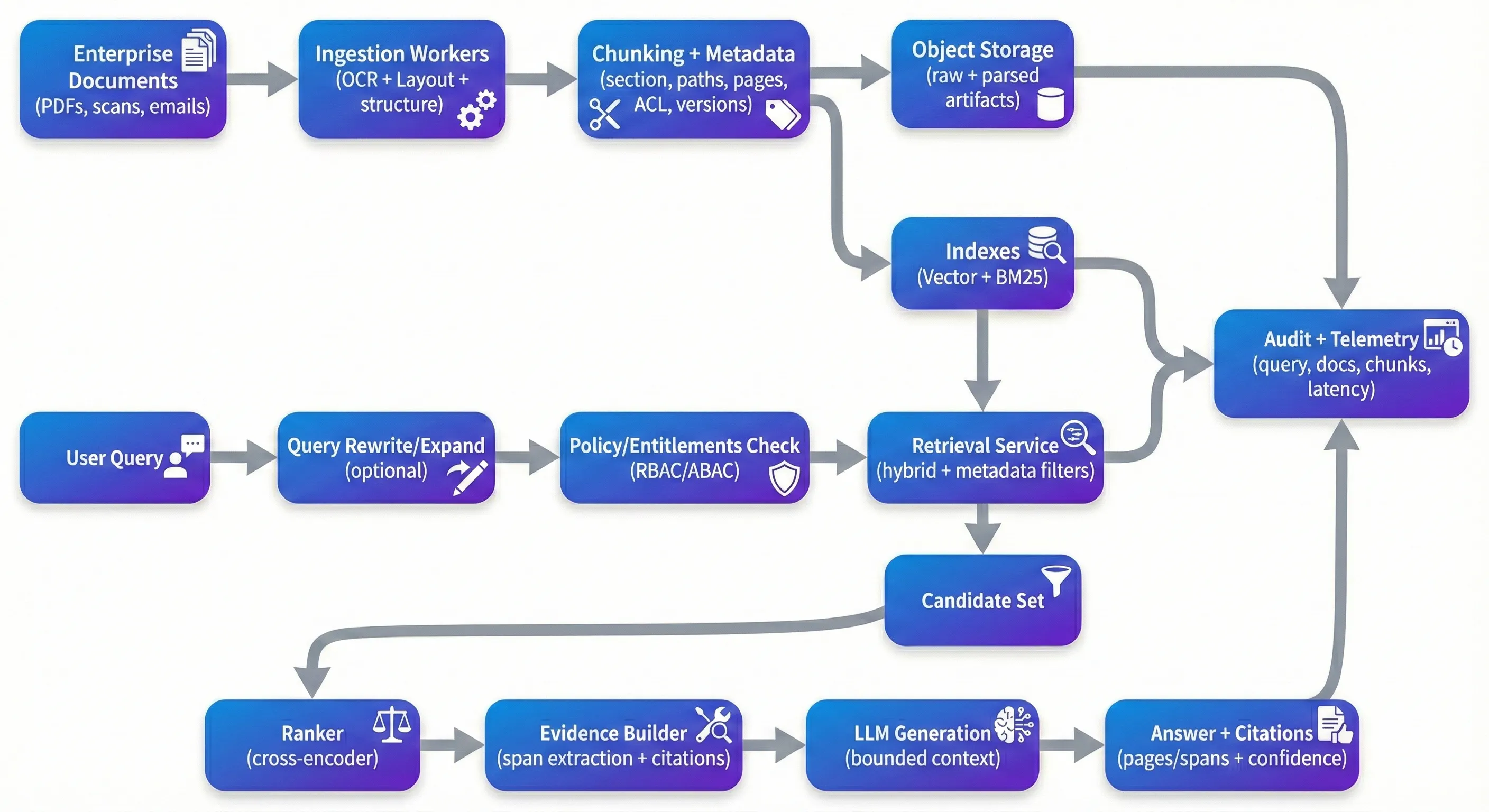
RAG adalah di mana-mana—dan itu tidak menghairankan. Ia adalah salah satu cara yang paling praktikal untuk membuat koleksi dokumen yang besar boleh dicari tanpa membina parser yang rapuh, spesifik domain untuk setiap jenis soalan. Penangkapannya ialah bahawa apa yang berfungsi dalam demo terkawal sering merosot dengan cepat apabila anda meletakkannya di hadapan PDF perniagaan sebenar: kontrak yang dipindai, pendaftaran pematuhan, rekod perubatan, dasar, dan ekor panjang masalah tata letak dan kualiti yang datang dengan mereka. Apabila pasukan terjejas, ia jarang kerana carian vektor "tidak berfungsi." Ia adalah kerana sistem tidak boleh secara konsisten mendasarkan jawapan kepada bukti yang betul, tidak boleh menguatkuasakan hak secara boleh dipercayai, atau tidak boleh dinilai dan diperbaiki tanpa memecahkan perkara. The Demo Trap Tag: perangkap demo Kebanyakan prototipe mengikuti laluan yang sama: letakkan dokumen ke dalam kedai vektor, dapatkan kepingan top-k, dan minta LLM untuk mensintesis. Pada teks yang bersih, terstruktur dengan baik, yang boleh kelihatan sangat baik. Masalahnya ialah apa yang berlaku seterusnya. PDF yang disemak datang dalam berputar atau terselip. Urutan bacaan berbilang lajur terjejas. Jadual kehilangan struktur semasa mengekstrak. Chunking membahagikan argumen tengah. Retrieval mengembalikan konteks "hampir cukup" yang membaca dengan mudah tetapi tidak benar-benar menyokong tuntutan. Dan model, melakukan apa yang dioptimalkan untuk dilakukan, menjawab dengan lancar bagaimanapun. Dalam pengeluaran, anda mengoptimumkan untuk ciri-ciri yang berbeza daripada demo.Anda mahu sistem itu boleh dipercayai atas input yang kacau, boleh diulang melalui perubahan paip, dan boleh dipertahankan di bawah pemeriksaan.Ini bermakna mampu menjejaki jawapan kembali kepada bukti tertentu, dan mempunyai lalai yang kuat apabila bukti lemah: mengklarifikasi soalan, tingkah laku penolakan, atau memaparkan "bukti terbaik yang tersedia" dengan ketidakpastian eksplisit.Ini juga bermakna menganggap kawalan capaian sebagai sebahagian daripada pemulihan - bukan sebagai pemikiran selepas yang dilipat pada UI. Ingestion: Where Quality Is Won or Lost Pengambilan: Di mana kualiti diperolehi atau hilang Jika anda telah membina beberapa sistem ini, anda akan belajar dengan cepat bahawa pengambilan menentukan kualiti pemulihan lebih banyak daripada kebanyakan trik-trik bawah. Preprocessing Dokumen AI tidak glamor, tetapi ia adalah di mana anda sama ada mengekalkan struktur - atau kehilangan secara kekal. Untuk dokumen perniagaan, OCR sahaja tidak mencukupi; anda biasanya memerlukan OCR dengan pengesanan layout, rekonstruksi urutan bacaan, dan pengekstrakan struktur yang mengekalkan tajuk, seksyen, dan jadual bermakna. Alat yang dikendalikan seperti Google Document AI, Azure Document Intelligence, dan Amazon Textract boleh menutupi banyak tanah. Chunking ialah di mana pasukan sering meremehkan kerumitan. Perbezaan watak atau token yang mudah adalah cepat, tetapi ia cenderung untuk memotong sempadan semantik – tepatnya sempadan pengguna yang peduli dalam kontrak dan dasar. Adaptive chunking yang mengikuti tajuk, sempadan seksyen, dan sempadan jadual biasanya meningkatkan kedua-dua pemulihan dan tanah turun. Ia juga membuat provenance berasa semulajadi kepada pengguna akhir: alih-alih memaparkan ID dalaman yang tidak jelas seperti chunk_4892, anda boleh menunjukkan kepada sesuatu yang boleh diperiksa oleh peninjau dengan segera – “MSA v3.2 → Seksyen 9 (Termination) → 9.2 (Termination for Cause), halaman 12, baris 14–22.” Metadata adalah kawasan lain yang cenderung kelihatan opsional sehingga anda membutuhkannya. Dalam amalan, metadata adalah apa yang membolehkan penapisan, pelacakan, dan pemulihan. Metadata yang berguna pada tahap bahagian biasanya termasuk ID dokumen, laluan seksyen, nombor halaman, timestamps ( tarikh berkesan, terakhir diubahsuai, dimasukkan pada), isyarat kepercayaan ekstraksi, dan pengenal versi (dokumen hash, versi chunking, versi model embedding). Dalam konteks perniagaan, atribut kawalan akses (penyewa, jabatan, privasi, tag peranan) perlu menjadi kelas pertama, kerana mereka secara langsung menghalang pemulihan dan audit. The Retrieval Stack That Actually Works The Retrieval Stack Yang Sebenarnya Bekerja Pencarian kesamaan vektor adalah asas yang baik, tetapi ia jarang mencukupi untuk dokumen korporat. Dalam amalan, pencarian hibrid - embeddings padat ditambah pencarian leksikal yang jarang seperti BM25 - cenderung menjadi lebih kukuh, terutamanya apabila pengguna menginterogasi dengan nombor klausa, pengidentifikasi, akronim, atau frasa yang tepat. Reranking sering merupakan tempat di mana sistem membuat lompatan terbesar dalam kualiti yang dirasakan, bukan kerana ia ajaib, tetapi kerana ia memperbaiki mod kegagalan biasa: set pemulihan awal mengandungi kepingan "kinda relevan" dan anda perlu mempromosikan yang benar-benar relevan ke atas. re-rankers cross-encoder (model terbuka seperti bge-reranker atau API yang dikendalikan seperti Cohere ranker) rescore kepingan calon menggunakan interaksi soalan-passage yang lebih mendalam. Pasukan biasanya melihat peningkatan yang ketara dalam ketepatan konteks apabila reranking diukur dengan betul (contohnya, pada set emas dengan sumber yang dijangka). Jika anda mengekalkan klaim kuantitatif di sini, ia adalah yang terbaik untuk mengikatnya kepada metrik ("ketepatan konteks" atau "ketepatan penilaian") dan set Penulisan semula dan memperluaskan pertanyaan adalah lever lain yang mudah untuk melompati awal dan kemudian menemui semula kemudian. Pengguna tidak secara semulajadi mengucapkan soalan-soalan seperti cara dokumen ditulis. Langkah penulisan semula boleh mengembangkan akronim, menormalkan entiti, dan membahagikan soalan-soalan pelbagai bahagian kepada sub-soalan yang mudah didapati. Ia tidak perlu cemerlang-tetapi ia memerlukan pemantauan, kerana penulisan semula yang tidak terkawal boleh mengalih keluar daripada niat pengguna. Security: The Layer Everyone Forgets Keselamatan: lapisan yang semua orang lupa Kebanyakan demo RAG mengabaikan kawalan capaian kerana ia memperlahankan prototipe. Dalam pengeluaran, ia adalah sekatan utama.Jika sistem anda mengindeks dokumen HR, kontrak undang-undang, dan spesifikasi kejuruteraan bersama-sama, anda memerlukan laluan hak deterministik daripada pengguna → membenarkan kepingan, dan pemulihan mesti dibatasi oleh laluan itu sebelum mana-mana kandungan mencapai LLM. Pattern yang cenderung untuk meluas adalah pencarian terdahulu yang difilter: hak pengiraan (RBAC / ABAC), mengambil hanya daripada potongan dengan atribut ACL yang serasi, rerank dalam set calon yang dibenarkan, dan log apa bukti yang diakses. Di luar ACL, penyebaran perniagaan biasanya memerlukan beberapa gabungan pengesanan / masking PII, enkripsi pada waktu istirahat, token jangka pendek untuk akses sumber, dan log audit yang menangkap pertanyaan, ID potongan dicari, kutipan, dan versi dokumen. Satu lagi keprihatinan moden yang patut diambil serius adalah kandungan suntikan segera di dalam dokumen.Anda tidak perlu memperlakukan setiap dokumen sebagai bermusuhan, tetapi anda memerlukan garda asas supaya arahan yang dimasukkan ke dalam teks sumber tidak boleh menggantikan peraturan sistem anda - terutamanya di sekitar akses, kawalan, dan bagaimana model dibenarkan bertindak. Monitoring: Closing the Loop Pengawasan: Menutup laluan Jika anda mengendalikan salah satu daripada sistem ini selama lebih daripada beberapa minggu, anda akan melihat drift. dokumen berubah, pengedaran pertanyaan berubah, paip pengambilan berubah, dan komponen model diperbaharui. Tanpa pemantauan dan penilaian, kualiti secara diam-diam menurun sehingga pengguna berhenti mempercayai alat. Secara praktikal, anda ingin menjejaki kesihatan pemulihan (recall@k terhadap set emas, ketepatan konteks, menaikkan peringkat), kesihatan pengeluaran (ketepatan kutipan, pemeriksaan landasan / kesetiaan, kadar penolakan), dan kesihatan operasi (p50 / p95 latency, kos per pertanyaan, penambahan penundaan dari kemas kini dokumen ke indeks yang boleh dicari). Pasukan yang paling berkesan yang saya lihat mengekalkan set data penilaian emas - soalan yang diselesaikan dengan dokumen sumber yang diharapkan - dan menjalankan mengikut jadual dan pada peristiwa perubahan (embeddings baru, logik chunking baru, batch dokumen baru). Alat-alat seperti Phoenix, TruLens, atau platform komersial boleh membantu, tetapi perbezaan yang lebih besar ialah disiplin untuk mengekalkan penilaian semasa dan merawat regresi seperti insiden pengelu Satu kawasan yang sering diabaikan ialah pengedaran versi dan kebolehpercayaan semula. Apabila anda menukar model OCR, logik chunking, embedding model, rerankers, atau jemputan pengeluaran, anda memerlukan cara untuk menjejaki mana-mana versi yang dihasilkan yang menjawab. Choosing Your Stack Pilih Stack anda Keputusan tumpukan penting, tetapi keupayaan lebih penting. Bagi banyak pasukan, setup yang dikendalikan adalah menarik: pengambilan melalui alat AI Dokumen yang dikendalikan atau paip berasaskan Unstructured, pangkalan data vektor yang dihoskan, lapisan orkestrasi seperti LlamaIndex atau LangChain, dan reranker (buka atau dikuruskan). Yang lain lebih suka pengenalan sumber terbuka menggunakan Qdrant/Weaviate/OpenSearch, Haystack atau orkestrasi yang serupa, dan model yang dihoskan sendiri untuk kawalan dan prediktabiliti kos. Kedua-dua pendekatan boleh berfungsi jika ia menyokong asas-asas: pengambilan dokumen yang sedar, pemulihan hibrid, penguatkuasaan hak, kutipan yang mesra asal, paip penilaian, dan pengeditan. Di sisi seni bina, sistem cenderung menjadi lebih mudah untuk beroperasi apabila mereka dibahagikan dengan bersih: pekerja pengambilan yang berjalan secara asynchronous dan boleh dipulihkan dengan selamat; perkhidmatan pengambilan tanpa status yang menguatkuasakan dasar-dasar dan mengembalikan bukti; dan perkhidmatan pengeluaran yang beroperasi dengan konteks terhad dan asal yang jelas. penyebaran rujukan tipikal termasuk gateway API, barisan kerja (Kafka/RabbitMQ), penyimpanan objek untuk dokumen mentah dan artefak yang dipaparkan, lapisan indeks ( +dense sparse), ditambah logging/metrik bersentralisasi dan laluan audit.