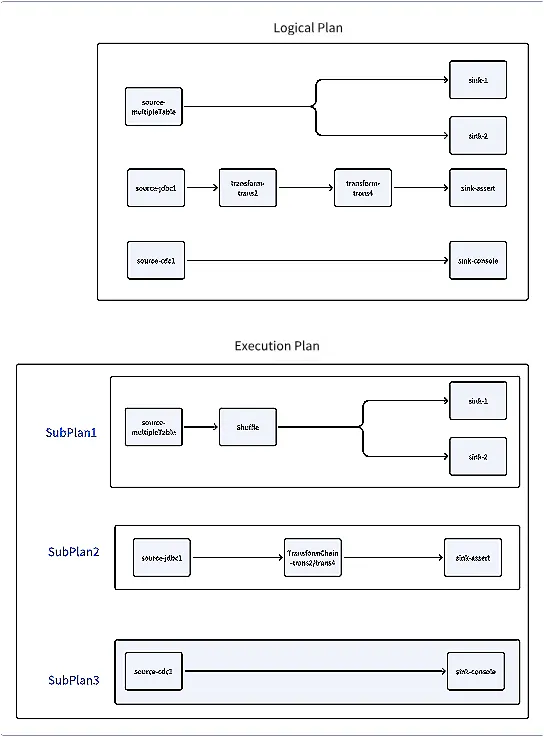
Este es el último artículo de la serie que analiza el código fuente del motor Apache SeaTunnel Zeta; revise la serie anterior para obtener una visión completa: Análisis del código fuente del motor Apache SeaTunnel Zeta (parte 1): inicialización del servidor Análisis del código fuente del motor Apache SeaTunnel Zeta (parte 2): proceso de envío de tareas en el lado del cliente Repasemos los componentes que se ejecutan después de que se inicia el servidor: : habilitado solo en nodos maestros/en espera, escucha el estado del clúster y maneja conmutaciones por error de maestros a en espera. CoordinatorService : habilitado en los nodos de trabajo, informa periódicamente su estado al maestro. SlotService : habilitado en los nodos de trabajo, actualiza periódicamente las métricas de tareas en IMAP. TaskExecutionService Cuando el clúster no recibe ninguna tarea, estos componentes se ejecutan. Sin embargo, cuando un cliente envía un mensaje al servidor, ¿cómo lo gestiona el servidor? SeaTunnelSubmitJobCodec Recepción de mensajes Dado que el cliente y el servidor se encuentran en máquinas diferentes, no se pueden utilizar llamadas a métodos; en su lugar, se emplea el paso de mensajes. Al recibir un mensaje, ¿cómo lo procesa el servidor? En primer lugar, el cliente envía un mensaje de tipo : SeaTunnelSubmitJobCodec // Client code ClientMessage request = SeaTunnelSubmitJobCodec.encodeRequest( jobImmutableInformation.getJobId(), seaTunnelHazelcastClient .getSerializationService() .toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint()); PassiveCompletableFuture<Void> submitJobFuture = seaTunnelHazelcastClient.requestOnMasterAndGetCompletableFuture(request); En la clase , está asociada con una clase , que asigna tipos de mensajes a clases . Para , se asigna a la clase : SeaTunnelSubmitJobCodec SeaTunnelMessageTaskFactoryProvider MessageTask SeaTunnelSubmitJobCodec SubmitJobTask private final Int2ObjectHashMap<MessageTaskFactory> factories = new Int2ObjectHashMap<>(60); private void initFactories() { factories.put( SeaTunnelPrintMessageCodec.REQUEST_MESSAGE_TYPE, (clientMessage, connection) -> new PrintMessageTask(clientMessage, node, connection)); factories.put( SeaTunnelSubmitJobCodec.REQUEST_MESSAGE_TYPE, (clientMessage, connection) -> new SubmitJobTask(clientMessage, node, connection)); ..... } Al examinar la clase , invoca la clase : SubmitJobTask SubmitJobOperation @Override protected Operation prepareOperation() { return new SubmitJobOperation( parameters.jobId, parameters.jobImmutableInformation, parameters.isStartWithSavePoint); } En la clase , la información de la tarea se entrega al componente a través de su método : SubmitJobOperation CoordinatorService submitJob @Override protected PassiveCompletableFuture<?> doRun() throws Exception { SeaTunnelServer seaTunnelServer = getService(); return seaTunnelServer .getCoordinatorService() .submitJob(jobId, jobImmutableInformation, isStartWithSavePoint); } En este punto, un mensaje del cliente se entrega efectivamente al servidor para la invocación del método. Otros tipos de operaciones se pueden rastrear de manera similar. Servicio de coordinación A continuación, exploremos cómo maneja los envíos de trabajos: CoordinatorService public PassiveCompletableFuture<Void> submitJob( long jobId, Data jobImmutableInformation, boolean isStartWithSavePoint) { CompletableFuture<Void> jobSubmitFuture = new CompletableFuture<>(); // First, check if a job with the same ID already exists if (getJobMaster(jobId) != null) { logger.warning( String.format( "The job %s is currently running; no need to submit again.", jobId)); jobSubmitFuture.complete(null); return new PassiveCompletableFuture<>(jobSubmitFuture); } // Initialize JobMaster object JobMaster jobMaster = new JobMaster( jobImmutableInformation, this.nodeEngine, executorService, getResourceManager(), getJobHistoryService(), runningJobStateIMap, runningJobStateTimestampsIMap, ownedSlotProfilesIMap, runningJobInfoIMap, metricsImap, engineConfig, seaTunnelServer); executorService.submit( () -> { try { // Ensure no duplicate tasks with the same ID if (!isStartWithSavePoint && getJobHistoryService().getJobMetrics(jobId) != null) { throw new JobException( String.format( "The job id %s has already been submitted and is not starting with a savepoint.", jobId)); } // Add task info to IMAP runningJobInfoIMap.put( jobId, new JobInfo(System.currentTimeMillis(), jobImmutableInformation)); runningJobMasterMap.put(jobId, jobMaster); // Initialize JobMaster jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); // Task creation successful jobSubmitFuture.complete(null); } catch (Throwable e) { String errorMsg = ExceptionUtils.getMessage(e); logger.severe(String.format("submit job %s error %s ", jobId, errorMsg)); jobSubmitFuture.completeExceptionally(new JobException(errorMsg)); } if (!jobSubmitFuture.isCompletedExceptionally()) { // Start job execution try { jobMaster.run(); } finally { // Remove jobMaster from map if not cancelled if (!jobMaster.getJobMasterCompleteFuture().isCancelled()) { runningJobMasterMap.remove(jobId); } } } else { runningJobInfoIMap.remove(jobId); runningJobMasterMap.remove(jobId); } }); return new PassiveCompletableFuture<>(jobSubmitFuture); } En el servidor, se crea un objeto para administrar la tarea individual. Durante la creación , recupera el administrador de recursos a través de y la información del historial de trabajos a través de . El se inicializa al inicio, mientras que se carga de forma diferida tras el primer envío de tarea: JobMaster JobMaster getResourceManager() getJobHistoryService() jobHistoryService ResourceManager /** Lazy load for resource manager */ public ResourceManager getResourceManager() { if (resourceManager == null) { synchronized (this) { if (resourceManager == null) { ResourceManager manager = new ResourceManagerFactory(nodeEngine, engineConfig) .getResourceManager(); manager.init(); resourceManager = manager; } } } return resourceManager; } Administrador de recursos Actualmente, SeaTunnel solo admite la implementación independiente. Al inicializar , reúne todos los nodos del clúster y envía una para obtener información de los nodos y actualizar el estado interno : ResourceManager SyncWorkerProfileOperation registerWorker @Override public void init() { log.info("Init ResourceManager"); initWorker(); } private void initWorker() { log.info("initWorker... "); List<Address> aliveNode = nodeEngine.getClusterService().getMembers().stream() .map(Member::getAddress) .collect(Collectors.toList()); log.info("init live nodes: {}", aliveNode); List<CompletableFuture<Void>> futures = aliveNode.stream() .map( node -> sendToMember(new SyncWorkerProfileOperation(), node) .thenAccept( p -> { if (p != null) { registerWorker.put( node, (WorkerProfile) p); log.info( "received new worker register: " + ((WorkerProfile) p) .getAddress()); } })) .collect(Collectors.toList()); futures.forEach(CompletableFuture::join); log.info("registerWorker: {}", registerWorker); } Anteriormente, observamos que envía mensajes de latidos al maestro desde cada nodo periódicamente. Al recibir estos latidos, actualiza los estados de los nodos en su estado interno. SlotService ResourceManager @Override public void heartbeat(WorkerProfile workerProfile) { if (!registerWorker.containsKey(workerProfile.getAddress())) { log.info("received new worker register: " + workerProfile.getAddress()); sendToMember(new ResetResourceOperation(), workerProfile.getAddress()).join(); } else { log.debug("received worker heartbeat from: " + workerProfile.getAddress()); } registerWorker.put(workerProfile.getAddress(), workerProfile); } Maestro de trabajos En , se crea una instancia y se llama a su método . Cuando se completa el método , se considera que la creación de la tarea es exitosa. Luego, se llama al método para ejecutar formalmente la tarea. CoordinatorService JobMaster init init run Veamos la inicialización y el método . init public JobMaster( @NonNull Data jobImmutableInformationData, @NonNull NodeEngine nodeEngine, @NonNull ExecutorService executorService, @NonNull ResourceManager resourceManager, @NonNull JobHistoryService jobHistoryService, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull IMap ownedSlotProfilesIMap, @NonNull IMap<Long, JobInfo> runningJobInfoIMap, @NonNull IMap<Long, HashMap<TaskLocation, SeaTunnelMetricsContext>> metricsImap, EngineConfig engineConfig, SeaTunnelServer seaTunnelServer) { this.jobImmutableInformationData = jobImmutableInformationData; this.nodeEngine = nodeEngine; this.executorService = executorService; flakeIdGenerator = this.nodeEngine .getHazelcastInstance() .getFlakeIdGenerator(Constant.SEATUNNEL_ID_GENERATOR_NAME); this.ownedSlotProfilesIMap = ownedSlotProfilesIMap; this.resourceManager = resourceManager; this.jobHistoryService = jobHistoryService; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.runningJobInfoIMap = runningJobInfoIMap; this.engineConfig = engineConfig; this.metricsImap = metricsImap; this.seaTunnelServer = seaTunnelServer; this.releasedSlotWhenTaskGroupFinished = new ConcurrentHashMap<>(); } Durante la inicialización, solo se realizan asignaciones de variables simples sin operaciones significativas. Debemos centrarnos en el método . init public synchronized void init(long initializationTimestamp, boolean restart) throws Exception { // The server receives a binary object from the client, // which is first converted to a JobImmutableInformation object, the same object sent by the client jobImmutableInformation = nodeEngine.getSerializationService().toObject(jobImmutableInformationData); // Get the checkpoint configuration, such as the interval, timeout, etc. jobCheckpointConfig = createJobCheckpointConfig( engineConfig.getCheckpointConfig(), jobImmutableInformation.getJobConfig()); LOGGER.info( String.format( "Init JobMaster for Job %s (%s) ", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId())); LOGGER.info( String.format( "Job %s (%s) needed jar urls %s", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls())); ClassLoader appClassLoader = Thread.currentThread().getContextClassLoader(); // Get the ClassLoader ClassLoader classLoader = seaTunnelServer .getClassLoaderService() .getClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); // Deserialize the logical DAG from the client-provided information logicalDag = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, jobImmutableInformation.getLogicalDag()); try { Thread.currentThread().setContextClassLoader(classLoader); // Execute save mode functionality, such as table creation and deletion if (!restart && !logicalDag.isStartWithSavePoint() && ReadonlyConfig.fromMap(logicalDag.getJobConfig().getEnvOptions()) .get(EnvCommonOptions.SAVEMODE_EXECUTE_LOCATION) .equals(SaveModeExecuteLocation.CLUSTER)) { logicalDag.getLogicalVertexMap().values().stream() .map(LogicalVertex::getAction) .filter(action -> action instanceof SinkAction) .map(sink -> ((SinkAction<?, ?, ?, ?>) sink).getSink()) .forEach(JobMaster::handleSaveMode); } // Parse the logical plan into a physical plan final Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> planTuple = PlanUtils.fromLogicalDAG( logicalDag, nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, engineConfig.getQueueType(), engineConfig); this.physicalPlan = planTuple.f0(); this.physicalPlan.setJobMaster(this); this.checkpointPlanMap = planTuple.f1(); } finally { // Reset the current thread's ClassLoader and release the created classLoader Thread.currentThread().setContextClassLoader(appClassLoader); seaTunnelServer .getClassLoaderService() .releaseClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); } Exception initException = null; try { // Initialize the checkpoint manager this.initCheckPointManager(restart); } catch (Exception e) { initException = e; } // Add some callback functions for job state listening this.initStateFuture(); if (initException != null) { if (restart) { cancelJob(); } throw initException; } } Por último, veamos el método : run public void run() { try { physicalPlan.startJob(); } catch (Throwable e) { LOGGER.severe( String.format( "Job %s (%s) run error with: %s", physicalPlan.getJobImmutableInformation().getJobConfig().getName(), physicalPlan.getJobImmutableInformation().getJobId(), ExceptionUtils.getMessage(e))); } finally { jobMasterCompleteFuture.join(); if (engineConfig.getConnectorJarStorageConfig().getEnable()) { List<ConnectorJarIdentifier> pluginJarIdentifiers = jobImmutableInformation.getPluginJarIdentifiers(); seaTunnelServer .getConnectorPackageService() .cleanUpWhenJobFinished( jobImmutableInformation.getJobId(), pluginJarIdentifiers); } } } Este método es relativamente sencillo y llama para ejecutar el plan físico generado. physicalPlan.startJob() Del código anterior, es evidente que después de que el servidor recibe una solicitud de envío de tarea del cliente, inicializa la clase , que genera el plan físico a partir del plan lógico y luego ejecuta el plan físico. JobMaster A continuación, debemos profundizar en cómo el plan lógico se convierte en un plan físico. Conversión del plano lógico al plano físico La generación del plano físico se realiza llamando al siguiente método en : JobMaster final Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> planTuple = PlanUtils.fromLogicalDAG( logicalDag, nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, engineConfig.getQueueType(), engineConfig); En el método para generar el plan físico, el plan lógico primero se convierte en un plan de ejecución y luego el plan de ejecución se convierte en un plan físico. public static Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> fromLogicalDAG( @NonNull LogicalDag logicalDag, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType, @NonNull EngineConfig engineConfig) { return new PhysicalPlanGenerator( new ExecutionPlanGenerator( logicalDag, jobImmutableInformation, engineConfig) .generate(), nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, queueType) .generate(); } Generación del Plan de Ejecución public ExecutionPlanGenerator( @NonNull LogicalDag logicalPlan, @NonNull JobImmutableInformation jobImmutableInformation, @NonNull EngineConfig engineConfig) { checkArgument( logicalPlan.getEdges().size() > 0, "ExecutionPlan Builder must have LogicalPlan."); this.logicalPlan = logicalPlan; this.jobImmutableInformation = jobImmutableInformation; this.engineConfig = engineConfig; } public ExecutionPlan generate() { log.debug("Generate execution plan using logical plan:"); Set<ExecutionEdge> executionEdges = generateExecutionEdges(logicalPlan.getEdges()); log.debug("Phase 1: generate execution edge list {}", executionEdges); executionEdges = generateShuffleEdges(executionEdges); log.debug("Phase 2: generate shuffle edge list {}", executionEdges); executionEdges = generateTransformChainEdges(executionEdges); log.debug("Phase 3: generate transform chain edge list {}", executionEdges); List<Pipeline> pipelines = generatePipelines(executionEdges); log.debug("Phase 4: generate pipeline list {}", pipelines); ExecutionPlan executionPlan = new ExecutionPlan(pipelines, jobImmutableInformation); log.debug("Phase 5 : generate execution plan {}", executionPlan); return executionPlan; } La clase toma un plan lógico y produce un plan de ejecución a través de una serie de pasos, incluyendo la generación de bordes de ejecución, bordes de mezcla, bordes de cadena de transformación y, finalmente, canalizaciones. ExecutionPlanGenerator Generación del Plan Físico La clase convierte el plan de ejecución en un plan físico: PhysicalPlanGenerator public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.executionPlan = executionPlan; this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public PhysicalPlan generate() { List<PhysicalVertex> physicalVertices = generatePhysicalVertices(executionPlan); List<PhysicalEdge> physicalEdges = generatePhysicalEdges(executionPlan); PhysicalPlan physicalPlan = new PhysicalPlan(physicalVertices, physicalEdges); log.debug("Generate physical plan: {}", physicalPlan); return physicalPlan; } Examinemos el contenido de estas dos clases. public class ExecutionPlan { private final List<Pipeline> pipelines; private final JobImmutableInformation jobImmutableInformation; } public class Pipeline { /** The ID of the pipeline. */ private final Integer id; private final List<ExecutionEdge> edges; private final Map<Long, ExecutionVertex> vertexes; } public class ExecutionEdge { private ExecutionVertex leftVertex; private ExecutionVertex rightVertex; } public class ExecutionVertex { private Long vertexId; private Action action; private int parallelism; } Comparémoslo con el plan lógico: public class LogicalDag implements IdentifiedDataSerializable { @Getter private JobConfig jobConfig; private final Set<LogicalEdge> edges = new LinkedHashSet<>(); private final Map<Long, LogicalVertex> logicalVertexMap = new LinkedHashMap<>(); private IdGenerator idGenerator; private boolean isStartWithSavePoint = false; } public class LogicalEdge implements IdentifiedDataSerializable { private LogicalVertex inputVertex; private LogicalVertex targetVertex; private Long inputVertexId; private Long targetVertexId; } public class LogicalVertex implements IdentifiedDataSerializable { private Long vertexId; private Action action; private int parallelism; } Parece que cada pipeline se parece a un plan lógico. ¿Por qué necesitamos este paso de transformación? Veamos con más detalle el proceso de generación de un plan lógico. Como se muestra arriba, generar un plan de ejecución implica cinco pasos, que revisaremos uno por uno. Paso 1: Convertir el plan lógico en un plan de ejecución // Input is a set of logical plan edges, where each edge stores upstream and downstream nodes private Set<ExecutionEdge> generateExecutionEdges(Set<LogicalEdge> logicalEdges) { Set<ExecutionEdge> executionEdges = new LinkedHashSet<>(); Map<Long, ExecutionVertex> logicalVertexIdToExecutionVertexMap = new HashMap(); // Sort in order: first by input node, then by output node List<LogicalEdge> sortedLogicalEdges = new ArrayList<>(logicalEdges); Collections.sort( sortedLogicalEdges, (o1, o2) -> { if (o1.getInputVertexId() != o2.getInputVertexId()) { return o1.getInputVertexId() > o2.getInputVertexId() ? 1 : -1; } if (o1.getTargetVertexId() != o2.getTargetVertexId()) { return o1.getTargetVertexId() > o2.getTargetVertexId() ? 1 : -1; } return 0; }); // Loop to convert each logical plan edge to an execution plan edge for (LogicalEdge logicalEdge : sortedLogicalEdges) { LogicalVertex logicalInputVertex = logicalEdge.getInputVertex(); ExecutionVertex executionInputVertex = logicalVertexIdToExecutionVertexMap.computeIfAbsent( logicalInputVertex.getVertexId(), vertexId -> { long newId = idGenerator.getNextId(); // Recreate Action for each logical plan node Action newLogicalInputAction = recreateAction( logicalInputVertex.getAction(), newId, logicalInputVertex.getParallelism()); // Convert to execution plan node return new ExecutionVertex( newId, newLogicalInputAction, logicalInputVertex.getParallelism()); }); // Similarly, recreate execution plan nodes for target nodes LogicalVertex logicalTargetVertex = logicalEdge.getTargetVertex(); ExecutionVertex executionTargetVertex = logicalVertexIdToExecutionVertexMap.computeIfAbsent( logicalTargetVertex.getVertexId(), vertexId -> { long newId = idGenerator.getNextId(); Action newLogicalTargetAction = recreateAction( logicalTargetVertex.getAction(), newId, logicalTargetVertex.getParallelism()); return new ExecutionVertex( newId, newLogicalTargetAction, logicalTargetVertex.getParallelism()); }); // Generate execution plan edge ExecutionEdge executionEdge = new ExecutionEdge(executionInputVertex, executionTargetVertex); executionEdges.add(executionEdge); } return executionEdges; } Paso 2 private Set<ExecutionEdge> generateShuffleEdges(Set<ExecutionEdge> executionEdges) { // Map of upstream node ID to list of downstream nodes Map<Long, List<ExecutionVertex>> targetVerticesMap = new LinkedHashMap<>(); // Store only nodes of type Source Set<ExecutionVertex> sourceExecutionVertices = new HashSet<>(); executionEdges.forEach( edge -> { ExecutionVertex leftVertex = edge.getLeftVertex(); ExecutionVertex rightVertex = edge.getRightVertex(); if (leftVertex.getAction() instanceof SourceAction) { sourceExecutionVertices.add(leftVertex); } targetVerticesMap .computeIfAbsent(leftVertex.getVertexId(), id -> new ArrayList<>()) .add(rightVertex); }); if (sourceExecutionVertices.size() != 1) { return executionEdges; } ExecutionVertex sourceExecutionVertex = sourceExecutionVertices.stream().findFirst().get(); Action sourceAction = sourceExecutionVertex.getAction(); List<CatalogTable> producedCatalogTables = new ArrayList<>(); if (sourceAction instanceof SourceAction) { try { producedCatalogTables = ((SourceAction<?, ?, ?>) sourceAction) .getSource() .getProducedCatalogTables(); } catch (UnsupportedOperationException e) { } } else if (sourceAction instanceof TransformChainAction) { return executionEdges; } else { throw new SeaTunnelException( "source action must be SourceAction or TransformChainAction"); } // If the source produces a single table or // the source has only one downstream output, return directly if (producedCatalogTables.size() <= 1 || targetVerticesMap.get(sourceExecutionVertex.getVertexId()).size() <= 1) { return executionEdges; } List<ExecutionVertex> sinkVertices = targetVerticesMap.get(sourceExecutionVertex.getVertexId()); // Check if there are other types of actions, currently downstream nodes should ideally have two types: Transform and Sink; here we check if only Sink type is present Optional<ExecutionVertex> hasOtherAction = sinkVertices.stream() .filter(vertex -> !(vertex.getAction() instanceof SinkAction)) .findFirst(); checkArgument(!hasOtherAction.isPresent()); // After executing the above code, the current scenario is: // There is only one data source, this source produces multiple tables, and multiple sink nodes depend on these tables // This means the task has only two types of nodes: a source node that produces multiple tables and a group of sink nodes depending on this source // A new shuffle node will be created and added between the source and sinks // Modify the dependency relationship to source -> shuffle -> multiple sinks Set<ExecutionEdge> newExecutionEdges = new LinkedHashSet<>(); // Shuffle strategy will not be explored in detail here ShuffleStrategy shuffleStrategy = ShuffleMultipleRowStrategy.builder() .jobId(jobImmutableInformation.getJobId()) .inputPartitions(sourceAction.getParallelism()) .catalogTables(producedCatalogTables) .queueEmptyQueueTtl( (int) (engineConfig.getCheckpointConfig().getCheckpointInterval() * 3)) .build(); ShuffleConfig shuffleConfig = ShuffleConfig.builder().shuffleStrategy(shuffleStrategy).build(); long shuffleVertexId = idGenerator.getNextId(); String shuffleActionName = String.format("Shuffle [%s]", sourceAction.getName()); ShuffleAction shuffleAction = new ShuffleAction(shuffleVertexId, shuffleActionName, shuffleConfig); shuffleAction.setParallelism(sourceAction.getParallelism()); ExecutionVertex shuffleVertex = new ExecutionVertex(shuffleVertexId, shuffleAction, shuffleAction.getParallelism()); ExecutionEdge sourceToShuffleEdge = new ExecutionEdge(sourceExecutionVertex, shuffleVertex); newExecutionEdges.add(sourceToShuffleEdge); // Set the parallelism of multiple sink nodes to 1 for (ExecutionVertex sinkVertex : sinkVertices) { sinkVertex.setParallelism(1); sinkVertex.getAction().setParallelism(1); ExecutionEdge shuffleToSinkEdge = new ExecutionEdge(shuffleVertex, sinkVertex); newExecutionEdges.add(shuffleToSinkEdge); } return newExecutionEdges; } El paso Shuffle aborda situaciones específicas en las que la fuente admite la lectura de varias tablas y hay varios nodos receptores que dependen de esta fuente. En tales casos, se agrega un nodo Shuffle entre ellos. Paso 3 private Set<ExecutionEdge> generateTransformChainEdges(Set<ExecutionEdge> executionEdges) { // Uses three structures: stores all Source nodes and the input/output nodes for each // inputVerticesMap stores all upstream input nodes by downstream node id as the key // targetVerticesMap stores all downstream output nodes by upstream node id as the key Map<Long, List<ExecutionVertex>> inputVerticesMap = new HashMap<>(); Map<Long, List<ExecutionVertex>> targetVerticesMap = new HashMap<>(); Set<ExecutionVertex> sourceExecutionVertices = new HashSet<>(); executionEdges.forEach( edge -> { ExecutionVertex leftVertex = edge.getLeftVertex(); ExecutionVertex rightVertex = edge.getRightVertex(); if (leftVertex.getAction() instanceof SourceAction) { sourceExecutionVertices.add(leftVertex); } inputVerticesMap .computeIfAbsent(rightVertex.getVertexId(), id -> new ArrayList<>()) .add(leftVertex); targetVerticesMap .computeIfAbsent(leftVertex.getVertexId(), id -> new ArrayList<>()) .add(rightVertex); }); Map<Long, ExecutionVertex> transformChainVertexMap = new HashMap<>(); Map<Long, Long> chainedTransformVerticesMapping = new HashMap<>(); // Loop over each source, starting with all head nodes in the DAG for (ExecutionVertex sourceVertex : sourceExecutionVertices) { List<ExecutionVertex> vertices = new ArrayList<>(); vertices.add(sourceVertex); for (int index = 0; index < vertices.size(); index++) { ExecutionVertex vertex = vertices.get(index); fillChainedTransformExecutionVertex( vertex, chainedTransformVerticesMapping, transformChainVertexMap, executionEdges, Collections.unmodifiableMap(inputVerticesMap), Collections.unmodifiableMap(targetVerticesMap)); // If the current node has downstream nodes, add all downstream nodes to the list // The second loop will recalculate the newly added downstream nodes, which could be Transform nodes or Sink nodes if (targetVerticesMap.containsKey(vertex.getVertexId())) { vertices.addAll(targetVerticesMap.get(vertex.getVertexId())); } } } // After looping, chained Transform nodes will be chained, and the chainable edges will be removed from the execution plan // Therefore, the logical plan at this point cannot form the graph relationship and needs to be rebuilt Set<ExecutionEdge> transformChainEdges = new LinkedHashSet<>(); // Loop over existing relationships for (ExecutionEdge executionEdge : executionEdges) { ExecutionVertex leftVertex = executionEdge.getLeftVertex(); ExecutionVertex rightVertex = executionEdge.getRightVertex(); boolean needRebuild = false; // Check if the input or output nodes of the current edge are in the chain mapping // If so, the node has been chained, and we need to find the chained node in the mapping // and rebuild the DAG if (chainedTransformVerticesMapping.containsKey(leftVertex.getVertexId())) { needRebuild = true; leftVertex = transformChainVertexMap.get( chainedTransformVerticesMapping.get(leftVertex.getVertexId())); } if (chainedTransformVerticesMapping.containsKey(rightVertex.getVertexId())) { needRebuild = true; rightVertex = transformChainVertexMap.get( chainedTransformVerticesMapping.get(rightVertex.getVertexId())); } if (needRebuild) { executionEdge = new ExecutionEdge(leftVertex, rightVertex); } transformChainEdges.add(executionEdge); } return transformChainEdges; } private void fillChainedTransformExecutionVertex( ExecutionVertex currentVertex, Map<Long, Long> chainedTransformVerticesMapping, Map<Long, ExecutionVertex> transformChainVertexMap, Set<ExecutionEdge> executionEdges, Map<Long, List<ExecutionVertex>> inputVerticesMap, Map<Long, List<ExecutionVertex>> targetVerticesMap) { // Exit if the map already contains the current node if (chainedTransformVerticesMapping.containsKey(currentVertex.getVertexId())) { return; } List<ExecutionVertex> transformChainedVertices = new ArrayList<>(); collectChainedVertices( currentVertex, transformChainedVertices, executionEdges, inputVerticesMap, targetVerticesMap); // If the list is not empty, it means the Transform nodes in the list can be merged into one if (transformChainedVertices.size() > 0) { long newVertexId = idGenerator.getNextId(); List<SeaTunnelTransform> transforms = new ArrayList<>(transformChainedVertices.size()); List<String> names = new ArrayList<>(transformChainedVertices.size()); Set<URL> jars = new HashSet<>(); Set<ConnectorJarIdentifier> identifiers = new HashSet<>(); transformChainedVertices.stream() .peek( // Add all historical node IDs and new node IDs to the mapping vertex -> chainedTransformVerticesMapping.put( vertex.getVertexId(), newVertexId)) .map(ExecutionVertex::getAction) .map(action -> (TransformAction) action) .forEach( action -> { transforms.add(action.getTransform()); jars.addAll(action.getJarUrls()); identifiers.addAll(action.getConnectorJarIdentifiers()); names.add(action.getName()); }); String transformChainActionName = String.format("TransformChain[%s]", String.join("->", names)); // Merge multiple TransformActions into one TransformChainAction TransformChainAction transformChainAction = new TransformChainAction( newVertexId, transformChainActionName, jars, identifiers, transforms); transformChainAction.setParallelism(currentVertex.getAction().getParallelism()); ExecutionVertex executionVertex = new ExecutionVertex( newVertexId, transformChainAction, currentVertex.getParallelism()); // Store the modified node information in the state transformChainVertexMap.put(newVertexId, executionVertex); chainedTransformVerticesMapping.put( currentVertex.getVertexId(), executionVertex.getVertexId()); } } private void collectChainedVertices( ExecutionVertex currentVertex, List<ExecutionVertex> chainedVertices, Set<ExecutionEdge> executionEdges, Map<Long, List<ExecutionVertex>> inputVerticesMap, Map<Long, List<ExecutionVertex>> targetVerticesMap) { Action action = currentVertex.getAction(); // Only merge TransformAction if (action instanceof TransformAction) { if (chainedVertices.size() == 0) { // If the list of vertices to be merged is empty, add itself to the list // The condition for entering this branch is that the current node is a TransformAction and the list to be merged is empty // There may be several scenarios: the first Transform node enters, and this Transform node has no constraints chainedVertices.add(currentVertex); } else if (inputVerticesMap.get(currentVertex.getVertexId()).size() == 1) { // When this condition is entered, it means: // The list of vertices to be merged already has at least one TransformAction // The scenario at this point is that the upstream Transform node has only one downstream node, ie, the current node. This constraint is ensured by the following judgment // Chain the current TransformAction node with the previous TransformAction node // Delete this relationship from the execution plan executionEdges.remove( new ExecutionEdge( chainedVertices.get(chainedVertices.size() - 1), currentVertex)); // Add itself to the list of nodes to be merged chainedVertices.add(currentVertex); } else { return; } } else { return; } // It cannot chain to any target vertex if it has multiple target vertices. if (targetVerticesMap.get(currentVertex.getVertexId()).size() == 1) { // If the current node has only one downstream node, try chaining again // If the current node has multiple downstream nodes, it will not chain the downstream nodes, so it can be ensured that the above chaining is a one-to-one relationship // This call occurs when the Transform node has only one downstream node collectChainedVertices( targetVerticesMap.get(currentVertex.getVertexId()).get(0), chainedVertices, executionEdges, inputVerticesMap, targetVerticesMap); } } Paso 4 private List<Pipeline> generatePipelines(Set<ExecutionEdge> executionEdges) { // Stores each execution plan node Set<ExecutionVertex> executionVertices = new LinkedHashSet<>(); for (ExecutionEdge edge : executionEdges) { executionVertices.add(edge.getLeftVertex()); executionVertices.add(edge.getRightVertex()); } // Calls the Pipeline generator to convert the execution plan into Pipelines PipelineGenerator pipelineGenerator = new PipelineGenerator(executionVertices, new ArrayList<>(executionEdges)); List<Pipeline> pipelines = pipelineGenerator.generatePipelines(); Set<String> duplicatedActionNames = new HashSet<>(); Set<String> actionNames = new HashSet<>(); for (Pipeline pipeline : pipelines) { Integer pipelineId = pipeline.getId(); for (ExecutionVertex vertex : pipeline.getVertexes().values()) { // Get each execution node of the current Pipeline, reset the Action name, and add the pipeline name Action action = vertex.getAction(); String actionName = String.format("pipeline-%s [%s]", pipelineId, action.getName()); action.setName(actionName); if (actionNames.contains(actionName)) { duplicatedActionNames.add(actionName); } actionNames.add(action Name); } } if (duplicatedActionNames.size() > 0) { throw new RuntimeException( String.format( "Duplicated Action names found: %s", duplicatedActionNames)); } return pipelines; } public PipelineGenerator(Collection<ExecutionVertex> vertices, List<ExecutionEdge> edges) { this.vertices = vertices; this.edges = edges; } public List<Pipeline> generatePipelines() { List<ExecutionEdge> executionEdges = expandEdgeByParallelism(edges); // Split the execution plan into unrelated execution plans based on their relationships // Divide into several unrelated execution plans List<List<ExecutionEdge>> edgesList = splitUnrelatedEdges(executionEdges); edgesList = edgesList.stream() .flatMap(e -> this.splitUnionEdge(e).stream()) .collect(Collectors.toList()); // Just convert execution plan to pipeline at now. We should split it to multi pipeline with // cache in the future IdGenerator idGenerator = new IdGenerator(); // Convert execution plan graph to Pipeline return edgesList.stream() .map( e -> { Map<Long, ExecutionVertex> vertexes = new HashMap<>(); List<ExecutionEdge> pipelineEdges = e.stream() .map( edge -> { if (!vertexes.containsKey( edge.getLeftVertexId())) { vertexes.put( edge.getLeftVertexId(), edge.getLeftVertex()); } ExecutionVertex source = vertexes.get( edge.getLeftVertexId()); if (!vertexes.containsKey( edge.getRightVertexId())) { vertexes.put( edge.getRightVertexId(), edge.getRightVertex()); } ExecutionVertex destination = vertexes.get( edge.getRightVertexId()); return new ExecutionEdge( source, destination); }) .collect(Collectors.toList()); return new Pipeline( (int) idGenerator.getNextId(), pipelineEdges, vertexes); }) .collect(Collectors.toList()); } Paso 5 El quinto paso implica generar las instancias del plan de ejecución, pasando los parámetros de Pipeline generados en el cuarto paso. Resumen: El plan de ejecución realiza las siguientes tareas en el plan lógico: Cuando una fuente genera varias tablas y varios nodos receptores dependen de esta fuente, se agrega un nodo de mezcla entre ellos. Intente encadenar nodos de transformación de fusión, combinando múltiples nodos de transformación en un solo nodo. Dividir las tareas, dividiendo un en varias tareas no relacionadas representadas como . configuration file/LogicalDag List<Pipeline> Generación de Plano Físico Antes de profundizar en la generación del plano físico, repasemos primero qué información se incluye en el plano físico generado y examinemos sus componentes internos. public class PhysicalPlan { private final List<SubPlan> pipelineList; private final AtomicInteger finishedPipelineNum = new AtomicInteger(0); private final AtomicInteger canceledPipelineNum = new AtomicInteger(0); private final AtomicInteger failedPipelineNum = new AtomicInteger(0); private final JobImmutableInformation jobImmutableInformation; private final IMap<Object, Object> runningJobStateIMap; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private CompletableFuture<JobResult> jobEndFuture; private final AtomicReference<String> errorBySubPlan = new AtomicReference<>(); private final String jobFullName; private final long jobId; private JobMaster jobMaster; private boolean makeJobEndWhenPipelineEnded = true; private volatile boolean isRunning = false; } En esta clase, un campo clave es , que es una lista de instancias : pipelineList SubPlan public class SubPlan { private final int pipelineMaxRestoreNum; private final int pipelineRestoreIntervalSeconds; private final List<PhysicalVertex> physicalVertexList; private final List<PhysicalVertex> coordinatorVertexList; private final int pipelineId; private final AtomicInteger finishedTaskNum = new AtomicInteger(0); private final AtomicInteger canceledTaskNum = new AtomicInteger(0); private final AtomicInteger failedTaskNum = new AtomicInteger(0); private final String pipelineFullName; private final IMap<Object, Object> runningJobStateIMap; private final Map<String, String> tags; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private CompletableFuture<PipelineExecutionState> pipelineFuture; private final PipelineLocation pipelineLocation; private AtomicReference<String> errorByPhysicalVertex = new AtomicReference<>(); private final ExecutorService executorService; private JobMaster jobMaster; private PassiveCompletableFuture<Void> reSchedulerPipelineFuture; private Integer pipelineRestoreNum; private final Object restoreLock = new Object(); private volatile PipelineStatus currPipelineStatus; public volatile boolean isRunning = false; private Map<TaskGroupLocation, SlotProfile> slotProfiles; } La clase mantiene una lista de instancias , divididas en nodos de plan físico y nodos de coordinación: SubPlan PhysicalVertex public class PhysicalVertex { private final TaskGroupLocation taskGroupLocation; private final String taskFullName; private final TaskGroupDefaultImpl taskGroup; private final ExecutorService executorService; private final FlakeIdGenerator flakeIdGenerator; private final Set<URL> pluginJarsUrls; private final Set<ConnectorJarIdentifier> connectorJarIdentifiers; private final IMap<Object, Object> runningJobStateIMap; private CompletableFuture<TaskExecutionState> taskFuture; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private final NodeEngine nodeEngine; private JobMaster jobMaster; private volatile ExecutionState currExecutionState = ExecutionState.CREATED; public volatile boolean isRunning = false; private AtomicReference<String> errorByPhysicalVertex = new AtomicReference<>(); } public class TaskGroupDefaultImpl implements TaskGroup { private final TaskGroupLocation taskGroupLocation; private final String taskGroupName; // Stores the tasks that the physical node needs to execute // Each task could be for reading data, writing data, data splitting, checkpoint tasks, etc. private final Map<Long, Task> tasks; } es responsable de convertir el plan de ejecución en y agregar varias tareas de coordinación como división de datos, confirmación de datos y tareas de punto de control durante la ejecución. PhysicalPlanGenerator SeaTunnelTask public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.pipelines = executionPlan.getPipelines(); this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; // the checkpoint of a pipeline this.pipelineTasks = new HashSet<>(); this.startingTasks = new HashSet<>(); this.subtaskActions = new HashMap<>(); this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> generate() { // Get the node filter conditions from user configuration to select the nodes where tasks will run Map<String, String> tagFilter = (Map<String, String>) jobImmutableInformation .getJobConfig() .getEnvOptions() .get(EnvCommonOptions.NODE_TAG_FILTER.key()); // TODO Determine which tasks do not need to be restored according to state CopyOnWriteArrayList<PassiveCompletableFuture<PipelineStatus>> waitForCompleteBySubPlanList = new CopyOnWriteArrayList<>(); Map<Integer, CheckpointPlan> checkpointPlans = new HashMap<>(); final int totalPipelineNum = pipelines.size(); Stream<SubPlan> subPlanStream = pipelines.stream() .map( pipeline -> { // Clear the state each time this.pipelineTasks.clear(); this.startingTasks.clear(); this.subtaskActions.clear(); final int pipelineId = pipeline.getId(); // Get current task information final List<ExecutionEdge> edges = pipeline.getEdges(); // Get all SourceActions List<SourceAction<?, ?, ?>> sources = findSourceAction(edges); // Generate Source data slice tasks, ie, SourceSplitEnumeratorTask // This task calls the SourceSplitEnumerator class in the connector if supported List<PhysicalVertex> coordinatorVertexList = getEnumeratorTask( sources, pipelineId, totalPipelineNum); // Generate Sink commit tasks, ie, SinkAggregatedCommitterTask // This task calls the SinkAggregatedCommitter class in the connector if supported // These two tasks are executed as coordination tasks coordinatorVertexList.addAll( getCommitterTask(edges, pipelineId, totalPipelineNum)); List<PhysicalVertex> physicalVertexList = getSourceTask( edges, sources, pipelineId, totalPipelineNum); // physicalVertexList.addAll( getShuffleTask(edges, pipelineId, totalPipelineNum)); CompletableFuture<PipelineStatus> pipelineFuture = new CompletableFuture<>(); waitForCompleteBySubPlanList.add( new PassiveCompletableFuture<>(pipelineFuture)); // Add checkpoint tasks checkpointPlans.put( pipelineId, CheckpointPlan.builder() .pipelineId(pipelineId) .pipelineSubtasks(pipelineTasks) .startingSubtasks(startingTasks) .pipelineActions(pipeline.getActions()) .subtaskActions(subtaskActions) .build()); return new SubPlan( pipelineId, totalPipelineNum, initializationTimestamp, physicalVertexList, coordinatorVertexList, jobImmutableInformation, executorService, runningJobStateIMap, runningJobStateTimestampsIMap, tagFilter); }); PhysicalPlan physicalPlan = new PhysicalPlan( subPlanStream.collect(Collectors.toList()), executorService, jobImmutableInformation, initializationTimestamp, runningJobStateIMap, runningJobStateTimestampsIMap); return Tuple2.tuple2(physicalPlan, checkpointPlans); } El proceso de generación del plan físico implica convertir el plan de ejecución en y agregar varias tareas de coordinación, como tareas de división de datos, tareas de confirmación de datos y tareas de punto de control. SeaTunnelTask En , las tareas se convierten en , , , , . SeaTunnelTask SourceFlowLifeCycle SinkFlowLifeCycle TransformFlowLifeCycle ShuffleSinkFlowLifeCycle ShuffleSourceFlowLifeCycle Por ejemplo, las clases y son las siguientes: SourceFlowLifeCycle SinkFlowLifeCycle Ciclo de vida del flujo de origen @Override public void init() throws Exception { this.splitSerializer = sourceAction.getSource().getSplitSerializer(); this.reader = sourceAction .getSource() .createReader( new SourceReaderContext( indexID, sourceAction.getSource().getBoundedness(), this, metricsContext, eventListener)); this.enumeratorTaskAddress = getEnumeratorTaskAddress(); } @Override public void open() throws Exception { reader.open(); register(); } public void collect() throws Exception { if (!prepareClose) { if (schemaChanging()) { log.debug("schema is changing, stop reader collect records"); Thread.sleep(200); return; } reader.pollNext(collector); if (collector.isEmptyThisPollNext()) { Thread.sleep(100); } else { collector.resetEmptyThisPollNext(); /** * The current thread obtain a checkpoint lock in the method {@link * SourceReader#pollNext( Collector)}. When trigger the checkpoint or savepoint, * other threads try to obtain the lock in the method {@link * SourceFlowLifeCycle#triggerBarrier(Barrier)}. When high CPU load, checkpoint * process may be blocked as long time. So we need sleep to free the CPU. */ Thread.sleep(0L); } if (collector.captureSchemaChangeBeforeCheckpointSignal()) { if (schemaChangePhase.get() != null) { throw new IllegalStateException( "previous schema changes in progress, schemaChangePhase: " + schemaChangePhase.get()); } schemaChangePhase.set(SchemaChangePhase.createBeforePhase()); runningTask.triggerSchemaChangeBeforeCheckpoint().get(); log.info("triggered schema-change-before checkpoint, stopping collect data"); } else if (collector.captureSchemaChangeAfterCheckpointSignal()) { if (schemaChangePhase.get() != null) { throw new IllegalStateException( "previous schema changes in progress, schemaChangePhase: " + schemaChangePhase.get()); } schemaChangePhase.set(SchemaChangePhase.createAfterPhase()); runningTask.triggerSchemaChangeAfterCheckpoint().get(); log.info("triggered schema-change-after checkpoint, stopping collect data"); } } else { Thread.sleep(100); } } En , la lectura de datos se realiza en el método . Una vez que se leen los datos, se colocan en . Cuando se reciben los datos, el recopilador actualiza las métricas y envía los datos a los componentes posteriores. SourceFlowLifeCycle collect SeaTunnelSourceCollector @Override public void collect(T row) { try { if (row instanceof SeaTunnelRow) { String tableId = ((SeaTunnelRow) row).getTableId(); int size; if (rowType instanceof SeaTunnelRowType) { size = ((SeaTunnelRow) row).getBytesSize((SeaTunnelRowType) rowType); } else if (rowType instanceof MultipleRowType) { size = ((SeaTunnelRow) row).getBytesSize(rowTypeMap.get(tableId)); } else { throw new SeaTunnelEngineException( "Unsupported row type: " + rowType.getClass().getName()); } sourceReceivedBytes.inc(size); sourceReceivedBytesPerSeconds.markEvent(size); flowControlGate.audit((SeaTunnelRow) row); if (StringUtils.isNotEmpty(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sourceTableCounter = sourceReceivedCountPerTable.get(tableName); if (Objects.nonNull(sourceTableCounter)) { sourceTableCounter.inc(); } else { Counter counter = metricsContext.counter(SOURCE_RECEIVED_COUNT + "#" + tableName); counter.inc(); sourceReceivedCountPerTable.put(tableName, counter); } } } sendRecordToNext(new Record<>(row)); emptyThisPollNext = false; sourceReceivedCount.inc(); sourceReceivedQPS.markEvent(); } catch (IOException e) { throw new RuntimeException(e); } } public void sendRecordToNext(Record<?> record) throws IOException { synchronized (checkpointLock) { for (OneInputFlowLifeCycle<Record<?>> output : outputs) { output.received(record); } } } Ciclo de vida del flujo del sumidero @Override public void received(Record<?> record) { try { if (record.getData() instanceof Barrier) { long startTime = System.currentTimeMillis(); Barrier barrier = (Barrier) record.getData(); if (barrier.prepareClose(this.taskLocation)) { prepareClose = true; } if (barrier.snapshot()) { try { lastCommitInfo = writer.prepareCommit(); } catch (Exception e) { writer.abortPrepare(); throw e; } List<StateT> states = writer.snapshotState(barrier.getId()); if (!writerStateSerializer.isPresent()) { runningTask.addState( barrier, ActionStateKey.of(sinkAction), Collections.emptyList()); } else { runningTask.addState( barrier, ActionStateKey.of(sinkAction), serializeStates(writerStateSerializer.get(), states)); } if (containAggCommitter) { CommitInfoT commitInfoT = null; if (lastCommitInfo.isPresent()) { commitInfoT = lastCommitInfo.get(); } runningTask .getExecutionContext() .sendToMember( new SinkPrepareCommitOperation<CommitInfoT>( barrier, committerTaskLocation, commitInfoSerializer.isPresent() ? commitInfoSerializer .get() .serialize(commitInfoT) : null), committerTaskAddress) .join(); } } else { if (containAggCommitter) { runningTask .getExecutionContext() .sendToMember( new BarrierFlowOperation(barrier, committerTaskLocation), committerTaskAddress) .join(); } } runningTask.ack(barrier); log.debug( "trigger barrier [{}] finished, cost {}ms. taskLocation [{}]", barrier.getId(), System.currentTimeMillis() - startTime, taskLocation); } else if (record.getData() instanceof SchemaChangeEvent) { if (prepareClose) { return; } SchemaChangeEvent event = (SchemaChangeEvent) record.getData(); writer.applySchemaChange(event); } else { if (prepareClose) { return; } writer.write((T) record.getData()); sinkWriteCount.inc(); sinkWriteQPS.markEvent(); if (record.getData() instanceof SeaTunnelRow) { long size = ((SeaTunnelRow) record.getData()).getBytesSize(); sinkWriteBytes.inc(size); sinkWriteBytesPerSeconds.markEvent(size); String tableId = ((SeaTunnelRow) record.getData()).getTableId(); if (StringUtils.isNotBlank(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sinkTableCounter = sinkWriteCountPerTable.get(tableName); if (Objects.nonNull(sinkTableCounter)) { sinkTableCounter.inc(); } else { Counter counter = metricsContext.counter(SINK_WRITE_COUNT + "#" + tableName); counter.inc(); sinkWriteCountPerTable.put(tableName, counter); } } } } } catch (Exception e) { throw new RuntimeException(e); } } Ejecución de tareas En , se genera un plan físico a través del método y luego se llama al método para iniciar realmente la tarea. CoordinatorService init run CoordinatorService { jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); ... jobMaster.run(); } JobMaster { public void run() { ... physicalPlan.startJob(); ... } } En , al iniciar la tarea, se llama al método de . JobMaster startJob PhysicalPlan public void startJob() { isRunning = true; log.info("{} state process is start", getJobFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process is stopped", jobFullName)); return; } switch (getJobStatus()) { case CREATED: updateJobState(JobStatus.SCHEDULED); break; case SCHEDULED: getPipelineList() .forEach( subPlan -> { if (PipelineStatus.CREATED.equals( subPlan.getCurrPipelineStatus())) { subPlan.startSubPlanStateProcess(); } }); updateJobState(JobStatus.RUNNING); break; case RUNNING: case DOING_SAVEPOINT: break; case FAILING: case CANCELING: jobMaster.neverNeedRestore(); getPipelineList().forEach(SubPlan::cancelPipeline); break; case FAILED: case CANCELED: case SAVEPOINT_DONE: case FINISHED: stopJobStateProcess(); jobEndFuture.complete(new JobResult(getJobStatus(), errorBySubPlan.get())); return; default: throw new IllegalArgumentException("Unknown Job State: " + getJobStatus()); } } En , al iniciar una tarea se actualiza el estado de la tarea a y luego continúa llamando al método de inicio de . PhysicalPlan SCHEDULED SubPlan public void startSubPlanStateProcess() { isRunning = true; log.info("{} state process is start", getPipelineFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process not start", pipelineFullName)); return; } PipelineStatus state = getCurrPipelineStatus(); switch (state) { case CREATED: updatePipelineState(PipelineStatus.SCHEDULED); break; case SCHEDULED: try { ResourceUtils.applyResourceForPipeline(jobMaster.getResourceManager(), this); log.debug( "slotProfiles: {}, PipelineLocation: {}", slotProfiles, this.getPipelineLocation()); updatePipelineState(PipelineStatus.DEPLOYING); } catch (Exception e) { makePipelineFailing(e); } break; case DEPLOYING: coordinatorVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); physicalVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); updatePipelineState(PipelineStatus.RUNNING); break; case RUNNING: break; case FAILING: case CANCELING: coordinatorVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); physicalVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); break; case FAILED: case CANCELED: if (checkNeedRestore(state) && prepareRestorePipeline()) { jobMaster.releasePipelineResource(this); restorePipeline(); return; } subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState(pipelineId, state, errorByPhysicalVertex.get())); return; case FINISHED: subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState( pipelineId, getPipelineState(), errorByPhysicalVertex.get())); return; default: throw new IllegalArgumentException("Unknown Pipeline State: " + getPipelineState()); } } En un , los recursos se aplican a todas las tareas. La aplicación de recursos se realiza a través de . Durante la aplicación de recursos, los nodos se seleccionan en función de las etiquetas definidas por el usuario para garantizar que las tareas se ejecuten en nodos específicos, logrando así el aislamiento de los recursos. SubPlan ResourceManager public static void applyResourceForPipeline( @NonNull ResourceManager resourceManager, @NonNull SubPlan subPlan) { Map<TaskGroupLocation, CompletableFuture<SlotProfile>> futures = new HashMap<>(); Map<TaskGroupLocation, SlotProfile> slotProfiles = new HashMap<>(); // TODO If there is no enough resources for tasks, we need add some wait profile subPlan.getCoordinatorVertexList() .forEach( coordinator -> futures.put( coordinator.getTaskGroupLocation(), applyResourceForTask( resourceManager, coordinator, subPlan.getTags()))); subPlan.getPhysicalVertexList() .forEach( task -> futures.put( task.getTaskGroupLocation(), applyResourceForTask( resourceManager, task, subPlan.getTags()))); futures.forEach( (key, value) -> { try { slotProfiles.put(key, value == null ? null : value.join()); } catch (CompletionException e) { // do nothing } }); // set it first, avoid can't get it when get resource not enough exception and need release // applied resource subPlan.getJobMaster().setOwnedSlotProfiles(subPlan.getPipelineLocation(), slotProfiles); if (futures.size() != slotProfiles.size()) { throw new NoEnoughResourceException(); } } public static CompletableFuture<SlotProfile> applyResourceForTask( ResourceManager resourceManager, PhysicalVertex task, Map<String, String> tags) { // TODO custom resource size return resourceManager.applyResource( task.getTaskGroupLocation().getJobId(), new ResourceProfile(), tags); } public CompletableFuture<List<SlotProfile>> applyResources( long jobId, List<ResourceProfile> resourceProfile, Map<String, String> tagFilter) throws NoEnoughResourceException { waitingWorkerRegister(); ConcurrentMap<Address, WorkerProfile> matchedWorker = filterWorkerByTag(tagFilter); if (matchedWorker.isEmpty()) { log.error("No matched worker with tag filter {}.", tagFilter); throw new NoEnoughResourceException(); } return new ResourceRequestHandler(jobId, resourceProfile, matchedWorker, this) .request(tagFilter); } Cuando se obtienen todos los nodos disponibles, se barajan y se selecciona aleatoriamente un nodo con recursos mayores que los requeridos. Luego se contacta al nodo y se le envía una . RequestSlotOperation public Optional<WorkerProfile> preCheckWorkerResource(ResourceProfile r) { // Shuffle the order to ensure random selection of workers List<WorkerProfile> workerProfiles = Arrays.asList(registerWorker.values().toArray(new WorkerProfile[0])); Collections.shuffle(workerProfiles); // Check if there are still unassigned slots Optional<WorkerProfile> workerProfile = workerProfiles.stream() .filter( worker -> Arrays.stream(worker.getUnassignedSlots()) .anyMatch( slot -> slot.getResourceProfile() .enoughThan(r))) .findAny(); if (!workerProfile.isPresent()) { // Check if there are still unassigned resources workerProfile = workerProfiles.stream() .filter(WorkerProfile::isDynamicSlot) .filter(worker -> worker.getUnassignedResource().enoughThan(r)) .findAny(); } return workerProfile; } private CompletableFuture<SlotAndWorkerProfile> singleResourceRequestToMember( int i, ResourceProfile r, WorkerProfile workerProfile) { CompletableFuture<SlotAndWorkerProfile> future = resourceManager.sendToMember( new RequestSlotOperation(jobId, r), workerProfile.getAddress()); return future.whenComplete( withTryCatch( LOGGER, (slotAndWorkerProfile, error) -> { if (error != null) { throw new RuntimeException(error); } else { resourceManager.heartbeat(slotAndWorkerProfile.getWorkerProfile()); addSlotToCacheMap(i, slotAndWorkerProfile.getSlotProfile()); } })); } Cuando el del nodo recibe la solicitud , actualiza su propia información y la devuelve al nodo maestro. Si la solicitud de recursos no cumple con el resultado esperado, se genera una excepción , que indica que la tarea falló. Cuando la asignación de recursos se realiza correctamente, la implementación de la tarea comienza con , que envía la tarea al nodo para su ejecución. SlotService requestSlot NoEnoughResourceException task.makeTaskGroupDeploy() worker TaskDeployState deployState = deploy(jobMaster.getOwnedSlotProfiles(taskGroupLocation)); public TaskDeployState deploy(@NonNull SlotProfile slotProfile) { try { if (slotProfile.getWorker().equals(nodeEngine.getThisAddress())) { return deployOnLocal(slotProfile); } else { return deployOnRemote(slotProfile); } } catch (Throwable th) { return TaskDeployState.failed(th); } } private TaskDeployState deployOnRemote(@Non Null SlotProfile slotProfile) { return deployInternal( taskGroupImmutableInformation -> { try { return (TaskDeployState) NodeEngineUtil.sendOperationToMemberNode( nodeEngine, new DeployTaskOperation( slotProfile, nodeEngine .getSerializationService() .toData( taskGroupImmutableInformation)), slotProfile.getWorker()) .get(); } catch (Exception e) { if (getExecutionState().isEndState()) { log.warn(ExceptionUtils.getMessage(e)); log.warn( String.format( "%s deploy error, but the state is already in end state %s, skip this error", getTaskFullName(), currExecutionState)); return TaskDeployState.success(); } else { return TaskDeployState.failed(e); } } }); } Despliegue de tareas Al implementar una tarea, la información de la tarea se envía al nodo obtenida durante la asignación de recursos: public TaskDeployState deployTask(@NonNull Data taskImmutableInformation) { TaskGroupImmutableInformation taskImmutableInfo = nodeEngine.getSerializationService().toObject(taskImmutableInformation); return deployTask(taskImmutableInfo); } public TaskDeployState deployTask(@NonNull TaskGroupImmutableInformation taskImmutableInfo) { logger.info( String.format( "received deploying task executionId [%s]", taskImmutableInfo.getExecutionId())); TaskGroup taskGroup = null; try { Set<ConnectorJarIdentifier> connectorJarIdentifiers = taskImmutableInfo.getConnectorJarIdentifiers(); Set<URL> jars = new HashSet<>(); ClassLoader classLoader; if (!CollectionUtils.isEmpty(connectorJarIdentifiers)) { // Prioritize obtaining the jar package file required for the current task execution // from the local, if it does not exist locally, it will be downloaded from the // master node. jars = serverConnectorPackageClient.getConnectorJarFromLocal( connectorJarIdentifiers); } else if (!CollectionUtils.isEmpty(taskImmutableInfo.getJars())) { jars = taskImmutableInfo.getJars(); } classLoader = classLoaderService.getClassLoader( taskImmutableInfo.getJobId(), Lists.newArrayList(jars)); if (jars.isEmpty()) { taskGroup = nodeEngine.getSerializationService().toObject(taskImmutableInfo.getGroup()); } else { taskGroup = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, taskImmutableInfo.getGroup()); } logger.info( String.format( "deploying task %s, executionId [%s]", taskGroup.getTaskGroupLocation(), taskImmutableInfo.getExecutionId())); synchronized (this) { if (executionContexts.containsKey(taskGroup.getTaskGroupLocation())) { throw new RuntimeException( String.format( "TaskGroupLocation: %s already exists", taskGroup.getTaskGroupLocation())); } deployLocalTask(taskGroup, classLoader, jars); return TaskDeployState.success(); } } catch (Throwable t) { logger.severe( String.format( "TaskGroupID : %s deploy error with Exception: %s", taskGroup != null && taskGroup.getTaskGroupLocation() != null ? taskGroup.getTaskGroupLocation().toString() : "taskGroupLocation is null", ExceptionUtils.getMessage(t))); return TaskDeployState.failed(t); } } Cuando un nodo de trabajo recibe la tarea, llama al método de para enviar la tarea al grupo de subprocesos creado al inicio. deployTask TaskExecutionService Cuando la tarea se envía al grupo de subprocesos: private final class BlockingWorker implements Runnable { private final TaskTracker tracker; private final CountDownLatch startedLatch; private BlockingWorker(TaskTracker tracker, CountDownLatch startedLatch) { this.tracker = tracker; this.startedLatch = startedLatch; } @Override public void run() { TaskExecutionService.TaskGroupExecutionTracker taskGroupExecutionTracker = tracker.taskGroupExecutionTracker; ClassLoader classLoader = executionContexts .get(taskGroupExecutionTracker.taskGroup.getTaskGroupLocation()) .getClassLoader(); ClassLoader oldClassLoader = Thread.currentThread().getContextClassLoader(); Thread.currentThread().setContextClassLoader(classLoader); final Task t = tracker.task; ProgressState result = null; try { startedLatch.countDown(); t.init(); do { result = t.call(); } while (!result.isDone() && isRunning && !taskGroupExecutionTracker.executionCompletedExceptionally()); ... } } Se invoca el método y, de este modo, se ejecutan realmente las tareas de sincronización de datos. Task.call Cargador de clases En SeaTunnel, el ClassLoader predeterminado se ha modificado para priorizar las subclases y evitar conflictos con otras clases de componentes: @Override public synchronized ClassLoader getClassLoader(long jobId, Collection<URL> jars) { log.debug("Get classloader for job {} with jars {}", jobId, jars); if (cacheMode) { // with cache mode, all jobs share the same classloader if the jars are the same jobId = 1L; } if (!classLoaderCache.containsKey(jobId)) { classLoaderCache.put(jobId, new ConcurrentHashMap<>()); classLoaderReferenceCount.put(jobId, new ConcurrentHashMap<>()); } Map<String, ClassLoader> classLoaderMap = classLoaderCache.get(jobId); String key = covertJarsToKey(jars); if (classLoaderMap.containsKey(key)) { classLoaderReferenceCount.get(jobId).get(key).incrementAndGet(); return classLoaderMap.get(key); } else { ClassLoader classLoader = new SeaTunnelChildFirstClassLoader(jars); log.info("Create classloader for job {} with jars {}", jobId, jars); classLoaderMap.put(key, classLoader); classLoaderReferenceCount.get(jobId).put(key, new AtomicInteger(1)); return classLoader; } } Envío de tareas de API REST SeaTunnel también admite el envío de tareas a través de la API REST. Para habilitar esta función, agregue la siguiente configuración al archivo : hazelcast.yaml network: rest-api: enabled: true endpoint-groups: CLUSTER_WRITE: enabled: true DATA: enabled: true Después de agregar esta configuración, el nodo Hazelcast podrá recibir solicitudes HTTP. Al utilizar la API REST para el envío de tareas, el cliente se convierte en el nodo que envía la solicitud HTTP y el servidor es el clúster SeaTunnel. Cuando el servidor recibe la solicitud, llamará al método apropiado según la URI de la solicitud: public void handle(HttpPostCommand httpPostCommand) { String uri = httpPostCommand.getURI(); try { if (uri.startsWith(SUBMIT_JOB_URL)) { handleSubmitJob(httpPostCommand, uri); } else if (uri.startsWith(STOP_JOB_URL)) { handleStopJob(httpPostCommand, uri); } else if (uri.startsWith(ENCRYPT_CONFIG)) { handleEncrypt(httpPostCommand); } else { original.handle(httpPostCommand); } } catch (IllegalArgumentException e) { prepareResponse(SC_400, httpPostCommand, exceptionResponse(e)); } catch (Throwable e) { logger.warning("An error occurred while handling request " + httpPostCommand, e); prepareResponse(SC_500, httpPostCommand, exceptionResponse(e)); } this.textCommandService.sendResponse(httpPostCommand); } El método para manejar la solicitud de envío de trabajo está determinado por la ruta: private void handleSubmitJob(HttpPostCommand httpPostCommand, String uri) throws IllegalArgumentException { Map<String, String> requestParams = new HashMap<>(); RestUtil.buildRequestParams(requestParams, uri); Config config = RestUtil.buildConfig(requestHandle(httpPostCommand), false); ReadonlyConfig envOptions = ReadonlyConfig.fromConfig(config.getConfig("env")); String jobName = envOptions.get(EnvCommonOptions.JOB_NAME); JobConfig jobConfig = new JobConfig(); jobConfig.setName( StringUtils.isEmpty(requestParams.get(RestConstant.JOB_NAME)) ? jobName : requestParams.get(RestConstant.JOB_NAME)); boolean startWithSavePoint = Boolean.parseBoolean(requestParams.get(RestConstant.IS_START_WITH_SAVE_POINT)); String jobIdStr = requestParams.get(RestConstant.JOB_ID); Long finalJobId = StringUtils.isNotBlank(jobIdStr) ? Long.parseLong(jobIdStr) : null; SeaTunnelServer seaTunnelServer = getSeaTunnelServer(); RestJobExecutionEnvironment restJobExecutionEnvironment = new RestJobExecutionEnvironment( seaTunnelServer, jobConfig, config, textCommandService.getNode(), startWithSavePoint, finalJobId); JobImmutableInformation jobImmutableInformation = restJobExecutionEnvironment.build(); long jobId = jobImmutableInformation.getJobId(); if (!seaTunnelServer.isMasterNode()) { NodeEngineUtil.sendOperationToMasterNode( getNode().nodeEngine, new SubmitJobOperation( jobId, getNode().nodeEngine.toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint())) .join(); } else { submitJob(seaTunnelServer, jobImmutableInformation, jobConfig); } this.prepareResponse( httpPostCommand, new JsonObject() .add(RestConstant.JOB_ID, String.valueOf(jobId)) .add(RestConstant.JOB_NAME, jobConfig.getName())); } La lógica aquí es similar a la del lado del cliente. Como no hay un modo local, no es necesario crear un servicio local. En el lado del cliente, la clase se utiliza para el análisis del plan lógico y, de manera similar, la clase realiza las mismas tareas. ClientJobExecutionEnvironment RestJobExecutionEnvironment Al enviar una tarea, si el nodo actual no es el nodo maestro, enviará información al nodo maestro. El nodo maestro manejará el envío de la tarea de manera similar a como maneja los comandos del cliente de línea de comandos. Si el nodo actual es el nodo maestro, llamará directamente al método , que invoca al método para el procesamiento posterior: submitJob coordinatorService.submitJob private void submitJob( SeaTunnelServer seaTunnelServer, JobImmutableInformation jobImmutableInformation, JobConfig jobConfig) { CoordinatorService coordinatorService = seaTunnelServer.getCoordinatorService(); Data data = textCommandService .getNode() .nodeEngine .getSerializationService() .toData(jobImmutableInformation); PassiveCompletableFuture<Void> voidPassiveCompletableFuture = coordinatorService.submitJob( Long.parseLong(jobConfig.getJobContext().getJobId()), data, jobImmutableInformation.isStartWithSavePoint()); voidPassiveCompletableFuture.join(); } Ambos métodos de envío implican el análisis del plan lógico en el lado de envío y luego el envío de la información al nodo maestro. El nodo maestro luego realiza el análisis del plan físico, la asignación y otras operaciones.