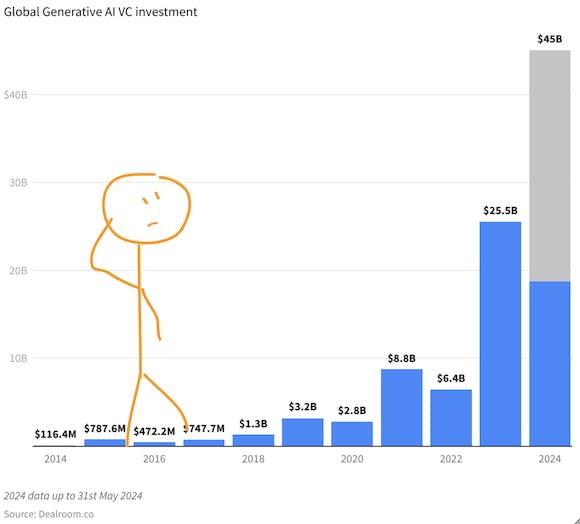
#ARTIFICIAL-INTELLIGENCEການຄຸ້ມຄອງຫຼັກຊັບ: ທຸກວິທີທາງ AI ແມ່ນການຫັນປ່ຽນຍຸດທະສາດຊັບສິນທີ່ທັນສະໄຫມAndrey KustarevApr 25, 2024
#ARTIFICIAL-INTELLIGENCEເລີ່ມຕົ້ນງ່າຍດາຍ: ຄວາມໄດ້ປຽບຍຸດທະສາດຂອງຕົວແບບພື້ນຖານໃນການຮຽນຮູ້ເຄື່ອງຈັກAndrey KustarevMay 01, 2024
#ARTIFICIAL-INTELLIGENCEການຄຸ້ມຄອງຫຼັກຊັບ: ທຸກວິທີທາງ AI ແມ່ນການຫັນປ່ຽນຍຸດທະສາດຊັບສິນທີ່ທັນສະໄຫມAndrey KustarevApr 25, 2024
#ARTIFICIAL-INTELLIGENCEເລີ່ມຕົ້ນງ່າຍດາຍ: ຄວາມໄດ້ປຽບຍຸດທະສາດຂອງຕົວແບບພື້ນຖານໃນການຮຽນຮູ້ເຄື່ອງຈັກAndrey KustarevMay 01, 2024