
5,717 Lesungen
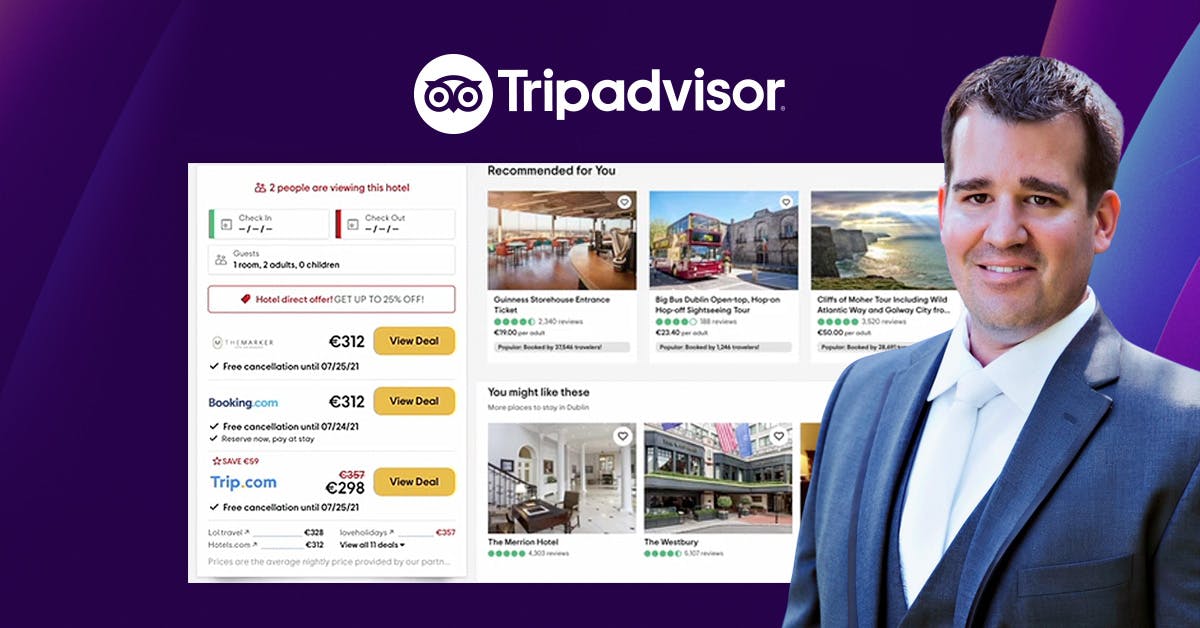
Wie Tripadvisor mit ML Echtzeit-Personalisierung im Maßstab liefert
by
2025/07/22





































































Story's Credibility


Story's Credibility
About Author

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly
KOMMENTARE

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly








