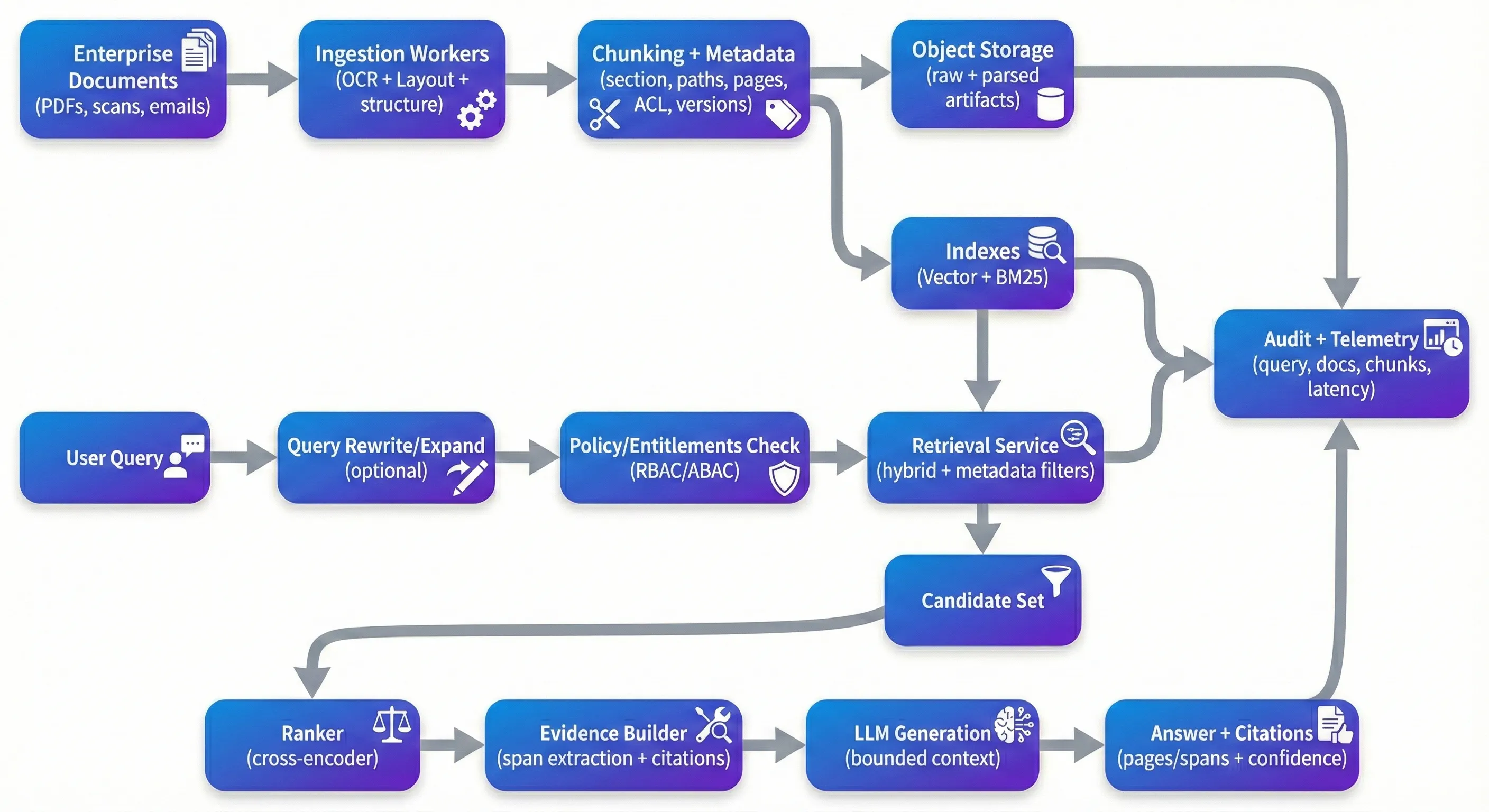
RAG е насекаде – и тоа не е изненадувачки. Тоа е еден од најпрактичните начини да се направат големи збирки документи достапни за пребарување без да се градат кршливи, домен-специфични аналитичари за секој тип на прашање. Улогата е во тоа што она што работи во контролирана демо често се деградира брзо кога го ставате пред вистински корпоративни PDF-ови: скенирани договори, поднесоци за усогласеност, медицински записи, политики и долгиот ред на проблеми со распоредот и квалитетот што доаѓаат со нив. Во производството, "проблемот RAG" е помалку за паметно повикување, а повеќе за повторувањето: следење, безбедност, контрола на квалитетот и способноста да се објасни зошто одговорот е точен ( Кога тимовите се заглавени, тоа е ретко затоа што пребарувањето на векторите „не функционира“. Тоа е затоа што системот не може постојано да ги основа одговорите на вистинските докази, не може да ги спроведе правата сигурно, или не може да се процени и подобри без да се скрши работите. The Demo Trap Демо стапица Повеќето прототипи го следат истиот пат: фрлете документи во векторска продавница, преземете топ-к парчиња и побарајте од LLM да ги синтезира. На чист, добро структуриран текст, тоа може да изгледа одлично. Проблемот е што се случува следно. Скенираните PDF-ови доаѓаат во ротирано или искривено. Редоследноста на читање на повеќе колони се зафаќа. Табелите ја губат структурата за време на екстракцијата. Чункирањето се дели на средината на аргументот. Повлекувањето враќа „доволно блиску“ контекст кој чита веродостојно, но всушност не го поддржува тврдењето. Во производството, оптимизирате за различни својства од демонстрација.Сакате системот да биде сигурен над несоодветните влезови, репродуктивен низ промените на цевката и одбранителен под контрола.Тоа значи да бидете во можност да го следите одговорот назад кон специфични докази и да имате силни предрасуди кога доказите се слаби: разјаснување на прашањата, одбивање од однесување или презентирање на "најдобри достапни докази" со експлицитна неизвесност.Тоа исто така значи да се третира контролата на пристапот како дел од пребарувањето - а не како последна мисла сложена на УИ. Ingestion: Where Quality Is Won or Lost Ингестија: каде што квалитетот е освоен или изгубен Ако сте изградиле неколку од овие системи, брзо ќе дознаете дека ингестијата го одредува квалитетот на пребарувањето повеќе од повеќето трикови надолу. Пред-обработката на документот АИ не е гламурозна, но тоа е местото каде што или ја зачувувате структурата – или трајно ја губите. За корпоративни документи, ОЦР сам по себе не е доволно; обично ви е потребен ОЦР со откривање на распоредот, реконструкција со ред на читање и екстракција на структурата која ги одржува насловите, секциите и табелите значајни. Управуваните алатки како Google Document AI, Azure Document Intelligence и Amazon Textract можат да покријат многу терен. Чункирањето е местото каде тимовите често ја потценуваат комплексноста. Едноставен карактер или поделба на токени е брз, но има тенденција да ги пресече семантичките граници – токму границите за кои корисниците се грижат во договорите и политиките. Адаптивното цункирање кое ги следи насловите, границите на секциите и границите на табелите обично го подобрува и пребарувањето и надолу потокот на заземјување. Тоа исто така го прави потеклото да се чувствува природно за крајниот корисник: наместо да се појави непрозрачен внатрешен ИД како што е chunk_4892, можете веднаш да укажете на нешто што рецензентот може да го провери – „MSA v3.2 → Секција 9 (Крај) → Метаподатоците се уште една област која има тенденција да изгледа опционална додека не ви е потребна. Во пракса, метаподатоците се она што го прави филтрирањето, трагањето и репродуктивноста можно. Корисни метаподатоци на големо ниво обично вклучуваат идентификатори на документи, патеки на секции, броеви на страници, временски ознаки (ефективен датум, последен модифициран, ингестиран на), сигнали за доверба на екстракција и идентификатори на верзии (документ хаш, верзија на шункирање, верзија на вграден модел). Во корпоративните контексти, атрибутите за контрола на пристапот (наемник, оддел, доверливост, ознаки за улоги) треба да бидат од прва класа, бидејќи The Retrieval Stack That Actually Works Стак за враќање што всушност функционира Пребарувањето на сличноста на векторите е добар почеток, но ретко е доволно само за корпоративни документи. Во пракса, хибридното пребарување - тесни вградувања плус ретки лексички пребарувања како BM25 - има тенденција да биде посилно, особено кога корисниците пребаруваат со броеви на клаузули, идентификатори, акроними или точни фрази. Повторното рангирање е честото место каде системите го прават најголемиот скок во перципираниот квалитет, не затоа што е магично, туку затоа што го поправува заедничкиот режим на неуспех: почетниот сет за пребарување содржи "кинда релевантни" парчиња, и треба да ги промовирате навистина релевантните парчиња на врвот. Повторното рангирање на крос-кодирање (отворени модели како bge-reranker или управувани АПИ како Cohere ranker) повторно ги оценува парчињата на кандидатите користејќи подлабока интеракција прашање-премин. Тимовите обично гледаат забележлив пораст во контекстната прецизност кога реранкирањето се мери правилно (на пример, на златен се Повторното пишување и проширувањето на прашањата е уште еден лост кој е лесно да се прескокне порано, а потоа повторно да се открие подоцна. Корисниците природно не ги изразуваат прашањата на начинот на кој се пишуваат документите. Чекор на препишување може да ги прошири акронимите, да ги нормализира субјектите и да ги подели прашањата од повеќе делови во под-запрашувања кои се пријателски за пребарување. Тоа не треба да биде фантастично, но потребна е опсервабилност, бидејќи неконтролираното препишување може да се оддалечи од корисничката намера. Security: The Layer Everyone Forgets Безбедност: слојот што сите го забораваат Повеќето RAG демонстрации го игнорираат контролата на пристапот, бидејќи го забавува прототипот. Во производството, тоа е примарно ограничување. Ако вашиот систем индексира HR документи, правни договори и инженерски спецификации заедно, потребен ви е детерминистички пат за право од корисникот → дозволени парчиња, а пребарувањето мора да биде ограничено од тој пат пред било која содржина да стигне до LLM. Моделот кој има тенденција да се скалира е префилтрирано пребарување: пресметување на правата (RBAC/ABAC), пребарување само од парчиња со компатибилни АЦЛ атрибути, реранкирање во рамките на овластениот сет на кандидати и лог на кои докази се пристапува. Покрај ACL, имплементациите на претпријатијата обично имаат потреба од некоја комбинација на откривање / маскирање на PII, шифрирање на одмор, краткотрајни токени за пристап до изворот и регистрација на ревизија која ги фаќа прашањата, преземени ID-и, цитати и верзии на документи. Една повеќе модерна загриженост вреди да се земе сериозно е брзото вбризгување на содржината во документите. Не треба да се третира секој документ како непријателски, но ви се потребни основни стражари, така што инструкциите вградени во изворниот текст не можат да ги надминат правилата на вашиот систем - особено околу пристапот, контролата и како моделот е дозволено да се однесува. Monitoring: Closing the Loop Мониторинг: Затворање на кругот Ако користите еден од овие системи повеќе од неколку недели, ќе видите дрифт. Документите се менуваат, дистрибуцијата на прашањата се менува, цевката за внесување се менува и компонентите на моделот се ажурираат. Практично, сакате да го следите здравјето на пребарувањето (recall@k против златен сет, контекстна прецизност, реранкер лифтинг), здравјето на генерацијата (прецизност на цитирање, провери за заземјување / лојалност, стапки на одбивање) и оперативното здравје (p50/p95 латентност, трошок по барање, заостанување на внесување од ажурирањето на документот до индексот што може да се пребарува). Најефикасните тимови што сум ги видел одржуваат златен сет на податоци за евалуација - исчистени прашања со очекуваните изворни документи - и ги извршуваат по распоред и на настани за промена (нови вградувања, нова логика за цункирање, нови парчиња Една област која често се потценува е верзионирање и репродуктивност. Кога ги менувате моделите на OCR, логиката, вградувањето на моделите, реранкерите или инспирациите за генерација, потребен ви е начин да ги следите кои верзии произведоа кои одговори. Choosing Your Stack Избор на вашиот стак Стап одлуки се важни, но можностите се важни повеќе. За многу тимови, управувана инсталација е атрактивна: ингестија преку управувана алатка за документарна вештачка интелигенција или неструктурирана базирана цевка, хостирана векторска база на податоци, оркестрациски слој како LlamaIndex или LangChain, и реранкер (отворен или управуван). Други претпочитаат депонирање со отворен код со користење на Qdrant/Weaviate/OpenSearch, Haystack или слична оркестрација, и само-хостирани модели за контрола и трошоци предвидување. И двајцата пристапи можат да работат ако ги поддржуваат темелите: ингестија со свест за документи, хибридно враќање, спроведување на На архитектонската страна, системите имаат тенденција да станат полесни за работа кога се поделени чисто: работници за преземање кои работат асинхроно и можат безбедно да се редистрибуираат; услуга за преземање без статус која ги спроведува политиките и враќа докази; и услуга за генерирање која работи со ограничен контекст и јасно потекло.