kapag ang mga gumagamit ay mga query na may mga numero ng klauzula, mga identificer, acronyms, o eksaktong phrasing. Dense retrieval gumagana ang semantic intent well; sparse retrieval anchors sa iyo upang i-exact ang mga termino at mga karaniwang tokens na ang embeddings ay karaniwang humihingi. Ang re-ranking ay karaniwang kung saan ang mga sistema ay lumikha ng pinakamalaking pag-ranking sa pag-iisip na kalidad, hindi dahil ito ay magic, ngunit dahil ito ay i-fix ang isang karaniwang mode ng pag-iisip: ang unang set ng retrieval ay naglalaman ng "kinda-related" chunks, at kailangan mong i-promote ang mga tunay na-related sa itaas. Cross-encoder re-rankingers (open models tulad ng bge-reranker o managed APIs tulad ng Cohere ranker) rescore candidate chunks gamit ang mas mataas na query-passage interaction. Teams ay karaniwang makikita ng isang nakikita na pag-aalok sa kontekst na presyon kapag ang re-ranking ay tinatanggap na (halimbawa, sa isang golden set Ang rewriting at pag-expansion ng query ay isang iba pang lever na madaling i-slip early at pagkatapos ay i-rediscover pagkatapos. Ang mga gumagamit ay hindi natutunan ang mga tanong sa paraan kung paano ang mga dokumento ay itinuturing. Ang isang rewrite step ay maaaring i-expand ang acronyms, normalize ang entities, at i-split ang mga tanong sa ilang bahagi sa mga sub-queries na madaling i-recovery. Ito ay hindi kailangang maging fancy - ngunit ito ay kinakailangan ng observability, dahil ang uncontrolled rewriting ay maaaring i-drive away mula sa user intent. Security: The Layer Everyone Forgets Security: ang layer na lahat ay lupa Ang karamihan ng mga demo ng RAG ay nangangailangan ng control ng access dahil ito ay nagbabago ang prototype. Sa produksyon, ito ay isang pangunahing limitasyon. Kung ang iyong sistema ay indexed ng mga dokumento ng HR, legal contracts, at engineering specs kasama, kailangan mo ng isang deterministic na patlang ng hakbang mula sa user → allowed chunks, at ang pagkuha ay dapat na limitasyon sa pamamagitan ng patlang na ito bago ang anumang nilalaman ay dumating sa isang LLM. Ang pattern na nagtatagumpay ay pre-filtered retrieval: compute entitlements (RBAC/ABAC), retrieve lamang mula sa chunks na may compatible ACL attributes, reerank sa loob ng authorized candidate set, at log kung ano ang evidence ay na-accessed. Ito ay din kung saan ang "metadata ay hindi optional" na punto ay nagpapakita sa karanasan - walang tag-level tagging, makakuha ka ng leaky boundaries o mahalagang, brittle post-filters. Sa paglipas ng ACL, ang mga pag-implementasyon ng enterprise ay karaniwang kailangan ng ilang kombinasyon ng pag-detection / masking ng PII, pag-encrypt sa pagbabago, short-lived tokens para sa access source, at auditing logging na i-capture query, i-recovered chunk IDs, mga quote, at mga bersyon ng dokumento. Ang isa pang modernong pangangailangan na dapat maging malubhang ay ang mabilis na pag-injection ng content sa loob ng mga dokumento. Hindi mo na kailangang magtatrabaho sa bawat dokumento bilang hostile, ngunit kailangan mo ng mga pangunahing guardrails kaya ang mga pag-imbak sa source text ay hindi maaaring i-substitute ang mga patakaran ng iyong sistema - lalo na tungkol sa access, pag-uulat, at kung paano ang modelo ay Monitoring: Closing the Loop Paglalarawan ng: Closing the Loop Kung ginagamit mo ang isa sa mga sistema na ito para sa higit sa ilang linggo, makikita mo ang drift. Ang mga dokumento ay nagbabago, ang pag-distribusyon ng query ay nagbabago, ang pipeline ng ingestion ay nagbabago, at ang mga bahagi ng modelo ay i-update. Sa pangkalahatan, nais mong i-track ang health ng retrieval (recall@k laban sa isang golden set, context precision, reranker lift), health ng generation (citation precision, groundedness/faithfulness checks, rejection rates), at operational health (p50/p95 latency, cost per query, ingestion lag mula sa pag-update ng dokumento sa searchable index). Ang pinaka-effective mga team na nakita ko ay nagtatag ng isang gold evaluation dataset — curated mga tanong na may na-expect source documents — at i-run ito sa isang schedule at sa pagbabago ng mga kaganapan (new embeddings, new chunking logic, new document batches). Tooling tulad ng Phoenix, TruLens, o commercial platforms ay maaaring makatulong, ngunit ang mas mataas na difer Isang lugar na karaniwang subestimated ay versioning at reproductibility. Kapag i-change ang mga modelo ng OCR, chunking logic, embedding mga modelo, reerankers, o generating prompts, kailangan mo ng isang paraan upang i-trace kung ano ang mga bersyon produced na ang mga solusyon. That's what makes debugging and audits feasible months later. Choosing Your Stack Piliin ang iyong Stack Para sa maraming mga team, ang isang managed-leaning setup ay napaka-attraksyon: ingestion sa pamamagitan ng isang managed Document AI tool o Unstructured-based pipeline, isang hosted vector database, isang orchestration layer tulad ng LlamaIndex o LangChain, at isang reranker (open o managed). Ang iba ay nagbibigay-daan ng open-source deployments gamit ang Qdrant/Weaviate/OpenSearch, Haystack o katulad na orchestration, at self-hosted mga modelo para sa control at cost predictability. Lahat ng paraan ay maaaring gumagana kung ito ay sumusuporta sa mga pangunahing: document-conscious ingestion, hybrid retrieval, entitlement enforcement, provenance-friendly citations, evaluation pipelines, at version Sa side ng architecture, ang mga sistema ay nagkakaroon ng mas madaling pag-operate kapag ang mga ito ay pinagsasama na: ang mga trabaho ng ingestion na inilunsad asynchronously at maaaring i-retreat sa kaligtasan; isang serbisyo ng retrieval na nangangahulugan ang mga patakaran at i-returns mga dokumento; at isang serbisyo ng pag-generate na nagtatrabaho sa limitadong kontekstong at malinaw na provenance. Ang isang tipikal na pag-implementasyon ng reference ay naglalaman ng isang API gateway, isang job queue (Kafka/RabbitMQ), object storage para sa raw mga dokumento at parsed artifacts, ang index layer (+dense sparse), plus centralized logging/metrics at isang audit trail.