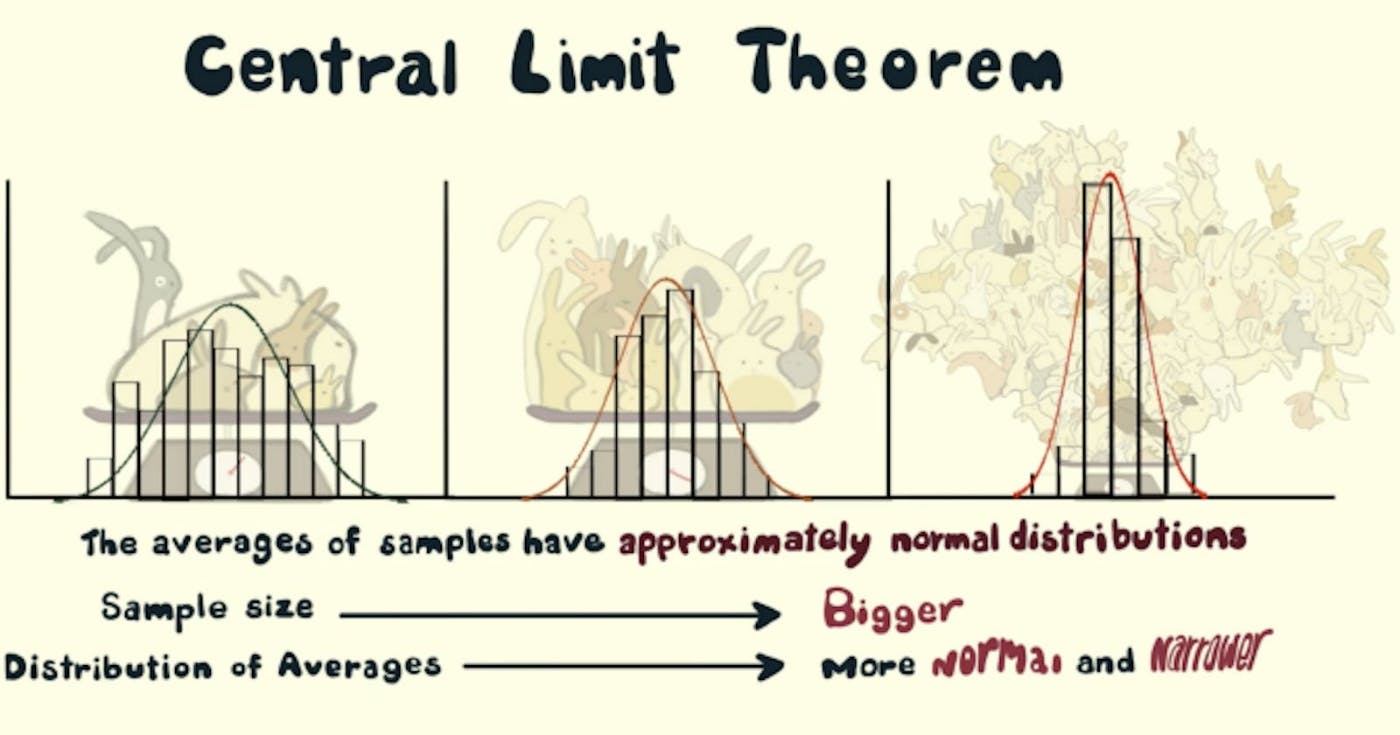
定義、意義、応用 TLDR: コード全体は 見つけることができます。 GitHub で 中心極限定理は次の現象を捉えています。 あらゆるディストリビューションを受け取りましょう! (サッカーの試合におけるパス数の分布を例に挙げます) その分布 (n = 5 など) から n 個のサンプルを複数回 (m = 1000 など) 取得し始めます。 各サンプルセットの平均値を取得します (つまり、m = 1000 の平均値になります)。 平均値の分布は (多かれ少なかれ) なります。 (平均を X 軸に、その頻度を Y 軸にプロットすると、あの有名な釣鐘曲線が得られます。) 正規分布に 標準偏差を小さくするには n を大きくし、正規分布によりよく近似するには m を大きくします。 しかし、なぜ気にする必要があるのでしょうか? データ全体をロードして処理することができないのでしょうか?問題ありません。データから複数のサンプルを取り出し、中心極限定理を使用して、平均、標準偏差、合計などのデータ パラメーターを推定します。 時間とお金の面でリソースを節約できます。なぜなら、今では母集団よりも大幅に少ないサンプルを対象にして、母集団全体についての推論を引き出すことができるからです。 特定のサンプルは特定の母集団 (またはデータセット) に属しますか?標本平均、母集団平均、標本標準偏差、母集団標準偏差を使ってそれを確認してみましょう。 意味 未知の分布を持つデータセット (一様分布、二項分布、または完全にランダムな分布の可能性があります) を指定すると、標本平均は正規分布に近似します。 説明 任意のデータセットまたは母集団を取得し、その母集団からサンプルを取得し始めるとします。たとえば、10 個のサンプルを取得し、それらのサンプルの平均を取るとします。これを数回、たとえば 1000 回繰り返します。これを行った後、 1000 個の平均値が得られ、それをプロットすると、標本平均値の標本分布と呼ばれる分布が得られます。 この標本分布は(多かれ少なかれ)正規分布に従っています。これが中心極限定理です。正規分布には、分析に役立つ多くの特性があります。 図1 標本平均値の標本分布(正規分布に従う) 正規分布の性質: 平均値、最頻値、中央値はすべて等しいです。 データの 68% が平均の 1 標準偏差以内に収まります。 データの 95% は平均値の 2 標準偏差以内に収まります。 曲線は中心 (つまり、平均μの周囲) で対称です。 さらに、標本平均値の標本分布の平均値は母集団の平均値に等しくなります。 μ が母集団の平均であり、μX̅ がサンプルの平均である場合、平均は次のようになります。 図 2 母集団の平均値 = サンプルの平均値 そして、母集団の標準偏差 (σ) は、標準偏差の標本分布 (σX̅) と次の関係にあります。 σ が母集団の標準偏差、σX̅ が標本平均の標準偏差、n が標本サイズである場合、次のようになります。 図3 母集団標準偏差と標本分布標準偏差の関係 直感 母集団から複数のサンプルを取得しているため、平均値は実際の母集団の平均値と等しい (または近い) ことが多くなります。したがって、標本平均値の標本分布には実際の母集団平均値に等しいピーク(最頻値)が期待できます。 複数の無作為サンプルとその平均値は、実際の母集団の平均値に近いものになります。したがって、平均値の 50% は母平均より大きく、50% はそれ (中央値) より小さいと想定できます。 サンプルサイズを増やすと (10、20、30 と)、より多くのサンプル平均が母集団平均に近づきます。したがって、それらの平均値の平均値は、母集団の平均値に多かれ少なかれ似ているはずです。 サンプルサイズが母集団サイズと等しいという極端なケースを考えてみましょう。したがって、各サンプルの平均は母集団の平均と同じになります。これは最も狭い分布です (標本平均の標準偏差、ここでは 0)。 したがって、標本サイズが大きくなるにつれて(10、20、30と)標準偏差は減少する傾向があります(標本分布の広がりが制限され、より多くの標本平均値が母集団平均値に集中するため)。 この現象は「図3」の式で捉えられます。ここでは、標本分布の標準偏差は標本サイズの平方根に反比例します。 より多くのサンプル (1,000、5,000、10,000) を取得すると、より多くのサンプルが中心極限定理に従って動作し、パターンがよりきれいになるため、サンプル分布はより滑らかな曲線になります。 「話は安い、コードを見せて!」 - ライナス・トーバルズ それでは、コードを使用して中心極限定理をシミュレートしてみましょう。 一部の輸入品: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math を使用して母集団を作成します。さまざまなディストリビューションを試してデータを生成できます。次のコードは、(一種の) 単調減少分布を生成します。 random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population サンプルを作成し、その平均 数を取得します。 sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list いくつかのラベルとともにデータの分布をプロットする関数。 def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() コードを実行するメイン関数: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) コード全体は 見つけることができます。 GitHub で 参考文献: 中心極限定理の実際の動作 中心極限定理: 実際の応用 中心極限定理の概要 機械学習の中心極限定理への優しい入門 中心極限定理 カバー画像クレジット: Casey Dunn & Creature Cast on Vimeo 推奨読書 (推奨ビデオ): khanacademy/中心極限定理 機械学習 データサイエンス 統計 でも公開されています ここ