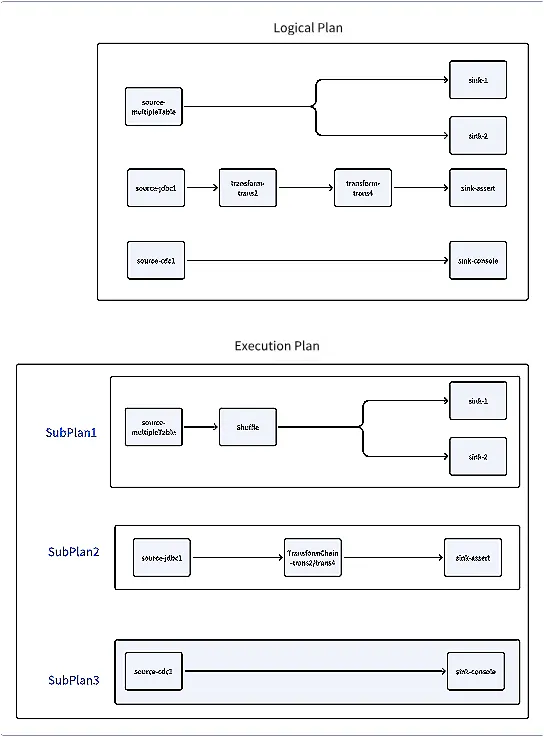
Dies ist der letzte Teil der Artikelserie zur Analyse des Quellcodes der Apache SeaTunnel Zeta Engine. Sehen Sie sich die vorherige Serie noch einmal an, um sich ein vollständiges Bild zu machen: Quellcodeanalyse der Apache SeaTunnel Zeta Engine (Teil 1): Serverinitialisierung Quellcode-Analyse der Apache SeaTunnel Zeta Engine (Teil 2): Task-Übermittlungsprozess auf der Clientseite Sehen wir uns die Komponenten an, die nach dem Start des Servers ausgeführt werden: : Nur auf Master-/Standby-Knoten aktiviert, überwacht den Clusterstatus und verarbeitet Master-Standby-Failover. CoordinatorService : Auf Arbeitsknoten aktiviert, meldet seinen Status regelmäßig an den Master. SlotService : Auf Arbeitsknoten aktiviert, aktualisiert regelmäßig die Taskmetriken auf IMAP. TaskExecutionService Wenn der Cluster keine Aufgaben empfängt, werden diese Komponenten ausgeführt. Wie geht der Server jedoch damit um, wenn ein Client eine -Nachricht an den Server sendet? SeaTunnelSubmitJobCodec Nachrichtenempfang Da sich Client und Server auf unterschiedlichen Rechnern befinden, können keine Methodenaufrufe verwendet werden. Stattdessen wird Nachrichtenübermittlung eingesetzt. Wie verarbeitet der Server eine empfangene Nachricht? Zunächst sendet der Client eine Nachricht vom Typ : SeaTunnelSubmitJobCodec // Client code ClientMessage request = SeaTunnelSubmitJobCodec.encodeRequest( jobImmutableInformation.getJobId(), seaTunnelHazelcastClient .getSerializationService() .toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint()); PassiveCompletableFuture<Void> submitJobFuture = seaTunnelHazelcastClient.requestOnMasterAndGetCompletableFuture(request); In der Klasse ist es mit einer Klasse verknüpft, die Nachrichtentypen -Klassen zuordnet. Für wird es der Klasse zugeordnet: SeaTunnelSubmitJobCodec SeaTunnelMessageTaskFactoryProvider MessageTask SeaTunnelSubmitJobCodec SubmitJobTask private final Int2ObjectHashMap<MessageTaskFactory> factories = new Int2ObjectHashMap<>(60); private void initFactories() { factories.put( SeaTunnelPrintMessageCodec.REQUEST_MESSAGE_TYPE, (clientMessage, connection) -> new PrintMessageTask(clientMessage, node, connection)); factories.put( SeaTunnelSubmitJobCodec.REQUEST_MESSAGE_TYPE, (clientMessage, connection) -> new SubmitJobTask(clientMessage, node, connection)); ..... } Beim Untersuchen der Klasse wird die Klasse aufgerufen: SubmitJobTask SubmitJobOperation @Override protected Operation prepareOperation() { return new SubmitJobOperation( parameters.jobId, parameters.jobImmutableInformation, parameters.isStartWithSavePoint); } In der Klasse werden die Aufgabeninformationen über die Methode an die Komponente übergeben: SubmitJobOperation submitJob CoordinatorService @Override protected PassiveCompletableFuture<?> doRun() throws Exception { SeaTunnelServer seaTunnelServer = getService(); return seaTunnelServer .getCoordinatorService() .submitJob(jobId, jobImmutableInformation, isStartWithSavePoint); } An diesem Punkt wird eine Client-Nachricht effektiv an den Server zum Methodenaufruf übergeben. Andere Arten von Vorgängen können auf ähnliche Weise verfolgt werden. KoordinatorService Sehen wir uns als Nächstes an, wie mit Auftragsübermittlungen umgeht: CoordinatorService public PassiveCompletableFuture<Void> submitJob( long jobId, Data jobImmutableInformation, boolean isStartWithSavePoint) { CompletableFuture<Void> jobSubmitFuture = new CompletableFuture<>(); // First, check if a job with the same ID already exists if (getJobMaster(jobId) != null) { logger.warning( String.format( "The job %s is currently running; no need to submit again.", jobId)); jobSubmitFuture.complete(null); return new PassiveCompletableFuture<>(jobSubmitFuture); } // Initialize JobMaster object JobMaster jobMaster = new JobMaster( jobImmutableInformation, this.nodeEngine, executorService, getResourceManager(), getJobHistoryService(), runningJobStateIMap, runningJobStateTimestampsIMap, ownedSlotProfilesIMap, runningJobInfoIMap, metricsImap, engineConfig, seaTunnelServer); executorService.submit( () -> { try { // Ensure no duplicate tasks with the same ID if (!isStartWithSavePoint && getJobHistoryService().getJobMetrics(jobId) != null) { throw new JobException( String.format( "The job id %s has already been submitted and is not starting with a savepoint.", jobId)); } // Add task info to IMAP runningJobInfoIMap.put( jobId, new JobInfo(System.currentTimeMillis(), jobImmutableInformation)); runningJobMasterMap.put(jobId, jobMaster); // Initialize JobMaster jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); // Task creation successful jobSubmitFuture.complete(null); } catch (Throwable e) { String errorMsg = ExceptionUtils.getMessage(e); logger.severe(String.format("submit job %s error %s ", jobId, errorMsg)); jobSubmitFuture.completeExceptionally(new JobException(errorMsg)); } if (!jobSubmitFuture.isCompletedExceptionally()) { // Start job execution try { jobMaster.run(); } finally { // Remove jobMaster from map if not cancelled if (!jobMaster.getJobMasterCompleteFuture().isCancelled()) { runningJobMasterMap.remove(jobId); } } } else { runningJobInfoIMap.remove(jobId); runningJobMasterMap.remove(jobId); } }); return new PassiveCompletableFuture<>(jobSubmitFuture); } Auf dem Server wird ein Objekt erstellt, um die einzelnen Aufgaben zu verwalten. Während der -Erstellung ruft es den Ressourcenmanager über und Informationen zum Auftragsverlauf über ab. Der wird beim Start initialisiert, während bei der ersten Aufgabenübermittlung verzögert geladen wird: JobMaster JobMaster getResourceManager() getJobHistoryService() jobHistoryService ResourceManager /** Lazy load for resource manager */ public ResourceManager getResourceManager() { if (resourceManager == null) { synchronized (this) { if (resourceManager == null) { ResourceManager manager = new ResourceManagerFactory(nodeEngine, engineConfig) .getResourceManager(); manager.init(); resourceManager = manager; } } } return resourceManager; } RessourcenManager Derzeit unterstützt SeaTunnel nur die eigenständige Bereitstellung. Beim Initialisieren werden alle Clusterknoten erfasst und eine gesendet, um Knoteninformationen abzurufen und den internen Status zu aktualisieren: ResourceManager SyncWorkerProfileOperation registerWorker @Override public void init() { log.info("Init ResourceManager"); initWorker(); } private void initWorker() { log.info("initWorker... "); List<Address> aliveNode = nodeEngine.getClusterService().getMembers().stream() .map(Member::getAddress) .collect(Collectors.toList()); log.info("init live nodes: {}", aliveNode); List<CompletableFuture<Void>> futures = aliveNode.stream() .map( node -> sendToMember(new SyncWorkerProfileOperation(), node) .thenAccept( p -> { if (p != null) { registerWorker.put( node, (WorkerProfile) p); log.info( "received new worker register: " + ((WorkerProfile) p) .getAddress()); } })) .collect(Collectors.toList()); futures.forEach(CompletableFuture::join); log.info("registerWorker: {}", registerWorker); } Zuvor haben wir beobachtet, dass regelmäßig Heartbeat-Nachrichten von jedem Knoten an den Master sendet. Nach dem Empfang dieser Heartbeats aktualisiert der die Knotenstatus in seinem internen Status. SlotService ResourceManager @Override public void heartbeat(WorkerProfile workerProfile) { if (!registerWorker.containsKey(workerProfile.getAddress())) { log.info("received new worker register: " + workerProfile.getAddress()); sendToMember(new ResetResourceOperation(), workerProfile.getAddress()).join(); } else { log.debug("received worker heartbeat from: " + workerProfile.getAddress()); } registerWorker.put(workerProfile.getAddress(), workerProfile); } JobMaster Im wird eine Instanz erstellt und deren -Methode aufgerufen. Wenn die -Methode abgeschlossen ist, gilt die Aufgabenerstellung als erfolgreich. Anschließend wird die -Methode aufgerufen, um die Aufgabe formal auszuführen. CoordinatorService JobMaster init init run Schauen wir uns die Initialisierung und -Methode an. init public JobMaster( @NonNull Data jobImmutableInformationData, @NonNull NodeEngine nodeEngine, @NonNull ExecutorService executorService, @NonNull ResourceManager resourceManager, @NonNull JobHistoryService jobHistoryService, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull IMap ownedSlotProfilesIMap, @NonNull IMap<Long, JobInfo> runningJobInfoIMap, @NonNull IMap<Long, HashMap<TaskLocation, SeaTunnelMetricsContext>> metricsImap, EngineConfig engineConfig, SeaTunnelServer seaTunnelServer) { this.jobImmutableInformationData = jobImmutableInformationData; this.nodeEngine = nodeEngine; this.executorService = executorService; flakeIdGenerator = this.nodeEngine .getHazelcastInstance() .getFlakeIdGenerator(Constant.SEATUNNEL_ID_GENERATOR_NAME); this.ownedSlotProfilesIMap = ownedSlotProfilesIMap; this.resourceManager = resourceManager; this.jobHistoryService = jobHistoryService; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.runningJobInfoIMap = runningJobInfoIMap; this.engineConfig = engineConfig; this.metricsImap = metricsImap; this.seaTunnelServer = seaTunnelServer; this.releasedSlotWhenTaskGroupFinished = new ConcurrentHashMap<>(); } Während der Initialisierung werden nur einfache Variablenzuweisungen ohne nennenswerte Operationen durchgeführt. Wir müssen uns auf die -Methode konzentrieren. init public synchronized void init(long initializationTimestamp, boolean restart) throws Exception { // The server receives a binary object from the client, // which is first converted to a JobImmutableInformation object, the same object sent by the client jobImmutableInformation = nodeEngine.getSerializationService().toObject(jobImmutableInformationData); // Get the checkpoint configuration, such as the interval, timeout, etc. jobCheckpointConfig = createJobCheckpointConfig( engineConfig.getCheckpointConfig(), jobImmutableInformation.getJobConfig()); LOGGER.info( String.format( "Init JobMaster for Job %s (%s) ", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId())); LOGGER.info( String.format( "Job %s (%s) needed jar urls %s", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls())); ClassLoader appClassLoader = Thread.currentThread().getContextClassLoader(); // Get the ClassLoader ClassLoader classLoader = seaTunnelServer .getClassLoaderService() .getClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); // Deserialize the logical DAG from the client-provided information logicalDag = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, jobImmutableInformation.getLogicalDag()); try { Thread.currentThread().setContextClassLoader(classLoader); // Execute save mode functionality, such as table creation and deletion if (!restart && !logicalDag.isStartWithSavePoint() && ReadonlyConfig.fromMap(logicalDag.getJobConfig().getEnvOptions()) .get(EnvCommonOptions.SAVEMODE_EXECUTE_LOCATION) .equals(SaveModeExecuteLocation.CLUSTER)) { logicalDag.getLogicalVertexMap().values().stream() .map(LogicalVertex::getAction) .filter(action -> action instanceof SinkAction) .map(sink -> ((SinkAction<?, ?, ?, ?>) sink).getSink()) .forEach(JobMaster::handleSaveMode); } // Parse the logical plan into a physical plan final Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> planTuple = PlanUtils.fromLogicalDAG( logicalDag, nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, engineConfig.getQueueType(), engineConfig); this.physicalPlan = planTuple.f0(); this.physicalPlan.setJobMaster(this); this.checkpointPlanMap = planTuple.f1(); } finally { // Reset the current thread's ClassLoader and release the created classLoader Thread.currentThread().setContextClassLoader(appClassLoader); seaTunnelServer .getClassLoaderService() .releaseClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); } Exception initException = null; try { // Initialize the checkpoint manager this.initCheckPointManager(restart); } catch (Exception e) { initException = e; } // Add some callback functions for job state listening this.initStateFuture(); if (initException != null) { if (restart) { cancelJob(); } throw initException; } } Schauen wir uns zum Schluss die -Methode an: run public void run() { try { physicalPlan.startJob(); } catch (Throwable e) { LOGGER.severe( String.format( "Job %s (%s) run error with: %s", physicalPlan.getJobImmutableInformation().getJobConfig().getName(), physicalPlan.getJobImmutableInformation().getJobId(), ExceptionUtils.getMessage(e))); } finally { jobMasterCompleteFuture.join(); if (engineConfig.getConnectorJarStorageConfig().getEnable()) { List<ConnectorJarIdentifier> pluginJarIdentifiers = jobImmutableInformation.getPluginJarIdentifiers(); seaTunnelServer .getConnectorPackageService() .cleanUpWhenJobFinished( jobImmutableInformation.getJobId(), pluginJarIdentifiers); } } } Diese Methode ist relativ unkompliziert und ruft auf, um den generierten physischen Plan auszuführen. physicalPlan.startJob() Aus dem obigen Code ist ersichtlich, dass der Server, nachdem er eine Client-Task-Übermittlungsanforderung empfangen hat, die -Klasse initialisiert, die den physischen Plan aus dem logischen Plan generiert und dann den physischen Plan ausführt. JobMaster Als Nächstes müssen wir uns damit befassen, wie der logische Plan in einen physischen Plan umgewandelt wird. Konvertierung vom logischen Plan zum physischen Plan Die Generierung des physischen Plans erfolgt durch den Aufruf der folgenden Methode im : JobMaster final Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> planTuple = PlanUtils.fromLogicalDAG( logicalDag, nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, engineConfig.getQueueType(), engineConfig); Bei der Methode zum Generieren des physischen Plans wird zunächst der logische Plan in einen Ausführungsplan umgewandelt und anschließend der Ausführungsplan in einen physischen Plan umgewandelt. public static Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> fromLogicalDAG( @NonNull LogicalDag logicalDag, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType, @NonNull EngineConfig engineConfig) { return new PhysicalPlanGenerator( new ExecutionPlanGenerator( logicalDag, jobImmutableInformation, engineConfig) .generate(), nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, queueType) .generate(); } Generierung des Ausführungsplans public ExecutionPlanGenerator( @NonNull LogicalDag logicalPlan, @NonNull JobImmutableInformation jobImmutableInformation, @NonNull EngineConfig engineConfig) { checkArgument( logicalPlan.getEdges().size() > 0, "ExecutionPlan Builder must have LogicalPlan."); this.logicalPlan = logicalPlan; this.jobImmutableInformation = jobImmutableInformation; this.engineConfig = engineConfig; } public ExecutionPlan generate() { log.debug("Generate execution plan using logical plan:"); Set<ExecutionEdge> executionEdges = generateExecutionEdges(logicalPlan.getEdges()); log.debug("Phase 1: generate execution edge list {}", executionEdges); executionEdges = generateShuffleEdges(executionEdges); log.debug("Phase 2: generate shuffle edge list {}", executionEdges); executionEdges = generateTransformChainEdges(executionEdges); log.debug("Phase 3: generate transform chain edge list {}", executionEdges); List<Pipeline> pipelines = generatePipelines(executionEdges); log.debug("Phase 4: generate pipeline list {}", pipelines); ExecutionPlan executionPlan = new ExecutionPlan(pipelines, jobImmutableInformation); log.debug("Phase 5 : generate execution plan {}", executionPlan); return executionPlan; } Die Klasse nimmt einen logischen Plan und erstellt durch eine Reihe von Schritten einen Ausführungsplan, einschließlich der Generierung von Ausführungskanten, Shuffle-Kanten, Transform-Chain-Kanten und schließlich Pipelines. ExecutionPlanGenerator Erstellung des Bauplans Die Klasse wandelt den Ausführungsplan in einen physischen Plan um: PhysicalPlanGenerator public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.executionPlan = executionPlan; this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public PhysicalPlan generate() { List<PhysicalVertex> physicalVertices = generatePhysicalVertices(executionPlan); List<PhysicalEdge> physicalEdges = generatePhysicalEdges(executionPlan); PhysicalPlan physicalPlan = new PhysicalPlan(physicalVertices, physicalEdges); log.debug("Generate physical plan: {}", physicalPlan); return physicalPlan; } Lassen Sie uns den Inhalt dieser beiden Klassen untersuchen. public class ExecutionPlan { private final List<Pipeline> pipelines; private final JobImmutableInformation jobImmutableInformation; } public class Pipeline { /** The ID of the pipeline. */ private final Integer id; private final List<ExecutionEdge> edges; private final Map<Long, ExecutionVertex> vertexes; } public class ExecutionEdge { private ExecutionVertex leftVertex; private ExecutionVertex rightVertex; } public class ExecutionVertex { private Long vertexId; private Action action; private int parallelism; } Vergleichen wir es mit dem logischen Plan: public class LogicalDag implements IdentifiedDataSerializable { @Getter private JobConfig jobConfig; private final Set<LogicalEdge> edges = new LinkedHashSet<>(); private final Map<Long, LogicalVertex> logicalVertexMap = new LinkedHashMap<>(); private IdGenerator idGenerator; private boolean isStartWithSavePoint = false; } public class LogicalEdge implements IdentifiedDataSerializable { private LogicalVertex inputVertex; private LogicalVertex targetVertex; private Long inputVertexId; private Long targetVertexId; } public class LogicalVertex implements IdentifiedDataSerializable { private Long vertexId; private Action action; private int parallelism; } Es scheint, dass jede Pipeline einem logischen Plan ähnelt. Warum brauchen wir diesen Transformationsschritt? Schauen wir uns den Prozess der Generierung eines logischen Plans genauer an. Wie oben gezeigt umfasst das Erstellen eines Ausführungsplans fünf Schritte, die wir nacheinander durchgehen werden. Schritt 1: Konvertieren des logischen Plans in einen Ausführungsplan // Input is a set of logical plan edges, where each edge stores upstream and downstream nodes private Set<ExecutionEdge> generateExecutionEdges(Set<LogicalEdge> logicalEdges) { Set<ExecutionEdge> executionEdges = new LinkedHashSet<>(); Map<Long, ExecutionVertex> logicalVertexIdToExecutionVertexMap = new HashMap(); // Sort in order: first by input node, then by output node List<LogicalEdge> sortedLogicalEdges = new ArrayList<>(logicalEdges); Collections.sort( sortedLogicalEdges, (o1, o2) -> { if (o1.getInputVertexId() != o2.getInputVertexId()) { return o1.getInputVertexId() > o2.getInputVertexId() ? 1 : -1; } if (o1.getTargetVertexId() != o2.getTargetVertexId()) { return o1.getTargetVertexId() > o2.getTargetVertexId() ? 1 : -1; } return 0; }); // Loop to convert each logical plan edge to an execution plan edge for (LogicalEdge logicalEdge : sortedLogicalEdges) { LogicalVertex logicalInputVertex = logicalEdge.getInputVertex(); ExecutionVertex executionInputVertex = logicalVertexIdToExecutionVertexMap.computeIfAbsent( logicalInputVertex.getVertexId(), vertexId -> { long newId = idGenerator.getNextId(); // Recreate Action for each logical plan node Action newLogicalInputAction = recreateAction( logicalInputVertex.getAction(), newId, logicalInputVertex.getParallelism()); // Convert to execution plan node return new ExecutionVertex( newId, newLogicalInputAction, logicalInputVertex.getParallelism()); }); // Similarly, recreate execution plan nodes for target nodes LogicalVertex logicalTargetVertex = logicalEdge.getTargetVertex(); ExecutionVertex executionTargetVertex = logicalVertexIdToExecutionVertexMap.computeIfAbsent( logicalTargetVertex.getVertexId(), vertexId -> { long newId = idGenerator.getNextId(); Action newLogicalTargetAction = recreateAction( logicalTargetVertex.getAction(), newId, logicalTargetVertex.getParallelism()); return new ExecutionVertex( newId, newLogicalTargetAction, logicalTargetVertex.getParallelism()); }); // Generate execution plan edge ExecutionEdge executionEdge = new ExecutionEdge(executionInputVertex, executionTargetVertex); executionEdges.add(executionEdge); } return executionEdges; } Schritt 2 private Set<ExecutionEdge> generateShuffleEdges(Set<ExecutionEdge> executionEdges) { // Map of upstream node ID to list of downstream nodes Map<Long, List<ExecutionVertex>> targetVerticesMap = new LinkedHashMap<>(); // Store only nodes of type Source Set<ExecutionVertex> sourceExecutionVertices = new HashSet<>(); executionEdges.forEach( edge -> { ExecutionVertex leftVertex = edge.getLeftVertex(); ExecutionVertex rightVertex = edge.getRightVertex(); if (leftVertex.getAction() instanceof SourceAction) { sourceExecutionVertices.add(leftVertex); } targetVerticesMap .computeIfAbsent(leftVertex.getVertexId(), id -> new ArrayList<>()) .add(rightVertex); }); if (sourceExecutionVertices.size() != 1) { return executionEdges; } ExecutionVertex sourceExecutionVertex = sourceExecutionVertices.stream().findFirst().get(); Action sourceAction = sourceExecutionVertex.getAction(); List<CatalogTable> producedCatalogTables = new ArrayList<>(); if (sourceAction instanceof SourceAction) { try { producedCatalogTables = ((SourceAction<?, ?, ?>) sourceAction) .getSource() .getProducedCatalogTables(); } catch (UnsupportedOperationException e) { } } else if (sourceAction instanceof TransformChainAction) { return executionEdges; } else { throw new SeaTunnelException( "source action must be SourceAction or TransformChainAction"); } // If the source produces a single table or // the source has only one downstream output, return directly if (producedCatalogTables.size() <= 1 || targetVerticesMap.get(sourceExecutionVertex.getVertexId()).size() <= 1) { return executionEdges; } List<ExecutionVertex> sinkVertices = targetVerticesMap.get(sourceExecutionVertex.getVertexId()); // Check if there are other types of actions, currently downstream nodes should ideally have two types: Transform and Sink; here we check if only Sink type is present Optional<ExecutionVertex> hasOtherAction = sinkVertices.stream() .filter(vertex -> !(vertex.getAction() instanceof SinkAction)) .findFirst(); checkArgument(!hasOtherAction.isPresent()); // After executing the above code, the current scenario is: // There is only one data source, this source produces multiple tables, and multiple sink nodes depend on these tables // This means the task has only two types of nodes: a source node that produces multiple tables and a group of sink nodes depending on this source // A new shuffle node will be created and added between the source and sinks // Modify the dependency relationship to source -> shuffle -> multiple sinks Set<ExecutionEdge> newExecutionEdges = new LinkedHashSet<>(); // Shuffle strategy will not be explored in detail here ShuffleStrategy shuffleStrategy = ShuffleMultipleRowStrategy.builder() .jobId(jobImmutableInformation.getJobId()) .inputPartitions(sourceAction.getParallelism()) .catalogTables(producedCatalogTables) .queueEmptyQueueTtl( (int) (engineConfig.getCheckpointConfig().getCheckpointInterval() * 3)) .build(); ShuffleConfig shuffleConfig = ShuffleConfig.builder().shuffleStrategy(shuffleStrategy).build(); long shuffleVertexId = idGenerator.getNextId(); String shuffleActionName = String.format("Shuffle [%s]", sourceAction.getName()); ShuffleAction shuffleAction = new ShuffleAction(shuffleVertexId, shuffleActionName, shuffleConfig); shuffleAction.setParallelism(sourceAction.getParallelism()); ExecutionVertex shuffleVertex = new ExecutionVertex(shuffleVertexId, shuffleAction, shuffleAction.getParallelism()); ExecutionEdge sourceToShuffleEdge = new ExecutionEdge(sourceExecutionVertex, shuffleVertex); newExecutionEdges.add(sourceToShuffleEdge); // Set the parallelism of multiple sink nodes to 1 for (ExecutionVertex sinkVertex : sinkVertices) { sinkVertex.setParallelism(1); sinkVertex.getAction().setParallelism(1); ExecutionEdge shuffleToSinkEdge = new ExecutionEdge(shuffleVertex, sinkVertex); newExecutionEdges.add(shuffleToSinkEdge); } return newExecutionEdges; } Der Shuffle-Schritt befasst sich mit bestimmten Szenarien, in denen die Quelle das Lesen mehrerer Tabellen unterstützt und mehrere Senkenknoten von dieser Quelle abhängig sind. In solchen Fällen wird dazwischen ein Shuffle-Knoten hinzugefügt. Schritt 3 private Set<ExecutionEdge> generateTransformChainEdges(Set<ExecutionEdge> executionEdges) { // Uses three structures: stores all Source nodes and the input/output nodes for each // inputVerticesMap stores all upstream input nodes by downstream node id as the key // targetVerticesMap stores all downstream output nodes by upstream node id as the key Map<Long, List<ExecutionVertex>> inputVerticesMap = new HashMap<>(); Map<Long, List<ExecutionVertex>> targetVerticesMap = new HashMap<>(); Set<ExecutionVertex> sourceExecutionVertices = new HashSet<>(); executionEdges.forEach( edge -> { ExecutionVertex leftVertex = edge.getLeftVertex(); ExecutionVertex rightVertex = edge.getRightVertex(); if (leftVertex.getAction() instanceof SourceAction) { sourceExecutionVertices.add(leftVertex); } inputVerticesMap .computeIfAbsent(rightVertex.getVertexId(), id -> new ArrayList<>()) .add(leftVertex); targetVerticesMap .computeIfAbsent(leftVertex.getVertexId(), id -> new ArrayList<>()) .add(rightVertex); }); Map<Long, ExecutionVertex> transformChainVertexMap = new HashMap<>(); Map<Long, Long> chainedTransformVerticesMapping = new HashMap<>(); // Loop over each source, starting with all head nodes in the DAG for (ExecutionVertex sourceVertex : sourceExecutionVertices) { List<ExecutionVertex> vertices = new ArrayList<>(); vertices.add(sourceVertex); for (int index = 0; index < vertices.size(); index++) { ExecutionVertex vertex = vertices.get(index); fillChainedTransformExecutionVertex( vertex, chainedTransformVerticesMapping, transformChainVertexMap, executionEdges, Collections.unmodifiableMap(inputVerticesMap), Collections.unmodifiableMap(targetVerticesMap)); // If the current node has downstream nodes, add all downstream nodes to the list // The second loop will recalculate the newly added downstream nodes, which could be Transform nodes or Sink nodes if (targetVerticesMap.containsKey(vertex.getVertexId())) { vertices.addAll(targetVerticesMap.get(vertex.getVertexId())); } } } // After looping, chained Transform nodes will be chained, and the chainable edges will be removed from the execution plan // Therefore, the logical plan at this point cannot form the graph relationship and needs to be rebuilt Set<ExecutionEdge> transformChainEdges = new LinkedHashSet<>(); // Loop over existing relationships for (ExecutionEdge executionEdge : executionEdges) { ExecutionVertex leftVertex = executionEdge.getLeftVertex(); ExecutionVertex rightVertex = executionEdge.getRightVertex(); boolean needRebuild = false; // Check if the input or output nodes of the current edge are in the chain mapping // If so, the node has been chained, and we need to find the chained node in the mapping // and rebuild the DAG if (chainedTransformVerticesMapping.containsKey(leftVertex.getVertexId())) { needRebuild = true; leftVertex = transformChainVertexMap.get( chainedTransformVerticesMapping.get(leftVertex.getVertexId())); } if (chainedTransformVerticesMapping.containsKey(rightVertex.getVertexId())) { needRebuild = true; rightVertex = transformChainVertexMap.get( chainedTransformVerticesMapping.get(rightVertex.getVertexId())); } if (needRebuild) { executionEdge = new ExecutionEdge(leftVertex, rightVertex); } transformChainEdges.add(executionEdge); } return transformChainEdges; } private void fillChainedTransformExecutionVertex( ExecutionVertex currentVertex, Map<Long, Long> chainedTransformVerticesMapping, Map<Long, ExecutionVertex> transformChainVertexMap, Set<ExecutionEdge> executionEdges, Map<Long, List<ExecutionVertex>> inputVerticesMap, Map<Long, List<ExecutionVertex>> targetVerticesMap) { // Exit if the map already contains the current node if (chainedTransformVerticesMapping.containsKey(currentVertex.getVertexId())) { return; } List<ExecutionVertex> transformChainedVertices = new ArrayList<>(); collectChainedVertices( currentVertex, transformChainedVertices, executionEdges, inputVerticesMap, targetVerticesMap); // If the list is not empty, it means the Transform nodes in the list can be merged into one if (transformChainedVertices.size() > 0) { long newVertexId = idGenerator.getNextId(); List<SeaTunnelTransform> transforms = new ArrayList<>(transformChainedVertices.size()); List<String> names = new ArrayList<>(transformChainedVertices.size()); Set<URL> jars = new HashSet<>(); Set<ConnectorJarIdentifier> identifiers = new HashSet<>(); transformChainedVertices.stream() .peek( // Add all historical node IDs and new node IDs to the mapping vertex -> chainedTransformVerticesMapping.put( vertex.getVertexId(), newVertexId)) .map(ExecutionVertex::getAction) .map(action -> (TransformAction) action) .forEach( action -> { transforms.add(action.getTransform()); jars.addAll(action.getJarUrls()); identifiers.addAll(action.getConnectorJarIdentifiers()); names.add(action.getName()); }); String transformChainActionName = String.format("TransformChain[%s]", String.join("->", names)); // Merge multiple TransformActions into one TransformChainAction TransformChainAction transformChainAction = new TransformChainAction( newVertexId, transformChainActionName, jars, identifiers, transforms); transformChainAction.setParallelism(currentVertex.getAction().getParallelism()); ExecutionVertex executionVertex = new ExecutionVertex( newVertexId, transformChainAction, currentVertex.getParallelism()); // Store the modified node information in the state transformChainVertexMap.put(newVertexId, executionVertex); chainedTransformVerticesMapping.put( currentVertex.getVertexId(), executionVertex.getVertexId()); } } private void collectChainedVertices( ExecutionVertex currentVertex, List<ExecutionVertex> chainedVertices, Set<ExecutionEdge> executionEdges, Map<Long, List<ExecutionVertex>> inputVerticesMap, Map<Long, List<ExecutionVertex>> targetVerticesMap) { Action action = currentVertex.getAction(); // Only merge TransformAction if (action instanceof TransformAction) { if (chainedVertices.size() == 0) { // If the list of vertices to be merged is empty, add itself to the list // The condition for entering this branch is that the current node is a TransformAction and the list to be merged is empty // There may be several scenarios: the first Transform node enters, and this Transform node has no constraints chainedVertices.add(currentVertex); } else if (inputVerticesMap.get(currentVertex.getVertexId()).size() == 1) { // When this condition is entered, it means: // The list of vertices to be merged already has at least one TransformAction // The scenario at this point is that the upstream Transform node has only one downstream node, ie, the current node. This constraint is ensured by the following judgment // Chain the current TransformAction node with the previous TransformAction node // Delete this relationship from the execution plan executionEdges.remove( new ExecutionEdge( chainedVertices.get(chainedVertices.size() - 1), currentVertex)); // Add itself to the list of nodes to be merged chainedVertices.add(currentVertex); } else { return; } } else { return; } // It cannot chain to any target vertex if it has multiple target vertices. if (targetVerticesMap.get(currentVertex.getVertexId()).size() == 1) { // If the current node has only one downstream node, try chaining again // If the current node has multiple downstream nodes, it will not chain the downstream nodes, so it can be ensured that the above chaining is a one-to-one relationship // This call occurs when the Transform node has only one downstream node collectChainedVertices( targetVerticesMap.get(currentVertex.getVertexId()).get(0), chainedVertices, executionEdges, inputVerticesMap, targetVerticesMap); } } Schritt 4 private List<Pipeline> generatePipelines(Set<ExecutionEdge> executionEdges) { // Stores each execution plan node Set<ExecutionVertex> executionVertices = new LinkedHashSet<>(); for (ExecutionEdge edge : executionEdges) { executionVertices.add(edge.getLeftVertex()); executionVertices.add(edge.getRightVertex()); } // Calls the Pipeline generator to convert the execution plan into Pipelines PipelineGenerator pipelineGenerator = new PipelineGenerator(executionVertices, new ArrayList<>(executionEdges)); List<Pipeline> pipelines = pipelineGenerator.generatePipelines(); Set<String> duplicatedActionNames = new HashSet<>(); Set<String> actionNames = new HashSet<>(); for (Pipeline pipeline : pipelines) { Integer pipelineId = pipeline.getId(); for (ExecutionVertex vertex : pipeline.getVertexes().values()) { // Get each execution node of the current Pipeline, reset the Action name, and add the pipeline name Action action = vertex.getAction(); String actionName = String.format("pipeline-%s [%s]", pipelineId, action.getName()); action.setName(actionName); if (actionNames.contains(actionName)) { duplicatedActionNames.add(actionName); } actionNames.add(action Name); } } if (duplicatedActionNames.size() > 0) { throw new RuntimeException( String.format( "Duplicated Action names found: %s", duplicatedActionNames)); } return pipelines; } public PipelineGenerator(Collection<ExecutionVertex> vertices, List<ExecutionEdge> edges) { this.vertices = vertices; this.edges = edges; } public List<Pipeline> generatePipelines() { List<ExecutionEdge> executionEdges = expandEdgeByParallelism(edges); // Split the execution plan into unrelated execution plans based on their relationships // Divide into several unrelated execution plans List<List<ExecutionEdge>> edgesList = splitUnrelatedEdges(executionEdges); edgesList = edgesList.stream() .flatMap(e -> this.splitUnionEdge(e).stream()) .collect(Collectors.toList()); // Just convert execution plan to pipeline at now. We should split it to multi pipeline with // cache in the future IdGenerator idGenerator = new IdGenerator(); // Convert execution plan graph to Pipeline return edgesList.stream() .map( e -> { Map<Long, ExecutionVertex> vertexes = new HashMap<>(); List<ExecutionEdge> pipelineEdges = e.stream() .map( edge -> { if (!vertexes.containsKey( edge.getLeftVertexId())) { vertexes.put( edge.getLeftVertexId(), edge.getLeftVertex()); } ExecutionVertex source = vertexes.get( edge.getLeftVertexId()); if (!vertexes.containsKey( edge.getRightVertexId())) { vertexes.put( edge.getRightVertexId(), edge.getRightVertex()); } ExecutionVertex destination = vertexes.get( edge.getRightVertexId()); return new ExecutionEdge( source, destination); }) .collect(Collectors.toList()); return new Pipeline( (int) idGenerator.getNextId(), pipelineEdges, vertexes); }) .collect(Collectors.toList()); } Schritt 5 Im fünften Schritt werden die Ausführungsplaninstanzen generiert und die im vierten Schritt generierten Pipeline-Parameter übergeben. Zusammenfassung: Der Ausführungsplan führt die folgenden Aufgaben für den logischen Plan aus: Wenn eine Quelle mehrere Tabellen generiert und mehrere Senkenknoten von dieser Quelle abhängen, wird dazwischen ein Shuffle-Knoten hinzugefügt. Versuchen Sie, Transformationsknoten zu verketten und mehrere Transformationsknoten zu einem Knoten zu kombinieren. Teilen Sie die Aufgaben auf, indem Sie eine in mehrere unabhängige Aufgaben unterteilen, die als dargestellt werden. configuration file/LogicalDag List<Pipeline> Erstellung von physischen Plänen Bevor wir uns mit der Erstellung des physischen Plans befassen, wollen wir zunächst überprüfen, welche Informationen im erstellten physischen Plan enthalten sind, und seine internen Komponenten untersuchen. public class PhysicalPlan { private final List<SubPlan> pipelineList; private final AtomicInteger finishedPipelineNum = new AtomicInteger(0); private final AtomicInteger canceledPipelineNum = new AtomicInteger(0); private final AtomicInteger failedPipelineNum = new AtomicInteger(0); private final JobImmutableInformation jobImmutableInformation; private final IMap<Object, Object> runningJobStateIMap; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private CompletableFuture<JobResult> jobEndFuture; private final AtomicReference<String> errorBySubPlan = new AtomicReference<>(); private final String jobFullName; private final long jobId; private JobMaster jobMaster; private boolean makeJobEndWhenPipelineEnded = true; private volatile boolean isRunning = false; } In dieser Klasse ist ein Schlüsselfeld, das eine Liste von -Instanzen darstellt: pipelineList SubPlan public class SubPlan { private final int pipelineMaxRestoreNum; private final int pipelineRestoreIntervalSeconds; private final List<PhysicalVertex> physicalVertexList; private final List<PhysicalVertex> coordinatorVertexList; private final int pipelineId; private final AtomicInteger finishedTaskNum = new AtomicInteger(0); private final AtomicInteger canceledTaskNum = new AtomicInteger(0); private final AtomicInteger failedTaskNum = new AtomicInteger(0); private final String pipelineFullName; private final IMap<Object, Object> runningJobStateIMap; private final Map<String, String> tags; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private CompletableFuture<PipelineExecutionState> pipelineFuture; private final PipelineLocation pipelineLocation; private AtomicReference<String> errorByPhysicalVertex = new AtomicReference<>(); private final ExecutorService executorService; private JobMaster jobMaster; private PassiveCompletableFuture<Void> reSchedulerPipelineFuture; private Integer pipelineRestoreNum; private final Object restoreLock = new Object(); private volatile PipelineStatus currPipelineStatus; public volatile boolean isRunning = false; private Map<TaskGroupLocation, SlotProfile> slotProfiles; } Die Klasse verwaltet eine Liste von -Instanzen, unterteilt in physische Planknoten und Koordinatorknoten: SubPlan PhysicalVertex public class PhysicalVertex { private final TaskGroupLocation taskGroupLocation; private final String taskFullName; private final TaskGroupDefaultImpl taskGroup; private final ExecutorService executorService; private final FlakeIdGenerator flakeIdGenerator; private final Set<URL> pluginJarsUrls; private final Set<ConnectorJarIdentifier> connectorJarIdentifiers; private final IMap<Object, Object> runningJobStateIMap; private CompletableFuture<TaskExecutionState> taskFuture; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private final NodeEngine nodeEngine; private JobMaster jobMaster; private volatile ExecutionState currExecutionState = ExecutionState.CREATED; public volatile boolean isRunning = false; private AtomicReference<String> errorByPhysicalVertex = new AtomicReference<>(); } public class TaskGroupDefaultImpl implements TaskGroup { private final TaskGroupLocation taskGroupLocation; private final String taskGroupName; // Stores the tasks that the physical node needs to execute // Each task could be for reading data, writing data, data splitting, checkpoint tasks, etc. private final Map<Long, Task> tasks; } Der ist für die Konvertierung des Ausführungsplans in und das Hinzufügen verschiedener Koordinierungsaufgaben wie Datenaufteilung, Datenübergabe und Checkpoint-Aufgaben während der Ausführung verantwortlich. PhysicalPlanGenerator SeaTunnelTask public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.pipelines = executionPlan.getPipelines(); this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; // the checkpoint of a pipeline this.pipelineTasks = new HashSet<>(); this.startingTasks = new HashSet<>(); this.subtaskActions = new HashMap<>(); this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> generate() { // Get the node filter conditions from user configuration to select the nodes where tasks will run Map<String, String> tagFilter = (Map<String, String>) jobImmutableInformation .getJobConfig() .getEnvOptions() .get(EnvCommonOptions.NODE_TAG_FILTER.key()); // TODO Determine which tasks do not need to be restored according to state CopyOnWriteArrayList<PassiveCompletableFuture<PipelineStatus>> waitForCompleteBySubPlanList = new CopyOnWriteArrayList<>(); Map<Integer, CheckpointPlan> checkpointPlans = new HashMap<>(); final int totalPipelineNum = pipelines.size(); Stream<SubPlan> subPlanStream = pipelines.stream() .map( pipeline -> { // Clear the state each time this.pipelineTasks.clear(); this.startingTasks.clear(); this.subtaskActions.clear(); final int pipelineId = pipeline.getId(); // Get current task information final List<ExecutionEdge> edges = pipeline.getEdges(); // Get all SourceActions List<SourceAction<?, ?, ?>> sources = findSourceAction(edges); // Generate Source data slice tasks, ie, SourceSplitEnumeratorTask // This task calls the SourceSplitEnumerator class in the connector if supported List<PhysicalVertex> coordinatorVertexList = getEnumeratorTask( sources, pipelineId, totalPipelineNum); // Generate Sink commit tasks, ie, SinkAggregatedCommitterTask // This task calls the SinkAggregatedCommitter class in the connector if supported // These two tasks are executed as coordination tasks coordinatorVertexList.addAll( getCommitterTask(edges, pipelineId, totalPipelineNum)); List<PhysicalVertex> physicalVertexList = getSourceTask( edges, sources, pipelineId, totalPipelineNum); // physicalVertexList.addAll( getShuffleTask(edges, pipelineId, totalPipelineNum)); CompletableFuture<PipelineStatus> pipelineFuture = new CompletableFuture<>(); waitForCompleteBySubPlanList.add( new PassiveCompletableFuture<>(pipelineFuture)); // Add checkpoint tasks checkpointPlans.put( pipelineId, CheckpointPlan.builder() .pipelineId(pipelineId) .pipelineSubtasks(pipelineTasks) .startingSubtasks(startingTasks) .pipelineActions(pipeline.getActions()) .subtaskActions(subtaskActions) .build()); return new SubPlan( pipelineId, totalPipelineNum, initializationTimestamp, physicalVertexList, coordinatorVertexList, jobImmutableInformation, executorService, runningJobStateIMap, runningJobStateTimestampsIMap, tagFilter); }); PhysicalPlan physicalPlan = new PhysicalPlan( subPlanStream.collect(Collectors.toList()), executorService, jobImmutableInformation, initializationTimestamp, runningJobStateIMap, runningJobStateTimestampsIMap); return Tuple2.tuple2(physicalPlan, checkpointPlans); } Der Prozess der Generierung des physischen Plans umfasst die Konvertierung des Ausführungsplans in und das Hinzufügen verschiedener Koordinierungsaufgaben, z. B. Datenaufteilungsaufgaben, Datenübergabeaufgaben und Checkpoint-Aufgaben. SeaTunnelTask In werden Aufgaben in , , , und umgewandelt. SeaTunnelTask SourceFlowLifeCycle SinkFlowLifeCycle TransformFlowLifeCycle ShuffleSinkFlowLifeCycle ShuffleSourceFlowLifeCycle Beispielsweise lauten die Klassen und wie folgt: SourceFlowLifeCycle SinkFlowLifeCycle QuelleFlowLifeCycle @Override public void init() throws Exception { this.splitSerializer = sourceAction.getSource().getSplitSerializer(); this.reader = sourceAction .getSource() .createReader( new SourceReaderContext( indexID, sourceAction.getSource().getBoundedness(), this, metricsContext, eventListener)); this.enumeratorTaskAddress = getEnumeratorTaskAddress(); } @Override public void open() throws Exception { reader.open(); register(); } public void collect() throws Exception { if (!prepareClose) { if (schemaChanging()) { log.debug("schema is changing, stop reader collect records"); Thread.sleep(200); return; } reader.pollNext(collector); if (collector.isEmptyThisPollNext()) { Thread.sleep(100); } else { collector.resetEmptyThisPollNext(); /** * The current thread obtain a checkpoint lock in the method {@link * SourceReader#pollNext( Collector)}. When trigger the checkpoint or savepoint, * other threads try to obtain the lock in the method {@link * SourceFlowLifeCycle#triggerBarrier(Barrier)}. When high CPU load, checkpoint * process may be blocked as long time. So we need sleep to free the CPU. */ Thread.sleep(0L); } if (collector.captureSchemaChangeBeforeCheckpointSignal()) { if (schemaChangePhase.get() != null) { throw new IllegalStateException( "previous schema changes in progress, schemaChangePhase: " + schemaChangePhase.get()); } schemaChangePhase.set(SchemaChangePhase.createBeforePhase()); runningTask.triggerSchemaChangeBeforeCheckpoint().get(); log.info("triggered schema-change-before checkpoint, stopping collect data"); } else if (collector.captureSchemaChangeAfterCheckpointSignal()) { if (schemaChangePhase.get() != null) { throw new IllegalStateException( "previous schema changes in progress, schemaChangePhase: " + schemaChangePhase.get()); } schemaChangePhase.set(SchemaChangePhase.createAfterPhase()); runningTask.triggerSchemaChangeAfterCheckpoint().get(); log.info("triggered schema-change-after checkpoint, stopping collect data"); } } else { Thread.sleep(100); } } In wird das Lesen von Daten in der Methode durchgeführt. Sobald die Daten gelesen sind, werden sie in abgelegt. Wenn Daten empfangen werden, aktualisiert der Collector die Metriken und sendet die Daten an nachgelagerte Komponenten. SourceFlowLifeCycle collect SeaTunnelSourceCollector @Override public void collect(T row) { try { if (row instanceof SeaTunnelRow) { String tableId = ((SeaTunnelRow) row).getTableId(); int size; if (rowType instanceof SeaTunnelRowType) { size = ((SeaTunnelRow) row).getBytesSize((SeaTunnelRowType) rowType); } else if (rowType instanceof MultipleRowType) { size = ((SeaTunnelRow) row).getBytesSize(rowTypeMap.get(tableId)); } else { throw new SeaTunnelEngineException( "Unsupported row type: " + rowType.getClass().getName()); } sourceReceivedBytes.inc(size); sourceReceivedBytesPerSeconds.markEvent(size); flowControlGate.audit((SeaTunnelRow) row); if (StringUtils.isNotEmpty(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sourceTableCounter = sourceReceivedCountPerTable.get(tableName); if (Objects.nonNull(sourceTableCounter)) { sourceTableCounter.inc(); } else { Counter counter = metricsContext.counter(SOURCE_RECEIVED_COUNT + "#" + tableName); counter.inc(); sourceReceivedCountPerTable.put(tableName, counter); } } } sendRecordToNext(new Record<>(row)); emptyThisPollNext = false; sourceReceivedCount.inc(); sourceReceivedQPS.markEvent(); } catch (IOException e) { throw new RuntimeException(e); } } public void sendRecordToNext(Record<?> record) throws IOException { synchronized (checkpointLock) { for (OneInputFlowLifeCycle<Record<?>> output : outputs) { output.received(record); } } } SenkeFlowLifeCycle @Override public void received(Record<?> record) { try { if (record.getData() instanceof Barrier) { long startTime = System.currentTimeMillis(); Barrier barrier = (Barrier) record.getData(); if (barrier.prepareClose(this.taskLocation)) { prepareClose = true; } if (barrier.snapshot()) { try { lastCommitInfo = writer.prepareCommit(); } catch (Exception e) { writer.abortPrepare(); throw e; } List<StateT> states = writer.snapshotState(barrier.getId()); if (!writerStateSerializer.isPresent()) { runningTask.addState( barrier, ActionStateKey.of(sinkAction), Collections.emptyList()); } else { runningTask.addState( barrier, ActionStateKey.of(sinkAction), serializeStates(writerStateSerializer.get(), states)); } if (containAggCommitter) { CommitInfoT commitInfoT = null; if (lastCommitInfo.isPresent()) { commitInfoT = lastCommitInfo.get(); } runningTask .getExecutionContext() .sendToMember( new SinkPrepareCommitOperation<CommitInfoT>( barrier, committerTaskLocation, commitInfoSerializer.isPresent() ? commitInfoSerializer .get() .serialize(commitInfoT) : null), committerTaskAddress) .join(); } } else { if (containAggCommitter) { runningTask .getExecutionContext() .sendToMember( new BarrierFlowOperation(barrier, committerTaskLocation), committerTaskAddress) .join(); } } runningTask.ack(barrier); log.debug( "trigger barrier [{}] finished, cost {}ms. taskLocation [{}]", barrier.getId(), System.currentTimeMillis() - startTime, taskLocation); } else if (record.getData() instanceof SchemaChangeEvent) { if (prepareClose) { return; } SchemaChangeEvent event = (SchemaChangeEvent) record.getData(); writer.applySchemaChange(event); } else { if (prepareClose) { return; } writer.write((T) record.getData()); sinkWriteCount.inc(); sinkWriteQPS.markEvent(); if (record.getData() instanceof SeaTunnelRow) { long size = ((SeaTunnelRow) record.getData()).getBytesSize(); sinkWriteBytes.inc(size); sinkWriteBytesPerSeconds.markEvent(size); String tableId = ((SeaTunnelRow) record.getData()).getTableId(); if (StringUtils.isNotBlank(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sinkTableCounter = sinkWriteCountPerTable.get(tableName); if (Objects.nonNull(sinkTableCounter)) { sinkTableCounter.inc(); } else { Counter counter = metricsContext.counter(SINK_WRITE_COUNT + "#" + tableName); counter.inc(); sinkWriteCountPerTable.put(tableName, counter); } } } } } catch (Exception e) { throw new RuntimeException(e); } } Aufgabenausführung Im wird über die -Methode ein physischer Plan generiert und anschließend die -Methode aufgerufen, um die Aufgabe tatsächlich zu starten. CoordinatorService init run CoordinatorService { jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); ... jobMaster.run(); } JobMaster { public void run() { ... physicalPlan.startJob(); ... } } In wird beim Starten der Aufgabe die Methode von aufgerufen. JobMaster startJob PhysicalPlan public void startJob() { isRunning = true; log.info("{} state process is start", getJobFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process is stopped", jobFullName)); return; } switch (getJobStatus()) { case CREATED: updateJobState(JobStatus.SCHEDULED); break; case SCHEDULED: getPipelineList() .forEach( subPlan -> { if (PipelineStatus.CREATED.equals( subPlan.getCurrPipelineStatus())) { subPlan.startSubPlanStateProcess(); } }); updateJobState(JobStatus.RUNNING); break; case RUNNING: case DOING_SAVEPOINT: break; case FAILING: case CANCELING: jobMaster.neverNeedRestore(); getPipelineList().forEach(SubPlan::cancelPipeline); break; case FAILED: case CANCELED: case SAVEPOINT_DONE: case FINISHED: stopJobStateProcess(); jobEndFuture.complete(new JobResult(getJobStatus(), errorBySubPlan.get())); return; default: throw new IllegalArgumentException("Unknown Job State: " + getJobStatus()); } } In wird beim Starten einer Aufgabe der Status der Aufgabe auf aktualisiert und anschließend die Startmethode von aufgerufen. PhysicalPlan SCHEDULED SubPlan public void startSubPlanStateProcess() { isRunning = true; log.info("{} state process is start", getPipelineFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process not start", pipelineFullName)); return; } PipelineStatus state = getCurrPipelineStatus(); switch (state) { case CREATED: updatePipelineState(PipelineStatus.SCHEDULED); break; case SCHEDULED: try { ResourceUtils.applyResourceForPipeline(jobMaster.getResourceManager(), this); log.debug( "slotProfiles: {}, PipelineLocation: {}", slotProfiles, this.getPipelineLocation()); updatePipelineState(PipelineStatus.DEPLOYING); } catch (Exception e) { makePipelineFailing(e); } break; case DEPLOYING: coordinatorVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); physicalVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); updatePipelineState(PipelineStatus.RUNNING); break; case RUNNING: break; case FAILING: case CANCELING: coordinatorVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); physicalVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); break; case FAILED: case CANCELED: if (checkNeedRestore(state) && prepareRestorePipeline()) { jobMaster.releasePipelineResource(this); restorePipeline(); return; } subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState(pipelineId, state, errorByPhysicalVertex.get())); return; case FINISHED: subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState( pipelineId, getPipelineState(), errorByPhysicalVertex.get())); return; default: throw new IllegalArgumentException("Unknown Pipeline State: " + getPipelineState()); } } In einem werden Ressourcen für alle Aufgaben angewendet. Die Ressourcenanwendung erfolgt über den . Während der Ressourcenanwendung werden Knoten basierend auf benutzerdefinierten Tags ausgewählt, um sicherzustellen, dass Aufgaben auf bestimmten Knoten ausgeführt werden, wodurch eine Ressourcenisolierung erreicht wird. SubPlan ResourceManager public static void applyResourceForPipeline( @NonNull ResourceManager resourceManager, @NonNull SubPlan subPlan) { Map<TaskGroupLocation, CompletableFuture<SlotProfile>> futures = new HashMap<>(); Map<TaskGroupLocation, SlotProfile> slotProfiles = new HashMap<>(); // TODO If there is no enough resources for tasks, we need add some wait profile subPlan.getCoordinatorVertexList() .forEach( coordinator -> futures.put( coordinator.getTaskGroupLocation(), applyResourceForTask( resourceManager, coordinator, subPlan.getTags()))); subPlan.getPhysicalVertexList() .forEach( task -> futures.put( task.getTaskGroupLocation(), applyResourceForTask( resourceManager, task, subPlan.getTags()))); futures.forEach( (key, value) -> { try { slotProfiles.put(key, value == null ? null : value.join()); } catch (CompletionException e) { // do nothing } }); // set it first, avoid can't get it when get resource not enough exception and need release // applied resource subPlan.getJobMaster().setOwnedSlotProfiles(subPlan.getPipelineLocation(), slotProfiles); if (futures.size() != slotProfiles.size()) { throw new NoEnoughResourceException(); } } public static CompletableFuture<SlotProfile> applyResourceForTask( ResourceManager resourceManager, PhysicalVertex task, Map<String, String> tags) { // TODO custom resource size return resourceManager.applyResource( task.getTaskGroupLocation().getJobId(), new ResourceProfile(), tags); } public CompletableFuture<List<SlotProfile>> applyResources( long jobId, List<ResourceProfile> resourceProfile, Map<String, String> tagFilter) throws NoEnoughResourceException { waitingWorkerRegister(); ConcurrentMap<Address, WorkerProfile> matchedWorker = filterWorkerByTag(tagFilter); if (matchedWorker.isEmpty()) { log.error("No matched worker with tag filter {}.", tagFilter); throw new NoEnoughResourceException(); } return new ResourceRequestHandler(jobId, resourceProfile, matchedWorker, this) .request(tagFilter); } Wenn alle verfügbaren Knoten abgerufen wurden, werden die Knoten neu gemischt und ein Knoten mit mehr Ressourcen als den erforderlichen Ressourcen wird nach dem Zufallsprinzip ausgewählt. Der Knoten wird dann kontaktiert und eine wird an ihn gesendet. RequestSlotOperation public Optional<WorkerProfile> preCheckWorkerResource(ResourceProfile r) { // Shuffle the order to ensure random selection of workers List<WorkerProfile> workerProfiles = Arrays.asList(registerWorker.values().toArray(new WorkerProfile[0])); Collections.shuffle(workerProfiles); // Check if there are still unassigned slots Optional<WorkerProfile> workerProfile = workerProfiles.stream() .filter( worker -> Arrays.stream(worker.getUnassignedSlots()) .anyMatch( slot -> slot.getResourceProfile() .enoughThan(r))) .findAny(); if (!workerProfile.isPresent()) { // Check if there are still unassigned resources workerProfile = workerProfiles.stream() .filter(WorkerProfile::isDynamicSlot) .filter(worker -> worker.getUnassignedResource().enoughThan(r)) .findAny(); } return workerProfile; } private CompletableFuture<SlotAndWorkerProfile> singleResourceRequestToMember( int i, ResourceProfile r, WorkerProfile workerProfile) { CompletableFuture<SlotAndWorkerProfile> future = resourceManager.sendToMember( new RequestSlotOperation(jobId, r), workerProfile.getAddress()); return future.whenComplete( withTryCatch( LOGGER, (slotAndWorkerProfile, error) -> { if (error != null) { throw new RuntimeException(error); } else { resourceManager.heartbeat(slotAndWorkerProfile.getWorkerProfile()); addSlotToCacheMap(i, slotAndWorkerProfile.getSlotProfile()); } })); } Wenn der des Knotens die Anforderung empfängt, aktualisiert er seine eigenen Informationen und gibt sie an den Masterknoten zurück. Wenn die Ressourcenanforderung nicht das erwartete Ergebnis liefert, wird eine ausgelöst, die einen Taskfehler anzeigt. Wenn die Ressourcenzuweisung erfolgreich ist, beginnt die Taskbereitstellung mit , das den Task zur Ausführung an den -Knoten sendet. SlotService requestSlot NoEnoughResourceException task.makeTaskGroupDeploy() worker TaskDeployState deployState = deploy(jobMaster.getOwnedSlotProfiles(taskGroupLocation)); public TaskDeployState deploy(@NonNull SlotProfile slotProfile) { try { if (slotProfile.getWorker().equals(nodeEngine.getThisAddress())) { return deployOnLocal(slotProfile); } else { return deployOnRemote(slotProfile); } } catch (Throwable th) { return TaskDeployState.failed(th); } } private TaskDeployState deployOnRemote(@Non Null SlotProfile slotProfile) { return deployInternal( taskGroupImmutableInformation -> { try { return (TaskDeployState) NodeEngineUtil.sendOperationToMemberNode( nodeEngine, new DeployTaskOperation( slotProfile, nodeEngine .getSerializationService() .toData( taskGroupImmutableInformation)), slotProfile.getWorker()) .get(); } catch (Exception e) { if (getExecutionState().isEndState()) { log.warn(ExceptionUtils.getMessage(e)); log.warn( String.format( "%s deploy error, but the state is already in end state %s, skip this error", getTaskFullName(), currExecutionState)); return TaskDeployState.success(); } else { return TaskDeployState.failed(e); } } }); } Aufgabenverteilung Beim Bereitstellen einer Aufgabe werden die Aufgabeninformationen an den Knoten gesendet, der während der Ressourcenzuweisung abgerufen wurde: public TaskDeployState deployTask(@NonNull Data taskImmutableInformation) { TaskGroupImmutableInformation taskImmutableInfo = nodeEngine.getSerializationService().toObject(taskImmutableInformation); return deployTask(taskImmutableInfo); } public TaskDeployState deployTask(@NonNull TaskGroupImmutableInformation taskImmutableInfo) { logger.info( String.format( "received deploying task executionId [%s]", taskImmutableInfo.getExecutionId())); TaskGroup taskGroup = null; try { Set<ConnectorJarIdentifier> connectorJarIdentifiers = taskImmutableInfo.getConnectorJarIdentifiers(); Set<URL> jars = new HashSet<>(); ClassLoader classLoader; if (!CollectionUtils.isEmpty(connectorJarIdentifiers)) { // Prioritize obtaining the jar package file required for the current task execution // from the local, if it does not exist locally, it will be downloaded from the // master node. jars = serverConnectorPackageClient.getConnectorJarFromLocal( connectorJarIdentifiers); } else if (!CollectionUtils.isEmpty(taskImmutableInfo.getJars())) { jars = taskImmutableInfo.getJars(); } classLoader = classLoaderService.getClassLoader( taskImmutableInfo.getJobId(), Lists.newArrayList(jars)); if (jars.isEmpty()) { taskGroup = nodeEngine.getSerializationService().toObject(taskImmutableInfo.getGroup()); } else { taskGroup = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, taskImmutableInfo.getGroup()); } logger.info( String.format( "deploying task %s, executionId [%s]", taskGroup.getTaskGroupLocation(), taskImmutableInfo.getExecutionId())); synchronized (this) { if (executionContexts.containsKey(taskGroup.getTaskGroupLocation())) { throw new RuntimeException( String.format( "TaskGroupLocation: %s already exists", taskGroup.getTaskGroupLocation())); } deployLocalTask(taskGroup, classLoader, jars); return TaskDeployState.success(); } } catch (Throwable t) { logger.severe( String.format( "TaskGroupID : %s deploy error with Exception: %s", taskGroup != null && taskGroup.getTaskGroupLocation() != null ? taskGroup.getTaskGroupLocation().toString() : "taskGroupLocation is null", ExceptionUtils.getMessage(t))); return TaskDeployState.failed(t); } } Wenn ein Arbeitsknoten die Aufgabe empfängt, ruft er die Methode von auf, um die Aufgabe an den beim Start erstellten Thread-Pool zu übermitteln. deployTask TaskExecutionService Wenn die Aufgabe an den Thread-Pool übermittelt wird: private final class BlockingWorker implements Runnable { private final TaskTracker tracker; private final CountDownLatch startedLatch; private BlockingWorker(TaskTracker tracker, CountDownLatch startedLatch) { this.tracker = tracker; this.startedLatch = startedLatch; } @Override public void run() { TaskExecutionService.TaskGroupExecutionTracker taskGroupExecutionTracker = tracker.taskGroupExecutionTracker; ClassLoader classLoader = executionContexts .get(taskGroupExecutionTracker.taskGroup.getTaskGroupLocation()) .getClassLoader(); ClassLoader oldClassLoader = Thread.currentThread().getContextClassLoader(); Thread.currentThread().setContextClassLoader(classLoader); final Task t = tracker.task; ProgressState result = null; try { startedLatch.countDown(); t.init(); do { result = t.call(); } while (!result.isDone() && isRunning && !taskGroupExecutionTracker.executionCompletedExceptionally()); ... } } Die Methode wird aufgerufen und somit werden Datensynchronisierungsaufgaben tatsächlich ausgeführt. Task.call Klassenlader In SeaTunnel wurde der Standard-ClassLoader geändert, um Unterklassen zu priorisieren und so Konflikte mit anderen Komponentenklassen zu vermeiden: @Override public synchronized ClassLoader getClassLoader(long jobId, Collection<URL> jars) { log.debug("Get classloader for job {} with jars {}", jobId, jars); if (cacheMode) { // with cache mode, all jobs share the same classloader if the jars are the same jobId = 1L; } if (!classLoaderCache.containsKey(jobId)) { classLoaderCache.put(jobId, new ConcurrentHashMap<>()); classLoaderReferenceCount.put(jobId, new ConcurrentHashMap<>()); } Map<String, ClassLoader> classLoaderMap = classLoaderCache.get(jobId); String key = covertJarsToKey(jars); if (classLoaderMap.containsKey(key)) { classLoaderReferenceCount.get(jobId).get(key).incrementAndGet(); return classLoaderMap.get(key); } else { ClassLoader classLoader = new SeaTunnelChildFirstClassLoader(jars); log.info("Create classloader for job {} with jars {}", jobId, jars); classLoaderMap.put(key, classLoader); classLoaderReferenceCount.get(jobId).put(key, new AtomicInteger(1)); return classLoader; } } REST-API-Aufgabenübermittlung SeaTunnel unterstützt auch die Aufgabenübermittlung über REST API. Um diese Funktion zu aktivieren, fügen Sie der Datei die folgende Konfiguration hinzu: hazelcast.yaml network: rest-api: enabled: true endpoint-groups: CLUSTER_WRITE: enabled: true DATA: enabled: true Nach dem Hinzufügen dieser Konfiguration kann der Hazelcast-Knoten HTTP-Anfragen empfangen. Bei Verwendung der REST-API zur Aufgabenübermittlung wird der Client zum Knoten, der die HTTP-Anforderung sendet, und der Server ist der SeaTunnel-Cluster. Wenn der Server die Anforderung empfängt, ruft er basierend auf der Anforderungs-URI die entsprechende Methode auf: public void handle(HttpPostCommand httpPostCommand) { String uri = httpPostCommand.getURI(); try { if (uri.startsWith(SUBMIT_JOB_URL)) { handleSubmitJob(httpPostCommand, uri); } else if (uri.startsWith(STOP_JOB_URL)) { handleStopJob(httpPostCommand, uri); } else if (uri.startsWith(ENCRYPT_CONFIG)) { handleEncrypt(httpPostCommand); } else { original.handle(httpPostCommand); } } catch (IllegalArgumentException e) { prepareResponse(SC_400, httpPostCommand, exceptionResponse(e)); } catch (Throwable e) { logger.warning("An error occurred while handling request " + httpPostCommand, e); prepareResponse(SC_500, httpPostCommand, exceptionResponse(e)); } this.textCommandService.sendResponse(httpPostCommand); } Die Methode zur Bearbeitung der Auftragsübermittlungsanforderung wird durch den Pfad bestimmt: private void handleSubmitJob(HttpPostCommand httpPostCommand, String uri) throws IllegalArgumentException { Map<String, String> requestParams = new HashMap<>(); RestUtil.buildRequestParams(requestParams, uri); Config config = RestUtil.buildConfig(requestHandle(httpPostCommand), false); ReadonlyConfig envOptions = ReadonlyConfig.fromConfig(config.getConfig("env")); String jobName = envOptions.get(EnvCommonOptions.JOB_NAME); JobConfig jobConfig = new JobConfig(); jobConfig.setName( StringUtils.isEmpty(requestParams.get(RestConstant.JOB_NAME)) ? jobName : requestParams.get(RestConstant.JOB_NAME)); boolean startWithSavePoint = Boolean.parseBoolean(requestParams.get(RestConstant.IS_START_WITH_SAVE_POINT)); String jobIdStr = requestParams.get(RestConstant.JOB_ID); Long finalJobId = StringUtils.isNotBlank(jobIdStr) ? Long.parseLong(jobIdStr) : null; SeaTunnelServer seaTunnelServer = getSeaTunnelServer(); RestJobExecutionEnvironment restJobExecutionEnvironment = new RestJobExecutionEnvironment( seaTunnelServer, jobConfig, config, textCommandService.getNode(), startWithSavePoint, finalJobId); JobImmutableInformation jobImmutableInformation = restJobExecutionEnvironment.build(); long jobId = jobImmutableInformation.getJobId(); if (!seaTunnelServer.isMasterNode()) { NodeEngineUtil.sendOperationToMasterNode( getNode().nodeEngine, new SubmitJobOperation( jobId, getNode().nodeEngine.toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint())) .join(); } else { submitJob(seaTunnelServer, jobImmutableInformation, jobConfig); } this.prepareResponse( httpPostCommand, new JsonObject() .add(RestConstant.JOB_ID, String.valueOf(jobId)) .add(RestConstant.JOB_NAME, jobConfig.getName())); } Die Logik hier ist ähnlich wie auf der Clientseite. Da es keinen lokalen Modus gibt, muss kein lokaler Dienst erstellt werden. Auf der Clientseite wird die Klasse zum Parsen logischer Pläne verwendet. In ähnlicher Weise führt die Klasse dieselben Aufgaben aus. ClientJobExecutionEnvironment RestJobExecutionEnvironment Wenn beim Senden einer Aufgabe der aktuelle Knoten nicht der Masterknoten ist, werden Informationen an den Masterknoten gesendet. Der Masterknoten behandelt die Aufgabenübermittlung ähnlich wie Befehle vom Befehlszeilen-Client. Wenn der aktuelle Knoten der Masterknoten ist, ruft er direkt die Methode auf, die wiederum die Methode zur nachfolgenden Verarbeitung aufruft: submitJob coordinatorService.submitJob private void submitJob( SeaTunnelServer seaTunnelServer, JobImmutableInformation jobImmutableInformation, JobConfig jobConfig) { CoordinatorService coordinatorService = seaTunnelServer.getCoordinatorService(); Data data = textCommandService .getNode() .nodeEngine .getSerializationService() .toData(jobImmutableInformation); PassiveCompletableFuture<Void> voidPassiveCompletableFuture = coordinatorService.submitJob( Long.parseLong(jobConfig.getJobContext().getJobId()), data, jobImmutableInformation.isStartWithSavePoint()); voidPassiveCompletableFuture.join(); } Bei beiden Übermittlungsmethoden wird der logische Plan auf der Übermittlungsseite analysiert und die Informationen dann an den Masterknoten gesendet. Der Masterknoten führt dann die Analyse des physischen Plans, die Zuweisung und andere Vorgänge durch.