
5,731 usomaji
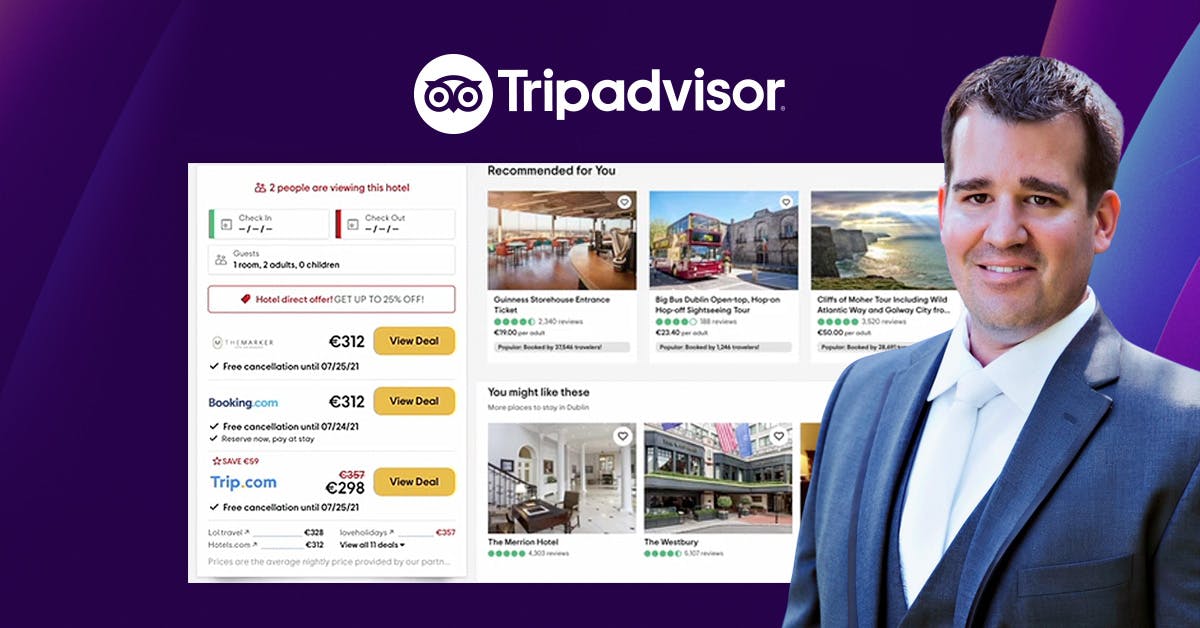
Jinsi Tripadvisor Inatoa Personalization ya wakati halisi kwa Kiwango na ML
by
2025/07/22





































































Story's Credibility


Story's Credibility
About Author

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly
MAONI

HANG TAGS



Related Stories









A PENDENT WORLD
Jan 20, 1970