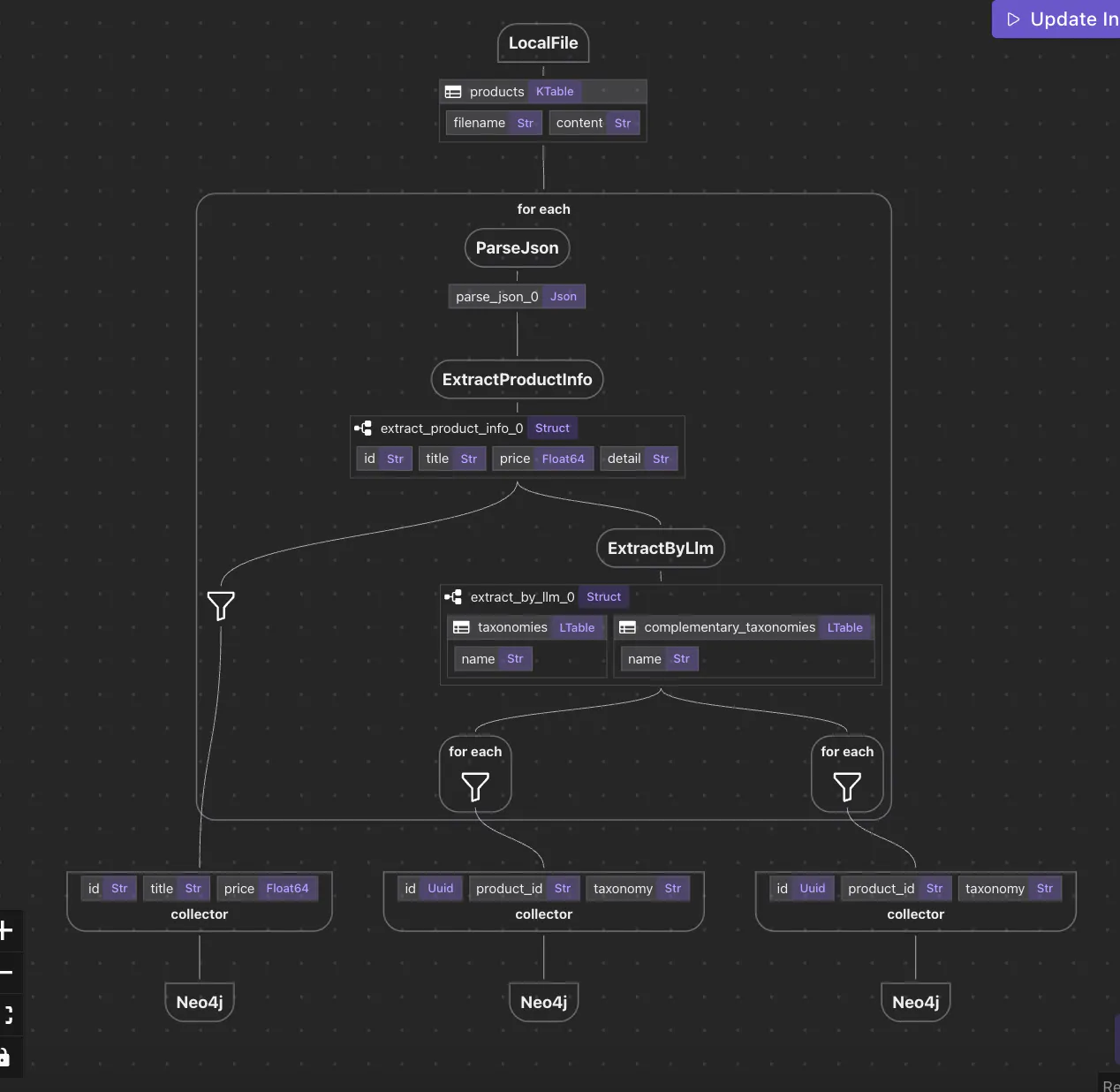
#DATA-ENGINEERINGRedizajniranje operacija podataka s programiranjem protoka podataka u CocoIndexuLJJul 17, 2025
#ARTIFICIAL-INTELLIGENCEUpravljanje portfeljem: sve načine na koje umjetna inteligencija transformira moderne strategije imovineAndrey KustarevApr 25, 2024
#ARTIFICIAL-INTELLIGENCEPočeti jednostavno: strateška prednost osnovnih modela u strojnom učenjuAndrey KustarevMay 01, 2024
#DATA-ENGINEERINGRedizajniranje operacija podataka s programiranjem protoka podataka u CocoIndexuLJJul 17, 2025
#ARTIFICIAL-INTELLIGENCEUpravljanje portfeljem: sve načine na koje umjetna inteligencija transformira moderne strategije imovineAndrey KustarevApr 25, 2024
#ARTIFICIAL-INTELLIGENCEPočeti jednostavno: strateška prednost osnovnih modela u strojnom učenjuAndrey KustarevMay 01, 2024