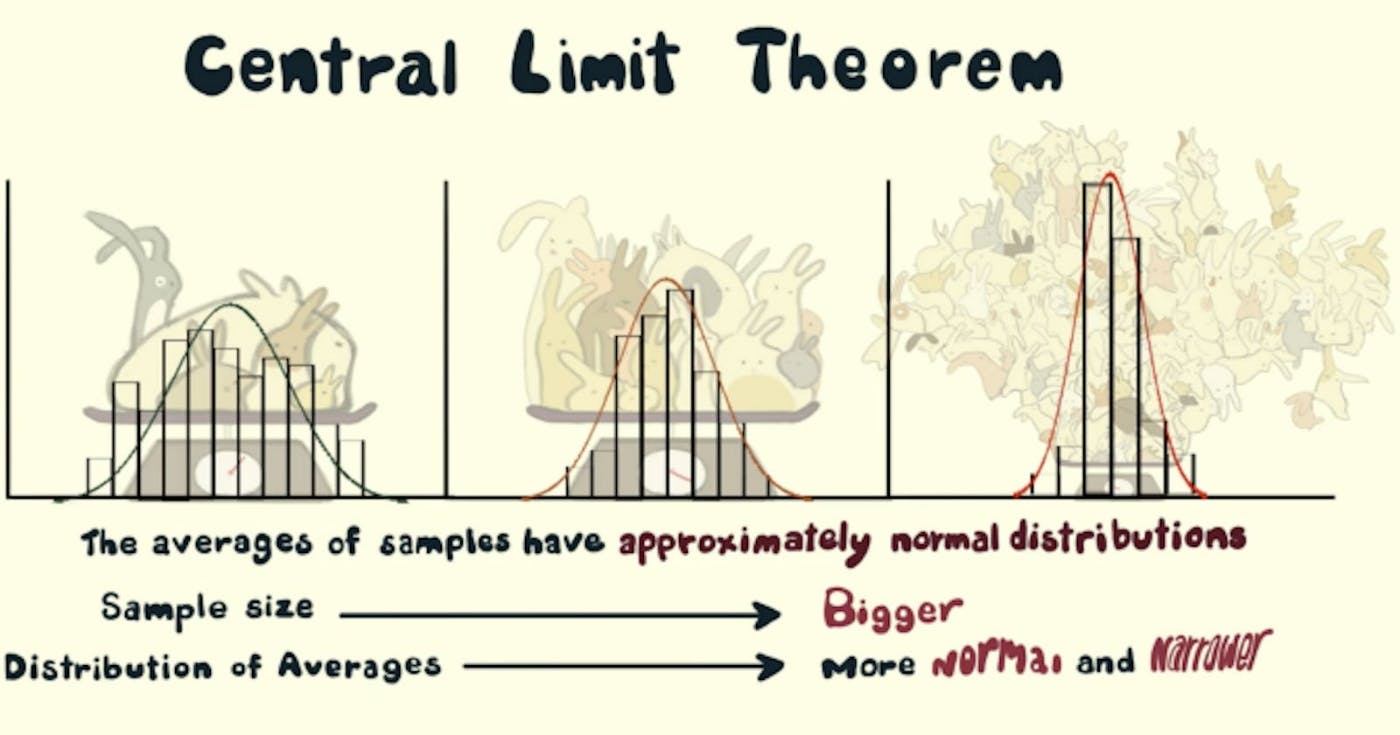
定义、意义和应用 总而言之: 您可以 找到完整代码。 在 GitHub 上 中心极限定理描述了以下现象: 采取任何分配! (比如足球比赛中传球次数的分布) 开始从该分布中多次抽取 n 个样本(假设 n = 5)[假设 m = 1000] 次。 取每个样本集的平均值(因此我们将得到 m = 1000 的平均值) 均值的分布(或多或少)呈 。 (如果将均值绘制在 x 轴上并将频率绘制在 y 轴上,您将得到那条著名的钟形曲线。) 正态分布 增加 n 可获得更小的标准差,增加 m 可获得更好的正态分布近似值。 但我为什么要关心? 您无法加载整个数据进行处理吗?没问题,从数据中取出多个样本,并使用中心极限定理来估计数据参数,如均值、标准差、总和等。 它可以节省您的时间和金钱资源。因为现在,我们可以处理明显小于总体的样本,并对整个总体进行推断! 某个样本是否属于某个总体(或数据集)?让我们使用样本均值、总体均值、样本标准差和总体标准差来检查这一点。 定义 给定一个未知分布的数据集(可以是均匀分布、二项式分布或完全随机分布),样本均值将近似正态分布。 解释 如果我们采用任何数据集或总体,然后开始从总体中采集样本,假设我们采集 10 个样本并取这些样本的平均值,然后我们继续这样做,几次,比如说 1000 次,在这样做之后,我们得到 1000 个均值,当我们绘制它时,我们得到一个称为样本均值抽样分布的分布。 这种抽样分布(或多或少)遵循正态分布!这就是中心极限定理。正态分布具有许多对分析有用的属性。 图1 样本均值的抽样分布(服从正态分布) 正态分布的性质: 平均值、众数和中位数都相等。 68% 的数据落在平均值的一个标准差范围内。 95% 的数据落在平均值的两个标准差之内。 该曲线在中心对称(即围绕平均值 μ)。 此外,样本均值的抽样分布均值等于总体均值。如果 μ 是总体平均值,μX̅ 是样本平均值,则意味着: 图2 总体平均值=样本平均值 总体标准差(σ)与标准差抽样分布(σX̅)有如下关系: 如果 σ 是总体的标准差,σX̅ 是样本均值的标准差,n 是样本量,那么我们有 图3 总体标准差与抽样分布标准差的关系 直觉 由于我们从总体中抽取多个样本,因此平均值通常会等于(或接近)实际总体平均值。因此,我们可以预期样本均值的抽样分布中的峰值(众数)等于实际总体均值。 多个随机样本及其平均值将位于实际总体平均值附近。因此,我们可以假设 50% 的均值大于总体均值,50% 的均值小于总体均值(中位数)。 如果我们增加样本量(从 10 个到 20 个到 30 个),越来越多的样本均值将更加接近总体均值。因此,这些平均值的平均值应该或多或少类似于总体平均值。 考虑样本大小等于总体大小的极端情况。因此,对于每个样本,平均值将与总体平均值相同。这是最窄的分布(样本均值的标准差,此处为 0)。 因此,当我们增加样本量(从 10 到 20 到 30)时,标准差往往会减小(因为抽样分布的分布会受到限制,更多的样本均值将集中于总体均值)。 这种现象在“图 3”中的公式中得到体现,其中样本分布的标准差与样本大小的平方根成反比。 如果我们采集越来越多的样本(从 1,000 个到 5,000 个到 10,000 个),那么采样分布将是一条更平滑的曲线,因为更多的样本将根据中心极限定理表现,并且模式会更干净。 “空谈是廉价的,给我看代码吧!” ——莱纳斯·托瓦尔兹 那么,让我们通过代码来模拟中心极限定理: 一些进口: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math 使用 创建总体。您可以尝试不同的分布来生成数据。以下代码生成(某种)单调递减分布: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population 创建样本,并获取其平均 次数: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list 绘制数据分布以及一些标签的函数。 def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() 运行代码的主要函数: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) 您可以 找到完整代码。 在 GitHub 上 参考: 中心极限定理的应用 中心极限定理:现实生活中的应用 中心极限定理简介 机器学习中心极限定理的简要介绍 中心极限定理 封面图片来源:Casey Dunn 和 Creature Cast on Vimeo 建议阅读(建议视频): 卡纳学院/中心极限定理 机器学习 数据科学 统计 也发布 在这里