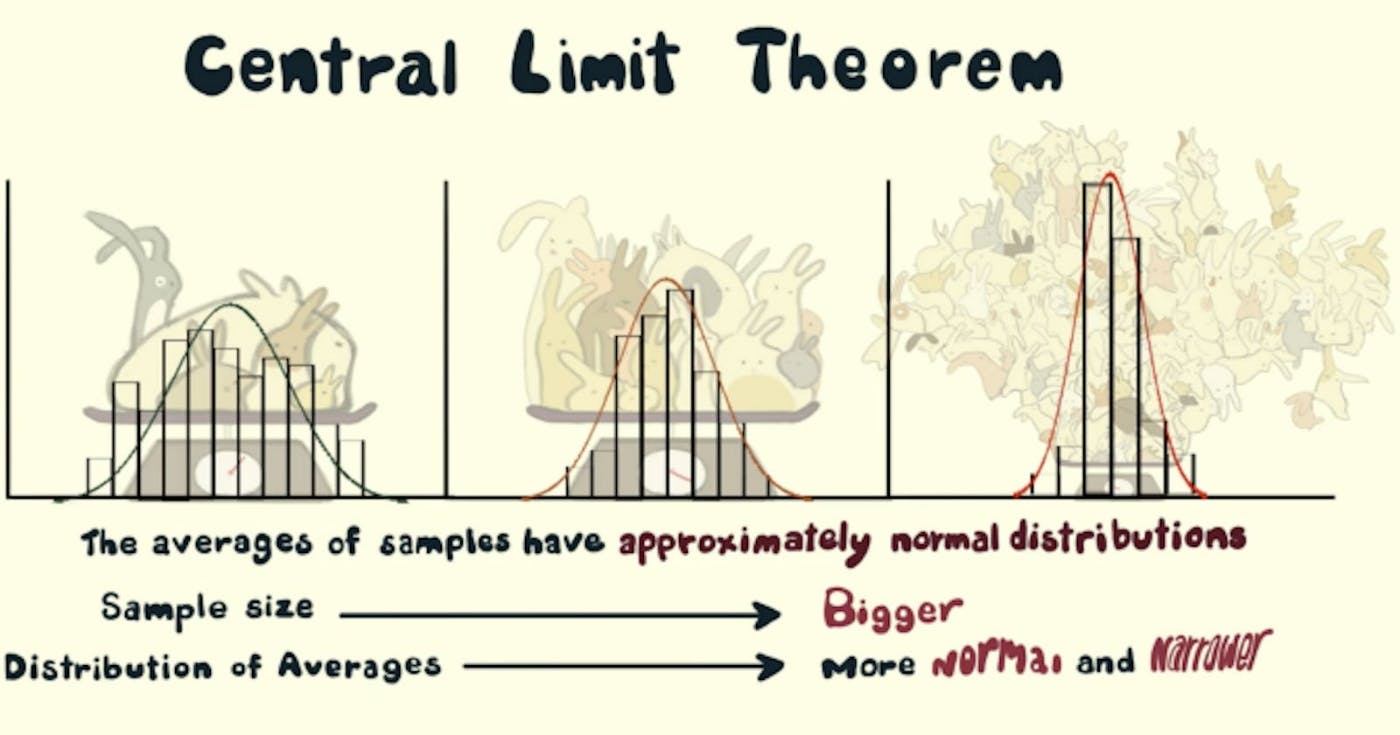
Определение, значение и приложения TLDR: Весь код вы можете найти . здесь, на GitHub Центральная предельная теорема отражает следующее явление: Берите любой дистрибутив! (скажем, распределение количества передач в футбольном матче) Начните брать n выборок из этого распределения (скажем, n = 5) несколько раз [скажем, m = 1000] раз. Возьмите среднее значение каждого набора выборок (чтобы у нас было m = 1000 средних). Распределение средств будет (более или менее) . (Вы получите знаменитую колоколообразную кривую, если отложите средние значения по оси X, а их частоту — по оси Y.) нормально распределенным Увеличьте n, чтобы получить меньшее стандартное отклонение, и увеличьте m, чтобы получить лучшее приближение к нормальному распределению. Но почему меня это должно волновать? Вы не можете загрузить все данные для обработки? Нет проблем, возьмите несколько выборок из данных и используйте центральную предельную теорему для оценки таких параметров данных, как среднее значение, стандартное отклонение, сумма и т. д. Это может сэкономить вам ресурсы с точки зрения времени и денег. Потому что теперь мы можем работать с выборками, значительно меньшими, чем генеральная совокупность, и делать выводы для всей совокупности! Принадлежит ли определенная выборка определенной совокупности (или набору данных)? Давайте проверим это, используя выборочное среднее, среднее значение генеральной совокупности, стандартное отклонение выборки и стандартное отклонение генеральной совокупности. Определение Учитывая набор данных с неизвестным распределением (оно может быть равномерным, биномиальным или полностью случайным), средние значения выборки будут аппроксимировать нормальное распределение. Объяснение Если мы возьмем какой-либо набор данных или совокупность и начнем брать выборки из совокупности, скажем, мы возьмем 10 выборок и возьмем среднее значение этих выборок, и продолжим делать это несколько раз, скажем, 1000 раз, после этого: мы получаем 1000 средних значений, и когда мы их рисуем, мы получаем распределение, называемое выборочным распределением выборочных средних. Это выборочное распределение (более или менее) соответствует нормальному распределению! Это Центральная предельная теорема. Нормальное распределение имеет ряд свойств, полезных для анализа. Рис.1 Выборочное распределение выборочных средних (после нормального распределения) Свойства нормального распределения: Среднее значение, мода и медиана равны. 68% данных находятся в пределах одного стандартного отклонения от среднего значения. 95% данных находятся в пределах двух стандартных отклонений от среднего значения. Кривая симметрична в центре (т. е. вокруг среднего значения μ). Более того, среднее значение выборочного распределения выборочных средних равно среднему генеральному. Если μ — среднее значение генеральной совокупности, а μX — среднее значение выборки, то это означает: Рис.2. Среднее значение популяции = среднее значение выборки А стандартное отклонение генеральной совокупности (σ) имеет следующее отношение к выборочному распределению стандартного отклонения (σX̅): Если σ — стандартное отклонение генеральной совокупности, σX̅ — стандартное отклонение средних выборочных значений, а n — размер выборки, то мы имеем Рис.3 Связь между стандартным отклонением генеральной совокупности и стандартным отклонением распределения выборки Интуиция Поскольку мы берем несколько выборок из генеральной совокупности, средние значения чаще всего будут равны (или близки) к фактическому среднему значению генеральной совокупности. Следовательно, мы можем ожидать пика (моды) в выборочном распределении выборочных средних, равных фактическому среднему значению генеральной совокупности. Множественные случайные выборки и их средние значения будут соответствовать фактическому среднему значению генеральной совокупности. Следовательно, мы можем предположить, что 50% средних значений будут больше среднего значения по генеральной совокупности, а 50% будут меньше этого значения (медиана). Если мы увеличим размер выборки (с 10 до 20 и до 30), все больше и больше средних значений выборки будут приближаться к среднему значению генеральной совокупности. Следовательно, среднее значение этих средних должно быть более или менее похоже на среднее значение для генеральной совокупности. Рассмотрим крайний случай, когда размер выборки равен размеру генеральной совокупности. Таким образом, для каждой выборки среднее значение будет таким же, как и среднее значение для генеральной совокупности. Это самое узкое распределение (стандартное отклонение выборочных средних, здесь равно 0). Следовательно, по мере увеличения размера выборки (с 10 до 20 и до 30) стандартное отклонение будет иметь тенденцию к уменьшению (поскольку разброс в распределении выборки будет ограничен и большая часть выборочных средних будет ориентирована на среднее значение генеральной совокупности). Это явление отражено в формуле на «Рис. 3», где стандартное отклонение выборочного распределения обратно пропорционально квадратному корню из размера выборки. Если мы возьмем все больше и больше выборок (от 1000 до 5000 и до 10 000), то кривая распределения выборки будет более гладкой, поскольку большее количество выборок будет вести себя в соответствии с центральной предельной теоремой, и картина будет более четкой. «Разговоры дешевы, покажите мне код!» - Линус Торвальдс Итак, давайте смоделируем центральную предельную теорему с помощью кода: Немного импорта: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math Создайте популяцию, используя . Вы можете попробовать разные дистрибутивы для генерации данных. Следующий код генерирует (своего рода) монотонно убывающее распределение: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population Создайте образцы и возьмите их среднее значение несколько раз: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list Функция для построения графика распределения данных вместе с некоторыми метками. def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() Основная функция для запуска кода: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) Весь код вы можете найти . здесь, на GitHub Использованная литература: Центральная предельная теорема в действии Центральная предельная теорема: практическое применение Введение в центральную предельную теорему Нежное введение в центральную предельную теорему для машинного обучения Центральная предельная теорема Авторы изображения на обложке: Кейси Данн и актерский состав Creature на Vimeo Рекомендуемое чтение (рекомендуемые видео): ханаакадемия / центральная предельная теорема Статистика машинного обучения и анализа данных Также опубликовано здесь