
5,731 lecturas
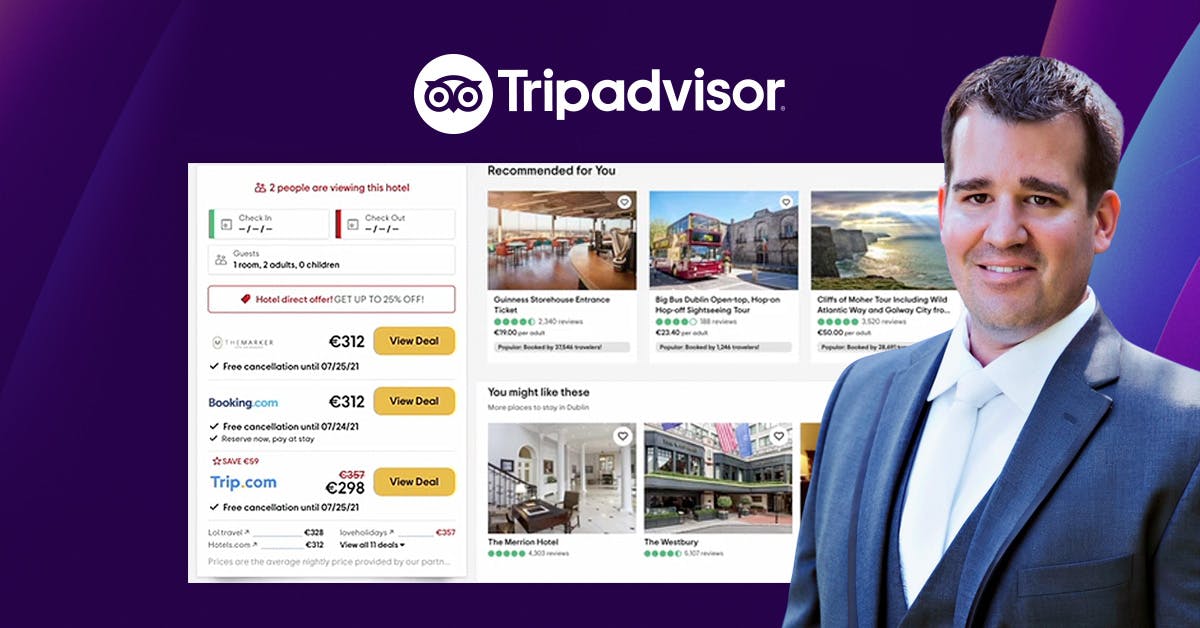
Cómo TripAdvisor ofrece personalización en tiempo real a escala con ML
by
2025/07/22





































































Story's Credibility


Story's Credibility
About Author

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly
COMENTARIOS

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly











